解密Deepfake(深度换脸)-基于自编码器的(Pytorch代码)
前言
还记得在2018月3月份火爆reddit的deepfake吗?将视频中的头换成另一个人的头像,虽然可能有些粗糙和模糊,但是在分辨率不要求很高的情况下可以达到以假乱真的效果。
举个栗子,如下图中将希拉里换成特朗普的一段演讲视频。

另外还有实现川普和尼古拉脸相换:
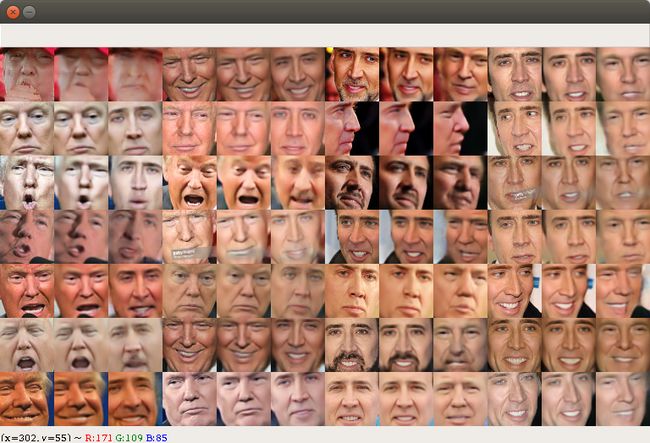
当然这只是DeepFake的冰山一角,Deepfake当初火起来的原因可以说是广大拥有宅男心态的程序员们一起奋斗的结果。那就是,呃,可以将你想要的某张脸换到AV中去。当然这里就不进行演示了,并且相关的reddit论坛已经被禁止。所以这里就不多进行讨论啦。
本文为 https://github.com/Oldpan/Faceswap-Deepfake-Pytorch 代码的搭配教程(填一下之前埋得坑),这里简单对此进行讲解下,填补一下之前的空缺。
相关研究
其实有关深度学习的换脸相关的研究已经很普及了,有基于GAN的也有基于Glow的,但本质上都是生成模型,只是换了一种实现方式,而这个DeepFake呢,使用的是机器学习中的自编码器,拥有与神经网络类似的结构,鲁棒性较好,我们可以通过学习它来对生成网络有一个大概的了解,这样之后碰到相似的网络或者构造就好上手了。
技术讲解
人脸互换是计算机视觉领域中一个比较热门的应用,人脸互换一般可以用于视频合成、提供隐私服务、肖像更换或者其他有创新性的应用。最早之前,实现人脸互换是通过分别分析两者人脸的相似信息来实现换脸,也就是通过特征点匹配来提取一张脸中例如眉毛、眼睛等特征信息然后匹配到另一张人脸上。这种实现不需要进行训练,不需要的数据集,但是实现的比较差,无法自己修改人脸中的表情。
而在最近发展的深度学习技术中,我们可以通过深度神经网络提取输入图像的深层信息,从而读取出其中隐含的深层特征来实现一些新奇的任务,比如风格迁移(style transfer)就是通过读取训练好的模型提取图像中的深层信息来实现风格互换。
也有使用神经网络进行人脸互换(face-swap),其中使用VGG网络来进行特征提取并实现人脸互换。这里我们通过特殊的自编码器结构来实现人脸互换,并且达到不错的效果。
基础背景:自编码器
自编码器类似于神经网络,可以说是神经网络的一种,经过训练后能够尝试将输入复制到输出。自编码器和神经网络一样,有着隐含层 h h h,可以将输入解析成编码序列,从而复现输入。自编码器内部有一个函数 h = f ( x ) h=f(x) h=f(x)可以进行编码,同时也有一个函数 r = g ( h ) r=g(h) r=g(h)实现解码,如下图所示。
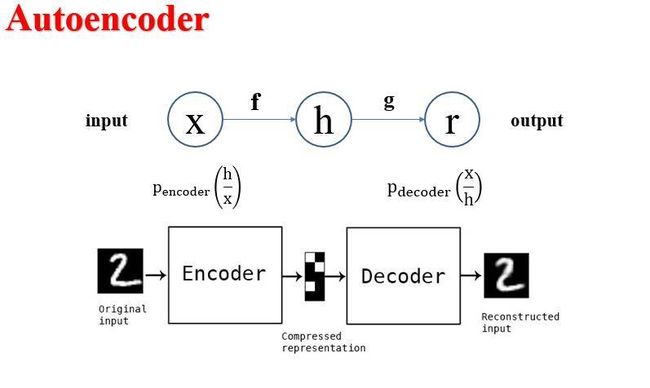
(自编码器的结构,x为输入,f为编码函数,将x编码为隐含特征变量h,而g为解码网络,通过将隐变量h进行重构得到输出结果r,我们也可以看到数字2被放入编码器之后得到其隐含层的编码也就是Compressed representation,之后通过解码器重新生成出来)
现代的自编码器从宏观上也可以理解为随机映射 P e n c o d e r ( h / x ) P_{encoder}(h/x) Pencoder(h/x)和 P d e c o d e r ( x / h ) P_{decoder}(x/h) Pdecoder(x/h)。之前自编码器一般用于数据降维或者图像去噪。但是近年来由于神经网络的发展,更多的潜变量被研究,自编码器也被带到了生成式建模的前沿,可以用于图像生成等方面。
关于更多自编码器的知识:理解深度学习:与神经网络相似的网络-自编码器(上)
网络构架
那么应该如何通过自编码器实现我们的换脸技术呢?
在之前我们已经知道了自编码器可以学习输入图像的信息从而对输入图像信息进行编码并将编码信息存到隐含层中,而解码器则利用学习到的隐含层的信息重新生成之前输入的图像,但是如果我们直接将两个不同个体图像集的图像输入到自编码器当中会发生什么呢?

如上图,假如我们仅仅是简单地将两张不同的脸的集合扔到自编码网络中,然后挑选一个损失函数去训练,但这样去训练我们是什么也得不到的,因此我们需要重新设计一下我们的网络。
怎么设计呢?
既然我们想要将两张脸互换,那么我们可以设计两个不同的解码网络,也就是使用一个编码网络去学习两张不同人脸的共同特征,而使用两个解码器去分别生成他们。
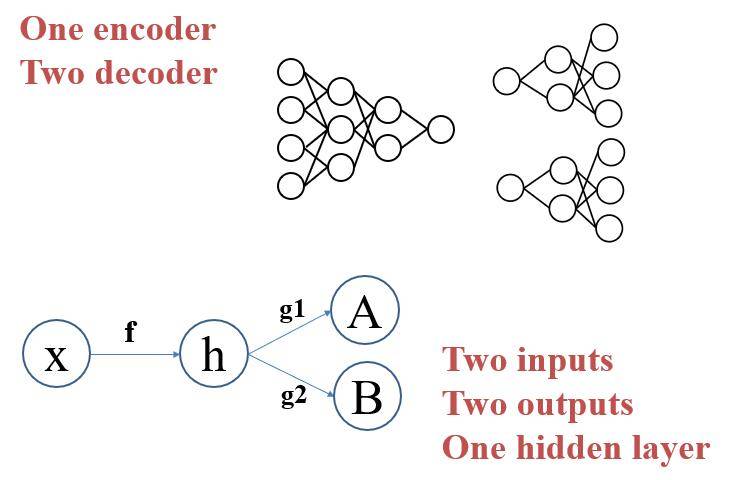
如上图,也就是我们设计一个输入端或者说一个编码器(分别输入两个不同的脸),然后两个输出端或者说两个解码器,这样我们就可以通过隐含层来分别生成两张不同的人脸了。
具体构架
这样如此的话,我们的具体构架如下:

如上图,可以看到这个自编码器有一个input端而有两个output端,在input端分别输入两个不同的人脸集(尼古拉和川普),然后在输出端再重新生成之前的人脸,注意,这里的每个解码器分别负责生成不同个体的脸。而在隐含层则学习到了两个不同个体的共同信息,从而两个不同的解码器可以根据学习到的共同信息去还原之前输入的图像。
再具体点就是这样:
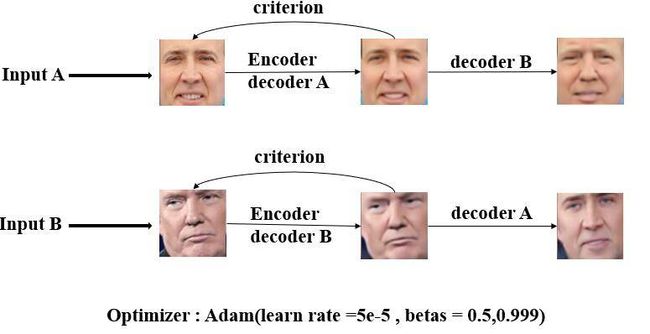
如上图,我们将两个不同个体的图像集分别进行进行输入,此时的Encoder是同一个编码器,随后将使用同一个Encoder生成的共同的隐含信息。再利用两个不同个体图像的解码器A、B重新生成各自的图像进行损失标准(criterion)进行比较(这里损失采用L1损失函数),通过Adam优化算法进行梯度下降。
之后我们利用解码器A、B分别去重新生成由输入图像B、A后隐含层学习到的信息,如下公式:
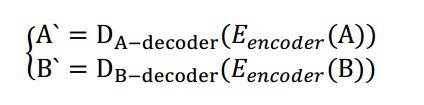
网络结构
下面则是之前提到的结构的具体的网络设计,我们可以看到网络结构有一个输入端和两个输出端,输入端由卷积层和全连接层构成,而输出端则同样由卷积层构成,但是需要注意这里的输入端是下采样卷积,而输出端则是上采样卷积,也就是图像的分辨率是先变低再慢慢升高。
可以看下Pytorch中网络设计的代码:
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential( # 编码网络
_ConvLayer(3, 128), # 3 64 64
_ConvLayer(128, 256), # 32/2=16
_ConvLayer(256, 512), # 16/2=8
_ConvLayer(512, 1024), # 8/2=4
Flatten(),
nn.Linear(1024 * 4 * 4, 1024),
nn.Linear(1024, 1024 * 4 * 4),
Reshape(),
_UpScale(1024, 512),
)
self.decoder_A = nn.Sequential( # 解码网络
_UpScale(512, 256),
_UpScale(256, 128),
_UpScale(128, 64),
Conv2d(64, 3, kernel_size=5, padding=1),
nn.Sigmoid(),
)
self.decoder_B = nn.Sequential(
_UpScale(512, 256),
_UpScale(256, 128),
_UpScale(128, 64),
Conv2d(64, 3, kernel_size=5, padding=1),
nn.Sigmoid(),
)
def forward(self, x, select='A'):
if select == 'A':
out = self.encoder(x)
out = self.decoder_A(out)
else:
out = self.encoder(x)
out = self.decoder_B(out)
return out
上述代码网络可以由下图的图例所表示:
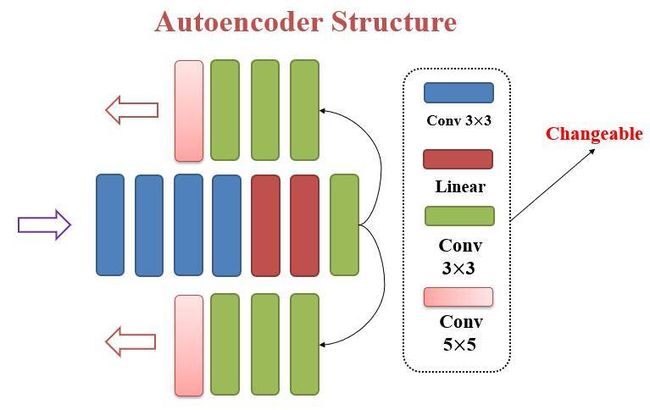
但是这些结构都是可以变化的,其中卷积核的大小可以按照需求调整,而全连接这种可以打乱空间结构的网络我们也可以寻找类似的结构去代替。另外,在解码器阶段的最后一层还采用了Sub-pixel的上采样卷积技术(在本博客的 一边Upsample一边Convolve:Efficient Sub-pixel-convolutional-layers详解 一文中有对此技术的详细讲解)可以快速并且较好地生成图像的细节。
总之,我们想实现换脸的操作,在整体结构不变的基础上,需要满足以下几点:
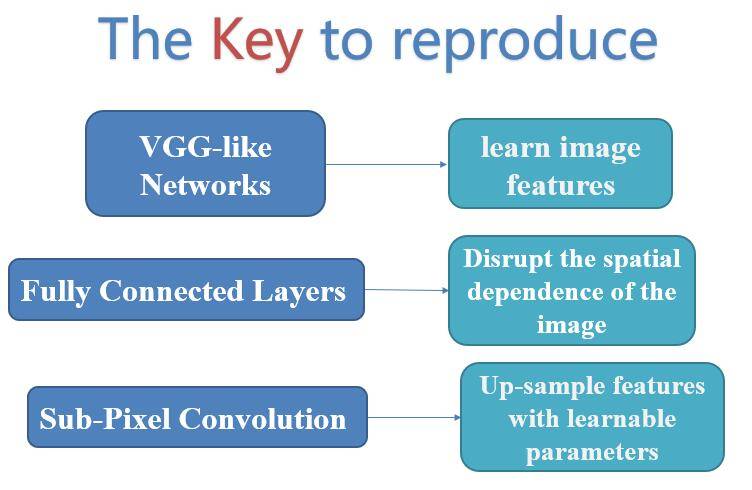
如上图,也就是类似于VGG的编码网络、还要可以打乱空间结构结构的全连接网络、以及可以快速且较好地上采样图像的Sub-Pixel网络。我们进行了额外的测试,发现作为编码网络的话,传统的VGG形式的网络结构的效果最好,可以使损失函数降到最低。但是如果采用其他较为先进的网络,其效果并没有传统的VGG构架好,这也是为什么风格迁移和图像生成使用VGG网络格式更多一些。
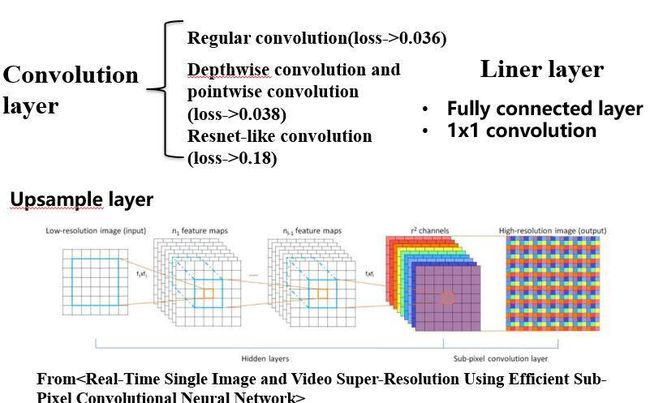
同样,如果我们将全连接网络从编码器中去掉或者使用卷积网络代替,那么图像是无法正常生成的,也就是编码器学习不到任何有用的知识,但是我们可以使用1x1的卷积网络去代替全连接网络,1x1网络如:
nn.Conv2d(1024, 128, 1, 1, 0, bias=False),
nn.Conv2d(128, 1024, 1, 1, 0, bias=False),
同样也拥有打乱空间结构的特性,优点是比全连接网络运行更快,但是效果并没有全连接网络好。
至此,我们简单说明了基本构架以及网络层的选择。
图像预处理
当然训练的时候是有很多小技巧的,因为我们需要隐含层学习到两个不同个体的共同特征,我们可以采取一些小Tricks来让我们的训练过程更快更平滑,类似于之前谈到的 浅谈深度学习训练中数据规范化(Normalization)的重要性 ,我们要做的就是使训练的图像的分布信息尽可能相近:

如上图,我们可以将图像A(川普)集加上两者图像集的平均差值(RGB三通道差值)来使两个输入图像图像的分布尽可以相近,这样我们的损失函数曲线下降会更快些。
拿代码表示则为:
images_A += images_B.mean(axis=(0, 1, 2)) - images_A.mean(axis=(0, 1, 2))
图像增强
当然还有图像增强技术,这个技术就不必多说了,基本是万能的神器了。我们可以旋转、缩放、翻转训练图像从而使图像的数量翻倍进而增加训练的效果。
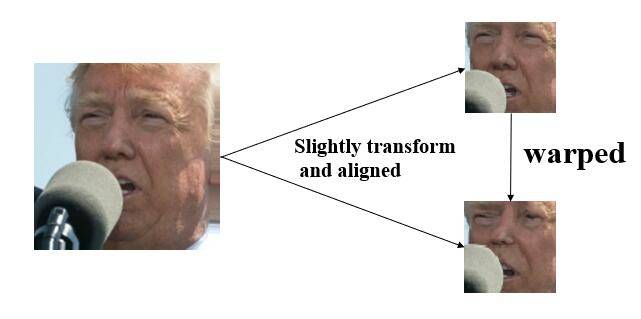
如上图,对于人脸来说,使用扭曲的增强技术可以有效地降低训练过程中的损失值,当然增强也是有限度的,不要太过,物极必反。哦对了,还忘了说,我们训练的时候使用的脸部图像只从原图截取了包含脸部的部分,比如上图右上角的aligned image,我们使用OpenCV库截图脸部图像作为训练素材。
图像后处理
至于图像后处理,当然是将我们生成的脸部图像重新拼回去了:
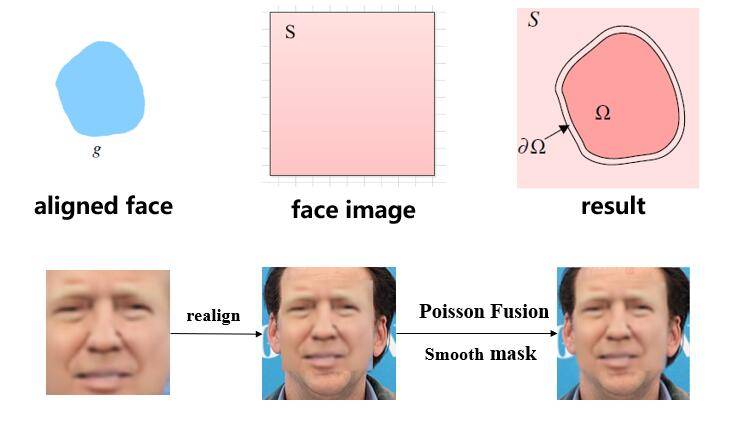
这里使用了泊松融合以及Mask边缘融合的方法,我们可以很容易地看出融合的效果。
总结
总得来说,这个换脸技术是一个结构简单但是知识点丰富的一个小项目,其结构简单易于使用以及修改,并且可以生成不错的效果,但是因为其拥有较多的参数,其运行速度并不是很快(当然我们可以通过改变编码层和解码层结构加快训练生成的速度),并且对于脸部有异物的图像可能会生成不真实的效果。
这是因为自编码器网络并没有针对图像中需要学习的部位进行学习而是全部进行了学习,当然会有很多杂质,这可以通过注意力的机制适当改善。

就说这些吧~
文章来源于OLDPAN博客,欢迎来访:Oldpan博客