[深度学习论文笔记][Attention] Spatial Transformer Networks
1 Motivation
The Show, Attend and Tell only allow attention constrained to fixed grid. We want the model can attend to arbitary part of the image.The pooling operation allows a network to be somewhat spatially invariant to the position of features. However, due to the typically small spatial support for max-pooling, this
spatial invariance is only realised over a deep hierarchy of max-pooling and convolutions, and the intermediate feature maps in a CNN are not actually invariant to large transformations of the input data.
deformations.
2 Spatial Transformers
We want a differentiable module which applies a spatial transformation to a feature map during a single forward pass. For each pixel coordinates .x s , y s /, we compute the corresponding ouput .x t , y t / by
We normalize coordinates x s , y s in range [-1, 1]. This transformation allows cropping, translation, rotation, scale, and skew to be applied to the input feature map.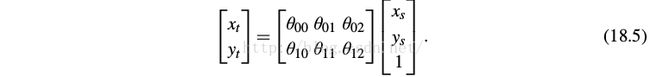
For multi-channel inputs, the same warping is applied to each channel. We repeat for all pixels in output to get a sampling grid, and then use bilinear interpolation to compute
output.
3 Architecture
See Fig. One can also use multiple spatial transformers in parallel — this can be useful if there are multiple objects or parts of interest in a feature map that should be
focussed on individually. A limitation of this architecture in a purely feed-forward network is that the number of parallel spatial transformers limits the number of objects that the
network can model.
![[深度学习论文笔记][Attention] Spatial Transformer Networks_第1张图片](http://img.e-com-net.com/image/info8/93797088e2ee4fec99a957abdd53d0a1.jpg)
4 Training Details
For training, we initialize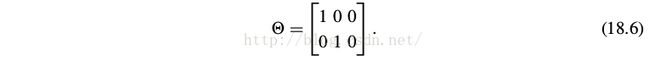
This allows the output to be the same as input.
5 Results
See Fig. We insert spatial transformers into a classification network and it learns to attend and transform the input.
6 References
[1]. https://www.youtube.com/watch?v=Ywv0Xi2-14Y.
[2]. https://www.youtube.com/watch?v=T5k0GnBmZVI.
![[深度学习论文笔记][Attention] Spatial Transformer Networks_第2张图片](http://img.e-com-net.com/image/info8/520529b24ba64c40ab1e67c48b015926.jpg)