大数据第二天————HDFS细节
知识点
1.HDFS :Hadoop Distributed File System。Hadoop的分布式文件系统。是基于《Google File System》做的开源实现。
2.HDFS的作用是存储海量数据。因为HDFS是一个分布式架构,可以无限扩展节点来存储数据
3.HDFS存储文件的特点是 :块存储
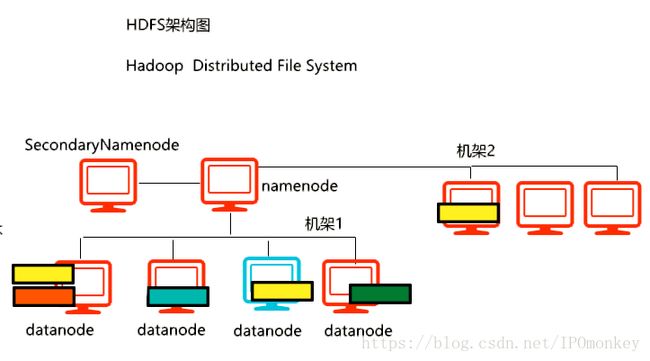
4.HDFS的角色:①namenode ②datanode ③SecondaryNameNode
5.namenode:名字节点,是HDFS的管理者。最主要的职责是管理HDFS的元数据信息。
6.namenode也管理datanode的状态信息,通过rpc心跳机制来监测的。
7.元数据:Meta data。涵盖:文件名、文件大小、文件的切块数量、文件块的大小、副本数量以及每个文件块(包括副本)存储的位置信息。可以通过指令:
hadoop fsck /park01/1.txt -files -blocks -loations f
300mb->3块 128mb\128mb\44mb
257mb->3块 128mb\128mb\1mb8.namnode 不存储文件块,只存储和管理Meta data。namenode会将元数据存到内存里一份,目的是供用户快速查询。
9.namenode为了保证元数据信息的可靠性,会将元数据信息存到磁盘上。
会根据配置文件 core-site.xml里的hadoop.tmp.dir属性的路径来存储。
10.对于元数据的存储,有两个文件:①Edits 文件 ②Fsimage文件
其中---->
Edits文件的作用:记录每个HDFS的操作。
Fsimage文件的作用:存储元数据信息
这两个文件会定期(3600s)合并,目的是为了确保Fsimage文件的元数据是最新的。
11.初次使用Hadoop时,需要执行格式化指令:hadoop namenode -format
此指令的本质作用是生成新的 Fsimage文件 和 Edits 文件。(因为新的Hadoop的环境是没有这两个文件的)
12.注意:格式化指令很危险,因为会清空之前所有的元数据信息。所以一定要慎用。
一般的做法是可以通过配置文件,让hadoop namenode -format 失效。
13.在练习过程中,如果发现少进程的情况,
处理方式一:①停掉所有进程 ②删除tmp目录 ③创建tmp目录 ④执行格式化指令 ⑤启动进程
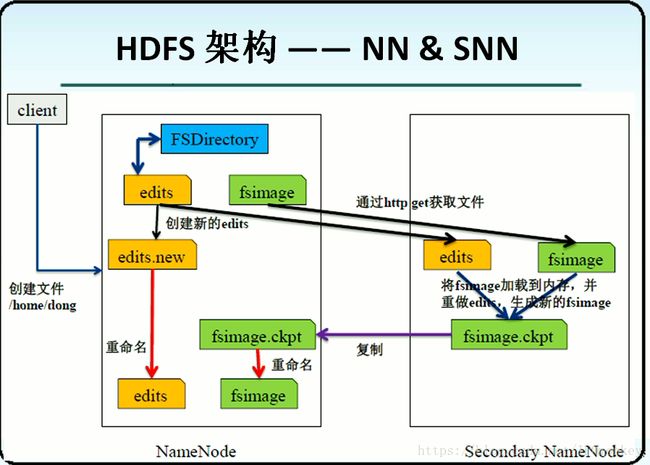
14.SNN的作用不仅仅是namenode的备份节点,而且会负责Edtis和Fsimage文件的合并。这样设计可以使得
NN和SNN都拥有元数据。所以当NN宕机后,SNN可以接替工作。
但是注意:SNN这个机制是有问题的,因为可能会造成元数据的丢失(不是实时热备)。所以SNN机制并没有解决NN的单点故障问题。SNN是Hadoop1.0的机制,在Hadoop2.0之后,已经舍弃了此机制。
15.在Hadoop2.0中,如果用的单机的伪分布式模式,还是会看到SNN进程的。但是Hadoop2.0的完全分布式模型下,是没有SNN的。
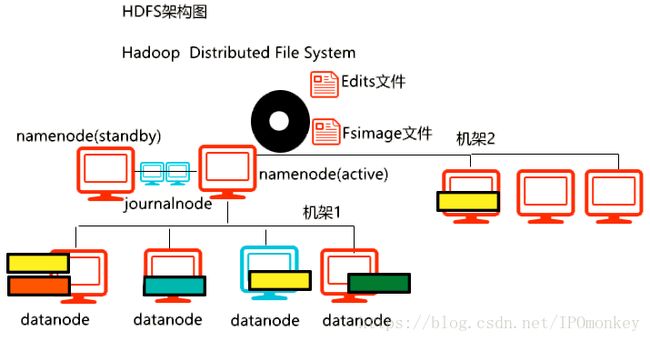
16.每次HDFS启动时,namenode都会将Edits和Fsimage合并一次。目的是确保Fsimage文件的元数据是最新的
17.每次HDFS启动时,每台datanode都会namenode汇报自身文件块的存储情况。namenode收到这些信息后,会检测和统计文件块的数量是否满足要求,以及副本数量,以及文件数据是否损坏。如果检测有问题,会进行修复,在修复的过程中,HDFS会进入安全模式。
18.安全模式的特点:HDFS只能对外提供读服务,不能提供写服务。
手动进入:hadoop dfsadmin -safemode enter
手动退出:hadoop dfsadmin -safemode leave补充:如果是伪分布式模式,副本数量要设置1。如果>1,会导致副本数量一直不能达到要求,会一直处于安全模式
19.对于Edits和Fsimage文件的合并,可以通过指令手动合并:hadoop dfsadmin -rollEdits
20.datanode。数据节点,专门用来存储文件块的
21.Block Size 。切块大小。 Hadoop1.0:64MB Hadoop2.0:128MB
举例:
1.txt 。大小:257MB =》①128MB ②128MB ③1MB
2.txt 。大小:100MB =》①100MB
补充:切块是以文件为单位的,不同的文件,不能共用一个文件块。此外,文件块多大,在磁盘就占多大。
问:HDFS是否适合存储海量的小文件?
不适合。因为会占用namenode节点大量的内存空间。因为每一条元数据大约占用150字节。23.HDFS的适用场景
HDFS对于已上传的文件,是不允许修改的。所以 HDFS的适用场景是:once-write-many-read
一次写入,多次读取的场景。
补充:HDFS不允许修改,但允许数据追加。