Python数据结构与算法分析学习记录(2)——基于Problem Solving with Algorithms and Data Structures using Python的学习
2.1.目标
- 了解为何算法分析的重要性
- 能够用大“O”表示法来描述算法执行时间
- 了解在 Python 列表和字典类型中通用操作用大“O”表示法表示的执行时间
- 了解 Python 数据类型的具体实现对算法分析的影响
- 了解如何对简单的 Python 程序进行执行时间检测
2.2.什么是算法分析
算法分析主要就是从计算资源的消耗的角度来评判和比较算法。我们想要分析两种算法并且指出哪种更好,主要考虑的是哪一种可以更高效地利用计算资源。或者占用更少的资源。
从这点上看,思考我们通过计算资源这个概念真正想表达的是什么是非常重要的。有两种方法来看待它。一种是考虑算法解决问题过程中需要的存储空间或内存。
作为空间需求的一个可替代物,我们可以用算法执行所需时间来分析和比较算法。这种方法有时被称为算法的“执行时间”或“运行时间”。
在 Python 中,我们可以考虑我们使用的系统通过标定开始时间和结束时间来作为标准衡量一个函数。在 time 模块有一个叫 time 的函数,它能返回在某些任意起点以秒为单位的系统当前时间。通过在开始和结束时两次调用这个函数,然后计算两次时间之差,我们就可以得到精确到秒(大多数情况为分数)的运行时间。
直观上,我们可以看到迭代算法似乎做了更多的工作,因为一些程序步骤被重复执行,这可能就是它需要更长时间的原因。此外,迭代算法所需要的运行时间似乎会随着 n 值的增大而增大。
2.3 大“O”表示法
如果把每一小步看作一个基本计量单位,那么一个算法的执行时间就可以表达为它解决一个问题所需的步骤数。
数量级函数用来描述当规模 n 增加时,T(n)函数中增长最快的部分。这种数量级函数一般被称为大“O”表示法,记作 O(f(n))。它提供了计算过程中实际步数的近似值。函数 f(n)是原始函数 T(n)中主导部分的简化表示。
尽管前面求和函数的例子没有体现,但我们还是注意到有时算法的运行时间还取决于具体数据而不仅仅是问题规模。对于这种算法,我们把它们的执行情况分为最好的情况,最坏的情况和平均情况。某个特定的数据集会使算法程序执行情况极差,这就是最坏的情况。然而另一个不同的数据集却能使这个算法程序执行情况极佳。不过,大多数情况下,算法程序的执行情况都介于这两种极端情况之间,也就是平均情况。
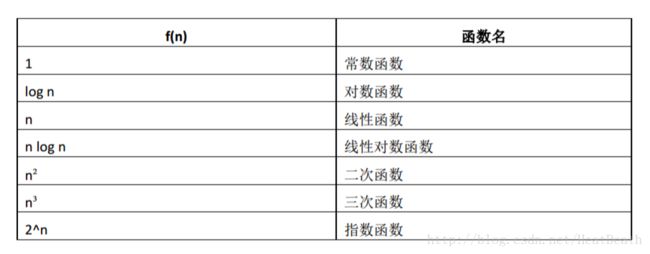
常见函数的大“O”表示法:

小试牛刀
编写两个 Python 函数来寻找一个列表中的最小值。函数一将列表中的每个数都与其他数作比较,数量级是 O(n²).函数二的数量级是 O(n)。
import time
from random import randrange
alist = []
def find_min(alist):
#假设alist中的第一个数字最小
my_min = alist[0]
#遍历alist
for i in alist:
#最小标记flag指示i是否为alist最小,初始为True
flag = True
#遍历alist
for j in alist:
#如果i>j(存在比i小的数)
if i >j:
#标记flag为false
flag = False
#当i为alist最小,my_min=i
if flag:
my_min = i
return my_min
def findMin(alist):
#初始化当前最小值minsofar=alist[0]
minsofar = alist[0]
#遍历alist
for i in alist:
#如果i小于minsofar
if i < minsofar:
minsofar = i
return minsofar
#当list长度为100,000的时候,算法一等了1分多钟没算出来...
#当list长度为100,000*100的时候,算法二只要0.2s...
#当list长度为100,000*1000的时候,算法二python占用了3.2Gb内存,CPU占用30%,等了半分钟,也算不出来了...
listSize = 100000000
'''
alist = [randrange(10000000) for i in range(listSize)]
start = time.time()
print(find_min(alist))
end = time.time()
print('验证:%d'%min(alist))
print("listlength:{0},time:{1},O(n)=n^2".format(listSize,end-start))
print('---------------------------------------------------------------')
'''
alist = [randrange(10000000) for i in range(listSize)]
start = time.time()
print(findMin(alist))
end = time.time()
print('验证:%d'%min(alist))
print("listlength:%d,time:%.30f,O(n)=n"% (listSize,end-start))
print('-------------------ENDENDENDENDENDENDEND-------------------------')
2.4.一个乱序字符串检查的例子
显示不同量级的算法的一个很好的例子是字符串的乱序检查。乱序字符串是指一个字符串只是另一个字符串的重新排列。
为了简单起见,我们假设所讨论的两个字符串具有相等的长度,并且他们由 26 个小写字母集合组成。我们的目标是写一个布尔函数,它将两个字符串做参数并返回它们是不是乱序。
2.4.1.解法1:检查
乱序字符串问题的第一种解法是检查第一个字符串中的所有字符是不是都在第二个字符串中出现。如果能够把每一个字符都“检查标记”一遍,那么这两个字符串就互为乱序字符串。检查标记一个字符要用特定值 None 来代替,作为标记。然而,由于字符串不可变,首先要把第二个字符串转化成一个列表。第一个字符串中的每一个字符都可以在列表的字符中去检查,如果找到,就用 None 代替以示标记。
def anagramSolution1(s1,s2):
#将字符串s2转换为一个list
alist = list(s2)
#初始化s1的指针pos1=0
pos1 = 0
#是否在s2字符串中找到s1字符串中的【所有字符】的标记stillOK
stillOK = True
#当指针pos1还未移动到s1结尾,且在遍历s2时能找到s1中的字符
while pos1 < len(s1) and stillOK:
#初始化s2的指针pos2=0
pos2 = 0
#是否在s2字符串中找到s1字符串中的【单个字符】的标记found
found = False
while pos2 < len(alist) and not found:
#如果在遍历s2字符串的时候找到了s1中的字符,则found=true
if s1[pos1] == alist[pos2]:
found = True
else:
pos2 = pos2 + 1
#如果找到,将在s2中找到且存在于s1中的字符时,将s2中的字符变为None
if found:
alist[pos2] = None
#如果没找到,stillOK=false
else:
stillOK = False
#s1中的位置指针pos1移动到下一个位置
pos1 = pos1 + 1
return stillOK
print(anagramSolution1('abcd','acfdffffb'))为了分析这个算法,我们要注意到 s1 中 n 个字符的每一个都会引起一个最多迭代到 s2 列表中第n 个字符的循环。(考虑最坏的情况)列表中的 n 个位置各会被寻找一次去匹配 s1 中的某个字符,那么执行总数就是从 1 到 n 的代数和。我们之前提到过它可以这样表示:

当 n 变大,n^2 这项占据主导,1/2 可以忽略。所以这个算法复杂度为 O(n^2 )。
2.4.2.解法2:排序和比较
另一个解决方案是利用这么一个事实:即使 s1,s2 不同,它们都是由完全相同的字符组成的。所以,我们按照字母顺序从 a 到 z 排列每个字符串,如果两个字符串相同,那这两个字符串就是乱序字符串。
def anagramSolution2(s1,s2):
alist1 = list(s1)
alist2 = list(s2)
alist1.sort()
alist2.sort()
pos = 0
matches = True
while pos < len(s1) and matches:
if alist1[pos]==alist2[pos]:
pos = pos + 1
else:
matches = False
return matches
print(anagramSolution2('abcde','edcba'))首先你可能认为这个算法是 O(n),因为只有一个简单的迭代来比较排序后的 n 个字符。但是,调用 Python 排序不是没有成本。正如我们将在后面的章节中看到的,排序通常是 O(n^2) 或 O(nlogn)。所以排序操作比迭代花费更多。最终,这个算法和排序的复杂度相同。
2.4.3.解法3: 穷举法
解决这类问题的强力方法是穷举所有可能性。
对于乱序检测,我们可以生成 s1 的所有乱序字符串列表,然后查看是不是有 s2。这种方法有一点困难。当 s1 生成所有可能的字符串时,第一个位置有 n 种可能,第二个位置有 n-1 种,第三个位置有 n-3 种,等等。总数为 n∗(n−1)∗(n−2)∗…∗3∗2∗1n∗(n−1)∗(n−2)∗…∗3∗2∗1, 即 n!。虽然一些字符串可能是重复的,程序也不可能提前知道这样,所以他仍然会生成 n! 个字符串。
事实证明,n! 比 n^2 增长还快,事实上,如果 s1 有 20个字符长,则将有 20! = 2,432,902,008,176,640,000 个字符串产生。如果我们每秒处理一种可能字符串,那么需要 77,146,816,596 年才能过完整个列表。所以这不是很好的解决方案。
2.4.4.解法4: 计数和比较
我们最终的解决方法是利用两个乱序字符串具有相同数目的 a, b, c 等字符的事实。我们首先计算的是每个字母出现的次数。由于有 26 个可能的字符,我们就用 一个长度为 26 的列表,每个可能的字符占一个位置。每次看到一个特定的字符,就增加该位置的计数器。最后如果两个列表的计数器一样,则字符串为乱序字符串。
def anagramSolution4(s1,s2):
c1 = [0]*26
c2 = [0]*26
#ord()返回字符的unicode编码
#有点类似于桶排序,用空间换时间
#把26个字母全部丢进桶里,分别比较26个桶里的小球的数量
for i in range(len(s1)):
pos = ord(s1[i])-ord('a')
c1[pos] = c1[pos] + 1
for i in range(len(s2)):
pos = ord(s2[i])-ord('a')
c2[pos] = c2[pos] + 1
j = 0
stillOK = True
while j<26 and stillOK:
if c1[j]==c2[j]:
j = j + 1
else:
stillOK = False
return stillOK
print(anagramSolution4('apple','pleap'))同样,这个方案有多个迭代,但是和第一个解法不一样,它不是嵌套的。两个迭代都是 n, 第三个迭代,比较两个计数列表,需要 26 步,因为有 26 个字母。一共 T(n)=2n+26T(n)=2n+26,即 O(n),我们找到了一个线性量级的算法解决这个问题。
在结束这个例子之前,我们来讨论下空间花费,虽然最后一个方案在线性时间执行,但它需要额外的存储来保存两个字符计数列表。换句话说,该算法牺牲了空间以获得时间。
很多情况下,你需要在空间和时间之间做出权衡。这种情况下,额外空间不重要,但是如果有数百万个字符,就需要关注下。作为一个计算机科学家,当给定一个特定的算法,将由你决定如何使用计算资源。

2.5.Python数据结构的性能
现在你对 大O 算法和不同函数之间的差异有了了解。本节的目标是告诉你 Python 列表和字典操作的 大O 性能。然后我们将做一些基于时间的实验来说明每个数据结构的花销和使用这些数据结构的好处。重要的是了解这些数据结构的效率,因为它们是本书实现其他数据结构所用到的基础模块。本节中,我们将不会说明为什么是这个性能。在后面的章节中,你将看到列表和字典一些可能的实现,以及性能是如何取决于实现的。
2.6.列表
python 的设计者在实现列表数据结构的时候有很多选择。每一个这种选择都可能影响列表操作的性能。为了帮助他们做出正确的选择,他们查看了最常使用列表数据结构的方式,并且优化了实现,以便使得最常见的操作非常快。当然,他们还试图使较不常见的操作快速,但是当需要做出折衷时,较不常见的操作的性能通常牺牲以支持更常见的操作。
两个常见的操作是【索引】和【分配到索引位置】。无论列表有多大,这两个操作都需要相同的时间。当这样的操作和列表的大小无关时,它们是 【O(1)】。
另一个非常常见的编程任务是增加一个列表。有两种方法可以创建更长的列表,可以使用 append 方法或拼接运算符。append 方法是 O(1)。 然而,拼接运算符是 O(k),其中 k 是要拼接的列表的大小。这对你来说很重要,因为它可以帮助你通过选择合适的工具来提高你自己的程序的效率。
让我们看看四种不同的方式,我们可以生成一个从0开始的n个数字的列表。首先,我们将尝试一个 for 循环并通过创建列表,然后我们将使用 append 而不是拼接。接下来,我们使用列表生成器创建列表,最后,也是最明显的方式,通过调用列表构造函数包装 range 函数。
def test1():
l = []
for i in range(1000):
l = l + [i]
def test2():
l = []
for i in range(1000):
l.append(i)
def test3():
l = [i for i in range(1000)]
def test4():
l = list(range(1000))要捕获我们的每个函数执行所需的时间,我们将使用 Python 的 timeit 模块。timeit 模块旨在允许 Python 开发人员通过在一致的环境中运行函数并使用尽可能相似的操作系统的时序机制来进行跨平台时序测量。
要使用 timeit,你需要创建一个 Timer 对象,其参数是两个 Python 语句。
timeit.Timer()第一个参数是一个你想要执行时间的 Python 语句; 第二个参数是一个将运行一次以设置测试的语句。然后 timeit 模块将计算执行语句所需的时间。默认情况下,timeit 将尝试运行语句一百万次。 当它完成时,它返回时间作为表示总秒数的浮点值。由于它执行语句一百万次,可以读取结果作为执行测试一次的微秒数。你还可以传递 timeit 一个参数名字为 number,允许你指定执行测试语句的次数。以下显示了运行我们的每个测试功能 1000 次需要多长时间。
from timeit import Timer
def test1():
l = []
for i in range(1000):
l = l + [i]
def test2():
l = []
for i in range(1000):
l.append(i)
def test3():
l = [i for i in range(1000)]
def test4():
l = list(range(1000))
t1 = Timer("test1()", "from __main__ import test1")
print("1.采用拼接方式 :",t1.timeit(number=1000), "milliseconds")
t2 = Timer("test2()", "from __main__ import test2")
print("2.采用append()方法 :",t2.timeit(number=1000), "milliseconds")
t3 = Timer("test3()", "from __main__ import test3")
print("3.采用列表生成器创建列表 :",t3.timeit(number=1000), "milliseconds")
t4 = Timer("test4()", "from __main__ import test4")
print("4.调用列表构造函数包装range():",t4.timeit(number=1000), "milliseconds")1.采用拼接方式 : 1.4775958992284661 milliseconds
2.采用append()方法 : 0.07474729405968761 milliseconds
3.采用列表生成器创建列表 : 0.03142988894721266 milliseconds
4.调用列表构造函数包装range(): 0.012871361166420847 milliseconds在上面的例子中,我们对 test1(), test2() 等的函数调用计时,setup 语句可能看起来很奇怪,所以我们详细说明下。你可能非常熟悉 from ,import 语句,但这通常用在 python 程序文件的开头。在这种情况下,from __main__ import test1 从 __main__命名空间导入到 timeit 设置的命名空间中。timeit 这么做是因为它想在一个干净的环境中做测试,而不会因为可能有你创建的任何杂变量,以一种不可预见的方式干扰你函数的性能。
从上面的试验清楚的看出,append 操作比拼接快得多。其他两种方法,列表生成器的速度是 append 的两倍。
最后一点,你上面看到的时间都是包括实际调用函数的一些开销,但我们可以假设函数调用开销在四种情况下是相同的,所以我们仍然得到的是有意义的比较。因此,拼接字符串操作需要 6.54 毫秒并不准确,而是拼接字符串这个函数需要 6.54 毫秒。你可以测试调用空函数所需要的时间,并从上面的数字中减去它。
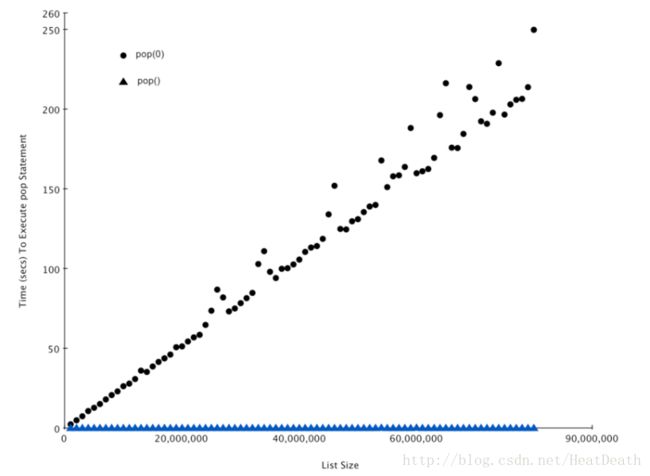
现在我们已经看到了如何具体测试性能,见 Table2, 你可能想知道 pop 两个不同的时间。当列表末尾调用 pop 时,它需要 O(1), 但是当在列表中第一个元素或者中间任何地方调用 pop, 它是 O(n)。原因在于 Python 实现列表的方式,当一个项从列表前面取出,列表中的其他元素靠近起始位置移动一个位置。你会看到索引操作为 O(1)。python的实现者会权衡选择一个好的方案。

作为一种演示性能差异的方法,我们用 timeit 来做一个实验。我们的目标是验证从列表从末尾 pop 元素和从开始 pop 元素的性能。同样,我们也想测量不同列表大小对这个时间的影响。我们期望看到的是,从列表末尾处弹出所需时间将保持不变,即使列表不断增长。而从列表开始处弹出元素时间将随列表增长而增加。
Listing 4 展示了两种 pop 方式的比较。从第一个示例看出,从末尾弹出需要 0.0003 毫秒。从开始弹出要花费 4.82 毫秒。对于一个 200 万的元素列表,相差 16000 倍。
Listing 4 需要注意的几点,第一, from __main__ import x, 虽然我们没有定义一个函数,我们确实希望能够在我们的测试中使用列表对象 x, 这种方法允许我们只计算单个弹出语句,获得该操作最精确的测量时间。
from timeit import Timer
popzero = Timer("x.pop(0)",
"from __main__ import x")
popend = Timer("x.pop()",
"from __main__ import x")
x = list(range(2000000))
print('从列表头部pop元素:',popzero.timeit(number=1000))
x = list(range(2000000))
print('从列表尾部pop元素:',popend.timeit(number=1000))
虽然我们第一个测试显示 pop(0) 比 pop() 慢, 但它没有证明 pop(0) 是 O(n), pop()是 O(1)。要验证它,我们需要看下一系列列表大小的调用效果。
from timeit import Timer
popzero = Timer("x.pop(0)",
"from __main__ import x")
popend = Timer("x.pop()",
"from __main__ import x")
print("pop(0) pop()")
for i in range(1000000,100000001,1000000):
x = list(range(i))
pt = popend.timeit(number=1000)
x = list(range(i))
pz = popzero.timeit(number=1000)
print("%15.5f, %15.5f" %(pz,pt)) pop(0) pop()
1.02129, 0.00010
1.97078, 0.00009
2.94145, 0.00009
3.86029, 0.00017
4.81222, 0.00009
5.72757, 0.00013
6.73877, 0.00013
7.73894, 0.00015
8.58310, 0.00012
9.63673, 0.00014
11.01678, 0.00011
12.07815, 0.00014
14.63703, 0.00011
14.82728, 0.00023
15.10135, 0.00013Figure 3 展示了我们实验的结果,你可以看到,随着列表变长,pop(0) 时间也增加,而 pop() 时间保持非常平坦。这正是我们期望看到的 O(n)和 O(1)
2.7.字典
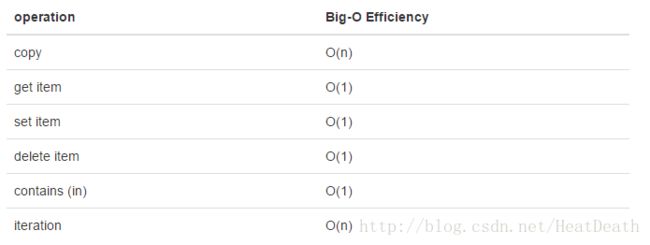
python 中第二个主要的数据结构是字典。你可能记得,字典和列表不同,你可以通过键而不是位置来访问字典中的项目。在本书的后面,你会看到有很多方法来实现字典。字典的 get 和 set 操作都是 O(1)。另一个重要的操作是 contains,检查一个键是否在字典中也是 O(1)。所有字典操作的效率总结在 Table3 中。关于字典性能的一个重要方面是,我们在表中提供的效率是针对平均性能。 在一些罕见的情况下,contains,get item 和 set item 操作可以退化为 O(n)。我们将在后面的章节介绍。
我们会在最后的实验中,将比较列表和字典之间的 contains 操作的性能。在此过程中,我们将确认列表的 contains 操作符是 O(n),字典的 contains 操作符是 O(1)。我们将在实验中列出一系列数字。然后随机选择数字,并检查数字是否在列表中。如果我们的性能表是正确的,列表越大,确定列表中是否包含任意一个数字应该花费的时间越长。
Listing 6 实现了这个比较。注意,我们对容器中的数字执行完全相同的操作。区别在于在第 7 行上 x 是一个列表,第9行上的 x 是一个字典。
import timeit
import random
for i in range(10000,1000001,20000):
t = timeit.Timer("random.randrange(%d) in x"%i,"from __main__ import random,x")
x = list(range(i))
lst_time = t.timeit(number=1000)
x={j:None for j in range(i)}
d_time = t.timeit(number=1000)
print("%d,%10.3f,%10.3f "%(i,lst_time,d_time))Size list dict
10000, 0.062, 0.001
30000, 0.178, 0.001
50000, 0.422, 0.001
70000, 0.453, 0.001
90000, 0.553, 0.001
110000, 0.700, 0.001
130000, 0.783, 0.001
150000, 0.931, 0.001
170000, 1.070, 0.001
190000, 1.201, 0.001
210000, 1.337, 0.001
230000, 1.524, 0.001
250000, 1.574, 0.001
270000, 1.715, 0.001
290000, 1.828, 0.001
310000, 1.973, 0.001
330000, 1.997, 0.001
350000, 2.191, 0.001
370000, 2.299, 0.001
390000, 2.457, 0.001
410000, 2.509, 0.001
430000, 2.639, 0.001
450000, 2.835, 0.001
470000, 2.920, 0.001
490000, 3.042, 0.001
510000, 3.228, 0.001
530000, 3.262, 0.001
550000, 3.376, 0.001
570000, 3.691, 0.002
590000, 3.652, 0.001
610000, 3.778, 0.001
630000, 3.938, 0.001
650000, 3.958, 0.001
670000, 4.147, 0.001
690000, 4.259, 0.001
710000, 4.523, 0.001
730000, 4.715, 0.001
750000, 4.715, 0.001
770000, 5.259, 0.001
790000, 4.965, 0.001
810000, 5.264, 0.001
830000, 5.171, 0.001
850000, 5.489, 0.001
870000, 5.379, 0.002
890000, 5.482, 0.001
910000, 5.540, 0.001
930000, 5.700, 0.001
950000, 5.936, 0.001
970000, 6.067, 0.001
990000, 6.249, 0.001 Figure 4 展示了 Listing6 的结果。你可以看到字典一直更快。 对于最小的列表大小为10,000个元素,字典是列表的89.4倍。对于最大的列表大小为990,000 个元素。字典是列表的11,603倍!你还可以看到列表上的contains运算符所花费的时间与列表的大小成线性增长。这验证了列表上的contains运算符是 O(n) 的断言。还可以看出,字典中的 contains 运算符的时间是恒定的,即使字典大小不断增长。事实上,对于字典大小为10,000个元素,contains操作占用0.004毫秒,对于字典大小为990,000个元素,它也占用0.004毫秒。

2.8.总结
- 算法分析是一种独立的测量算法的方法。
- 大O表示法允许根据问题的大小,通过其主要部分来对算法进行分类。
2.10. Discussion Questions
- Give the Big-O performance of the following code fragment:
for i in range(n):
for j in range(n):
k = 2 + 2O(n^2)
- Give the Big-O performance of the following code fragment:
for i in range(n):
k = 2 + 2O(n)
- Give the Big-O performance of the following code fragment:
i = n
while i > 0:
k = 2 + 2
i = i // 2O(logn)
- Give the Big-O performance of the following code fragment:
for i in range(n):
for j in range(n):
for k in range(n):
k = 2 + 2O(n^3)
- Give the Big-O performance of the following code fragment:
i = n
while i > 0:
k = 2 + 2
i = i // 2O(logn)
- Give the Big-O performance of the following code fragment:
for i in range(n):
k = 2 + 2
for j in range(n):
k = 2 + 2
for k in range(n):
k = 2 + 2O(n)
2.11. Programming Exercises
- Devise an experiment to verify that the list index operator is O(1)
from timeit import Timer
import random
for i in range(10000,1000001,20000):
t = Timer("x[random.randrange(%d)]"%i,"from __main__ import random,x")
x=list(range(i))
print("%10.4f"%t.timeit(number=1000))
运行时间
0.0009
0.0010
0.0009
0.0010
0.0010
0.0009
0.0009
0.0010
0.0010
0.0010
0.0010
0.0010
0.0011
0.0011
0.0011
0.0010
0.0010
0.0012
0.0010
0.0010
0.0025
0.0014
0.0010
0.0010
0.0013- Devise an experiment to verify that get item and set item are
O(1) for dictionaries.
import timeit
import random
for i in range(10000,1000001,20000):
t = timeit.Timer("x.get(random.randrange(%d))"%i,"from __main__ import random,x")
x={j:j+1 for j in range(i)}
d_time = t.timeit(number=1000)
print("%d,%10.4f "%(i,d_time))import timeit
import random
for i in range(10000,1000001,20000):
t = timeit.Timer("x.setdefault(random.randrange(%d))"%i,"from __main__ import random,x")
x={j:j+1 for j in range(i)}
d_time = t.timeit(number=1000)
print("%d,%10.4f "%(i,d_time))10000, 0.0011
30000, 0.0010
50000, 0.0011
70000, 0.0012
90000, 0.0011
110000, 0.0011
130000, 0.0011
150000, 0.0014
170000, 0.0014
190000, 0.0013
210000, 0.0012
230000, 0.0017
250000, 0.0012
270000, 0.0013
290000, 0.0013
310000, 0.0013
330000, 0.0012
350000, 0.0013
370000, 0.0015
390000, 0.0012
410000, 0.0022
430000, 0.0013 - Devise an experiment that compares the performance of the del operator on lists and dictionaries.
没看明白这个del到底是咋用的,看了Python文档也没看明白,不搞了不搞了
- Given a list of numbers in random order, write an algorithm that works in O(nlog(n)) to find the kth smallest number in the list.
这是让我写个快速排序嘛…
- Can you improve the algorithm from the previous problem to be linear?
Explain.
桶排序?!