DarkNet YOLO 训练自己的数据集
前言
写这篇文章的目的是记录在DarkNet框架下训练自己的数据集的过程,以车牌检测为例。车牌来源于爬虫,预训练模型使用的是官方提供的darknet19_448.conv.23。
本文参考了下面文章:
https://blog.csdn.net/ap1005834/article/details/75425744
https://www.cnblogs.com/qinguoyi/p/8507803.html
https://blog.csdn.net/yikeshiguang/article/details/81080842
数据获取
车牌数据来源于网路爬虫,这里对百度图片进行爬取:
#coding=utf-8
import re
import requests
import sys,os
type = sys.getfilesystemencoding()
def downloadPic(html, keyword, i):
pic_url = re.findall('"objURL":"(.*?)",', html, re.S)
print '找到关键词:'+keyword+'的图片,现在开始下载...'
for each in pic_url:
print u'正在下载第'+str(i+1)+u'张图片,图片地址:'+str(each)
try:
pic = requests.get(each, timeout=50)
except Exception,ex :
print u'错误,当前图片无法下载'
continue
string = 'pictures/'+str(i) + '.jpg'
fp = open(string, 'wb')
fp.write(pic.content)
fp.close()
i += 1
return i
if __name__ == '__main__':
word = raw_input('Input keywords:')
print word
pnMax = input('Input max pn:')
print int(pnMax)
pncont = 0
gsm = 80
str_gsm = str(gsm)
if not os.path.exists('pictures'): # 在当前目录下创建
os.mkdir('pictures')
while pncont < pnMax:
str_pn = str(pncont)
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word='+word+'&pn='+str_pn+'&gsm='+str_gsm+'&ct=&ic=0&lm=-1&width=0&height=0'
result = requests.get(url)
pncont = downloadPic(result.text, word, pncont)
print u'下载完毕'
如果闲麻烦可以使用我收集且标注好的数据,在下面会提供。
数据标注和转换
下载数据后还需要对数据进行标注,这里使用的标注用具是labelImg,使用labelImg每标注一张图片就会生成对应的xml文件。因为yolo训练使用的是VOC数据集,所以需要将标注的xml文件转换为txt文件,使用下面脚本转换:
coding=utf-8
# 将标注的xml转为txt文件,保存到train_txt目录下
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
xml_label_Dir = '/home/hxy/husin/CarPlateDataSet/YOLOV2_carPlate/train_xml/'
txt_label_Dir = '/home/hxy/husin/CarPlateDataSet/YOLOV2_carPlate/train_txt/'
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0]+box[1])/2.0
y = (box[2]+box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
if not os.path.exists(txt_label_Dir):
os.makedirs(txt_label_Dir)
for rootDir,dirs,files in os.walk(xml_label_Dir):
for file in files:
file_name = file.split('.')[0]
out_file = open(txt_label_Dir+'%s.txt'%(file_name),'w')
in_file = open('%s/%s'%(rootDir, file)) ####
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write("0" + " " + " ".join([str(a) for a in bb]) + '\n')
out_file.close()
接下来还需要生成一个train_imgae_path.txt文件,该文件保存了训练图片的绝对路径,使用下面脚本生成该文件:
import os
TrainDir = '/home/hxy/husin/CarPlateDataSet/YOLOV2_carPlate/train'
out_file = open('tarin_image_path.txt', 'w')
for root, dirs, files in os.walk(TrainDir):
for file in files:
out_file.write('%s/%s\n'%(root, file))
out_file.close()
到这里数据处理阶段还没结束,最新版本的YOLO是直接通过替换原图片绝对路径(也就是上面的train_image_path.txt文件中的内容)的后缀名来找到对应标记文件的。比如原图片的绝对路径为/home/hxy/husin/CarPlateDataSet/YOLOV2_carPlate/train/1.png 则YOLO会直接认为其对应的编辑文件路径为/home/hxy/husin/CarPlateDataSet/YOLOV2_carPlate/train/1.txt。所以,我们要把之前生成的txt文件都放到训练图片的同个目录下,即将train_txt下的txt文件放到train文件夹下,像下面这个样子:
车牌数据我已经打包好了:
下载车牌数据
修改配置文件
-
创建names文件
在DarkNet主目录的data文件下,创建一个.names文件,文件名任意,例如myClass.names, 在该文件中写入所有的类别名称,每一类占一行,我只检测车牌,故只有一行licence_plate。 -
修改data文件
修改DarkNet主目录下的cfg/voc.data文件,修改如下:
classes= 1 # 只有一类所以改为1
train = /home/hxy/husin/YOLO/darknet/tarin_image_path.txt # 上面生成的tarin_image_path.txt文件路径
valid = /home/pjreddie/data/voc/2007_test.txt # 验证阶段需要的,训练阶段不是必要的,可以不改
names = data/myClass.names # 上述的myClass.names文件
backup = /home/hxy/husin/YOLO/darknet/backup # 训练出来的网络权重文件保存路径
- 修改cfg文件
修改DarkNet主目录下的cfg/yolov2-voc.cfg文件。
①. [region]层中classes改为1
②. [region]层上方的[convolution]层中的filter值改为30 (classes+coords+1)*NUM。
重新编译DarkNet yolo
进入主目录, make clean 后 make -j8
下载与训练模型文件
为了加快训练速度,下载官方提供的预训练模型,保存至cfg下,下载地址于下:
http://pjreddie.com/media/files/darknet19_448.conv.23
开始训练
在DarkNet主目录下运行命令:
./darknet detector train cfg/voc.data cfg/yolov2-voc.cfg cfg/darknet19_448.conv.23
开始训练,训练过程产生的weights文件将会被保存到/home/hxy/husin/YOLO/darknet/backup中,如果要修改最大迭代次数可以进入cfg/yolov2-voc.cfg修改max_batches的值。
(注意迭代的次数要合适,少了无法收敛,多了会发散)
训练过程输出
Region Avg IOU:平均的IOU,代表预测的bounding box和ground truth的交集与并集之比,期望该值趋近于1。
Class:是标注物体的概率,期望该值趋近于1.
Obj:期望该值趋近于1.
No Obj:期望该值越来越小但不为零.
Avg Recall:期望该值趋近1
avg:平均损失,期望该值趋近于0
rate:当前学习率
测试训练模型
使用下面语句测试单张图片:
./darknet detector test cfg/voc.data cfg/yolov2-voc.cfg backup/yolov2-voc_final.weights 1394.png
结果:

需要注意的坑
- 很多博客中会要求修改src中的yolo.c文件
其实那是早期的版本中训练要求的,darknet不需要。原因是这样的,在官网里有一段执行test的代码是:其实那是早期的版本中训练要求的,darknet不需要。原因是这样的,在官网里有一段执行test的代码是:
./darknet detect cfg/yolo.cfg yolo.weights data/dog.jpg
这是一段简写的执行语句,它完整形式是这样的:
./darknet detector test cfg/coco.data cfg/yolo.cfg yolo.weights data/dog.jpg
其实修改.c文件的作用就是让我们可以使用简写的test执行语句,程序会自动调用.c里面设置号的路径内容。我个人感觉没有必要。
-
如何修改训练迭代次数与.weights文件的保存的关系
训练的时候batch在小于1000次时每100次保存模型,大于1000后每10000次保存一次模型。可以通过修改/examples/detector.c中的train_detector函数来自己决定多少张图保存一次模型。
在detector.c的138行左右
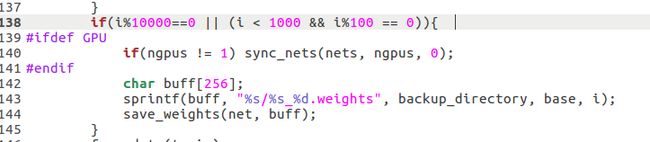
-
假设steps = 10000 , scale = .1 ,那意思就是迭代到10000次时学习率衰减10倍。如果调整max_baches的大小,需要同时调整steps,而scale可以自己决定修不修改。如果不改steps的话很可能导致无法收敛到loss最小值。
-
训练的时候用 ./darknet detector train cfg/voc.data cfg/yolov2-voc.cfg cfg/darknet19_448.conv.23 2>1 | tee person_train.txt 保存训练内容。