学习之路——Spark(3)——Spark RDD内部结构
文章目录
- 什么是RDD
- RDD的接口
- 分区(Partition)
- 依赖(Dependency)
- 窄依赖(Narrow Dependency)
- 宽依赖(Shuffle Dependency)
- 抽象类Dependency
- 依赖与容错机制
- 计算(Computing)
- 分区器(Partitioner)
- 哈希分区器
- 范围分区器
- 持久化(Persistence)
- 检查点(CheckPoint)
- 引用
本文原地址在 www.zicesun.com icesuns.github.io
Spark是一个基于分布式内存的大数据计算框架,RDD (Resilient Distributed Dataset)是Spark最重要的一个数据抽象。这篇文章记录了我对RDD的一些理解,有不足和错误的地方,请留言指正。
什么是RDD
RDD (Resilient Distributed Dataset),弹性分布式数据集,是数据集合的抽象。它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD的计算具有惰性,只有在RDD需要讲计算结果提交到Driver或者需要把数据写到文件的时候,计算才真正开始。Spark为RDD的计算提供了两类接口,也就是转换(transformation)操作和动作(action)操作。其中转换操作,是将RDD转换成另一个RDD,这一步计算是具有惰性延迟的,不会立即执行计算。RDD不能改变,在转换的过程中只会生成一个新的RDD。动作操作,会激发计算。
RDD的转换操作和动作操作会在后续的博客中详细介绍。
RDD的接口
在介绍RDD的接口之前,先带着几个思考:
- RDD的结构是什么样子的,怎么表示并行计算单元。
- RDD是分布式数据集合的抽象,但是在分布式条件下,RDD怎么保证数据分布均匀?
- RDD的计算具有惰性,那么它怎么保证计算的准确性,计算流程是什么样的?
- 大数据计算,怎么容错?当Spark数据丢失之后,怎么保证数据的可靠性和完整性。
RDD通过实现一些接口来完成上述的一些问题。
分区(Partition)
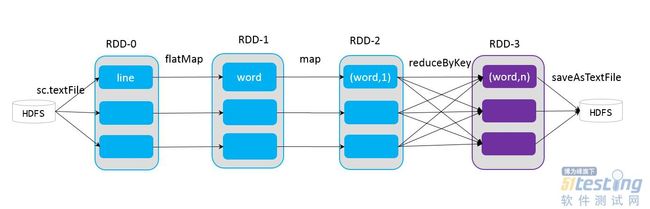
RDD内部如何去表示并行计算的一个单元呢?其实是采用分区,也就是RDD的内部数据集合在逻辑上被划分为多个分片,这样每一个分片叫做分区(Partition)。分区的个数将决定并行计算的粒度,而每一个分区的数据的计算都是在一个单独的任务中进行,因此任务的个数是由RDD的分区的个数来决定的(准确来说应该是一个作业的最后一个RDD的分区数决定)。在下图中,每一个RDD里面的单元就是一个分区。
trait Partition extends Serializable{
def index:Int
override def hashCode():Int=index
}
上面的代码可以看出,分区在源码级别的实现是Partition类,其实是分区的一个标识,index表示这个分区在RDD中的编号。我们通过RDD的编号和Partition编号就可定位到具体的分区,通过接口,可以层存储介质中提取分区对应的数据。
RDD的分区的原则就是尽可能让分区的个数等于起核心的数目。当然用户也可以自指定分区的数据,也可以使用系统默认配置,也就是机器的CPU的核心综述。RDD可以通过创建操作和转换操作生成,在转换操作中,分区的个数根据转换操作中对应的多个RDD之间的以来关系得到。窄依赖的子RDD由父RDD分区个数决定,而宽依赖或shuffle依赖由子RDD的分区器(Partitioner)决定。
分区内部数据的分配原则是尽可能让不同分区内的记录数量保持一直,也就是保证数据分布均衡。正如上面所属,窄以来的子RDD依赖于父RDD,转换之间不会发生shuffle操作,因此在父RDD分区的数据分配方式决定了窄依赖链的分配方式。但是在宽依赖中,父RDD到子RDD之间会进行shuffle操作,因此分区数据的分配由子RDD的分区器决定。哈希分区器不能够保证数据被平均分配到各个分区上,但是范围分区器能够做到这一点。
依赖(Dependency)
在上面也提及到了宽依赖和窄以来。在Spark中,以一个真正的计算标志着一个Job,而一个Job则是由多个转换操作构成。由于Spark的计算具有惰性,只有当遇到一个动作操作的时候,计算任务才被激活。因此经过不同变换之间的RDD形成了一个具有以来关系的链,或者说是一个有向无环图(DAG)。在这个有向无环图中,节点表示RDD,子RDD与父RDD分区之间的边则表示数据的依赖关系。
窄依赖(Narrow Dependency)
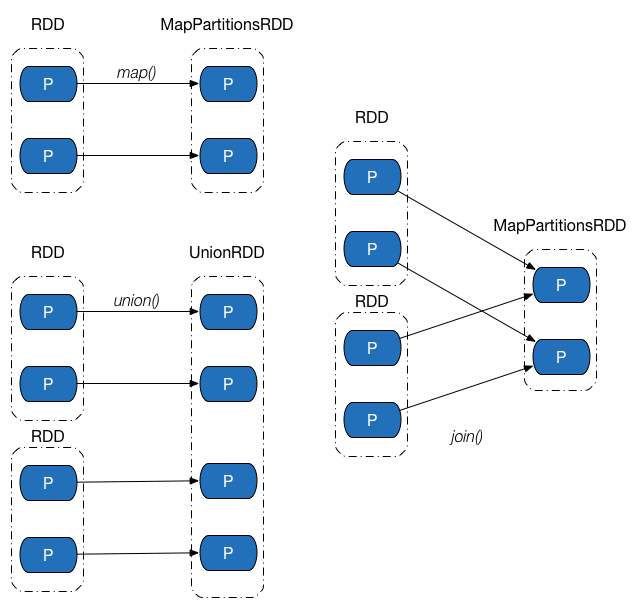
宽依赖(Shuffle Dependency)
shuffle依赖中,父RDD中的一个分区可能会被子RDD中的多个分区使用。这时候父RDD的数据会被再次分割,发送给子RDD的一些分区,也就是Shuffle依赖意味着父RDD和子RDD之间存在这shuffle操作。
抽象类Dependency
源码链接
@DeveloperApi
abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
}
依赖在Spark源码中对应实现是Dependency,每个Dependency子类内部都会存储一个RDD对象,其实就是对应的父RDD。如果一次转换操作对应多个父RDD,就会产生多个Dependency对象,所有的Dependency对象存储在子RDD内部。只要遍历子RDD内部的Dependency对象,就能获取该RDD所有的依赖关系。窄依赖和shuffle依赖的源码参见上面的链接。
依赖与容错机制
我们之前也提到了RDD之间会形成依赖关系,这些依赖关系会形成一个有向无环图。子RDD记录着它依赖着的父RDD。现在我们假设某一个分区的在计算的时候数据丢失了,我们只要遍历该分区的依赖关系,找到它的父RDD信息,然后沿着这个依赖关系往回追溯,就可以找到该分区数据的来源,然后再沿着依赖关系往后计算,就可以计算出这个分区丢失的数据是什么了。
计算(Computing)
RDD的计算是惰性的,一系列的转化只有遇到动作操作的时候才回去计算数据,而分区是数据计算的基本单位。
RDD的计算会用到一个compute方法,RDD的抽象类要求所有的子类都要实现这个方法,该方法的参数之一是一个Partition对象,目的是计算该分区中的数据。
看一下MappedRDD源码
override def compute(split:Partition, context:TaskContext)=
firstParent[T].iterator(split, context).map(f)
MappedRDD类的compute方法调用当前RDD内的第一个父RDD的iterator方法,该方法拉取父RDD对应的分区内的数据。iterator方法会返回一个迭代对象,迭代器内的每个元素就是父RDD对应分区内的数据记录。RDD的粗粒度转换体现在调用iterator的map方法上,f函数是map转换操作的函数参数,RDD会对没一个分区(而不是一条一条数据记录)内的数据执行单个f操作,最终返回包含所有经过转换过的数据记录的新迭代器,也就是新的分区。换句话说,compute函数就是负责父RDD分区数据到子RDD分区数据的变换逻辑。
iterator在执行的时候会根据RDD的存储级别,如果存储级别不是None,则说明分区的数据可能存储在了文件系统,也可能是当前RDD执行过cache或者persist等持久化操作,因此执行getOrCompute方法。
/**
* Internal method to this RDD; will read from cache if applicable, or otherwise compute it.
* This should ''not'' be called by users directly, but
* is available for implementors of custom
* subclasses of RDD.
*/
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
getOrCompute(split, context)
} else {
computeOrReadCheckpoint(split, context)
}
}
getOrCompute方法会根据RDD的编号和分区编号计算得到当前分区在存储层对应的块编号,通过存储层提供的数据读取借口提取出块的数据。对于getOrCompute方法,会出现两种情况。第一种,数据之前存储在存储截介质中,可能是数据本身就在存储介质,也可能是RDD经过持久化操作并且经历过一次计算过程,这时候数据能够成功提取并返回。第二中情况,数据不存储在介质中,可能是丢失,或者RDD经过持久化操作,但是当前分区的数据是第一次被计算,因此会出现拉取到的数据为none的情况,这意味着需要计算分区数据,则会继续调用RDD类中的computeOrReadCheckpoint方法,并将计算得到的数据缓存到存储介质中,下次就不用再重新计算。
computeOrReadCheckpoint方法方法会检查当前RDD是否已经被标记为检查点,如果没有被标记为检查点,则执行自身的compute方法来计算分区的数据,否则直接拉去RDD分区内的数据。对于标记成检查点的情况,当前RDD的父RDD不再是原先转换操作中提供的父RDD,而是被Spark替换成一个Checkpoint对象,该对象中的数据存放在文件系统中,因此最终该对象会从文件系统中读取数据并返回给computeOrReadCheckpoint方法。
分区器(Partitioner)
Spark内置了两类分区器,哈希分区器(Hash Partitioner)和范围分区器(Range Partitioner)
分区器的主要作用有一下三点:
- 决定RDD的分区数量。
- 决定shuffle过程中reducer的个数(实际上也是子RDD的分区个数)以及map端的一条数据应该分配给哪一个分区。
- 决定依赖类型,如果父RDD和子RDD都有分区器并且分区器相同,则表示两个RDD之间是窄依赖,否则是Shuffle依赖。
哈希分区器
/**
* A [[org.apache.spark.Partitioner]] that implements hash-based partitioning using
* Java's `Object.hashCode`.
*
* Java arrays have hashCodes that are based on the arrays' identities rather than their contents,
* so attempting to partition an RDD[Array[_]] or RDD[(Array[_], _)] using a HashPartitioner will
* produce an unexpected or incorrect result.
*/
class HashPartitioner(partitions: Int) extends Partitioner {
require(partitions >= 0, s"Number of partitions ($partitions) cannot be negative.")
def numPartitions: Int = partitions
def getPartition(key: Any): Int = key match {
case null => 0
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
override def equals(other: Any): Boolean = other match {
case h: HashPartitioner =>
h.numPartitions == numPartitions
case _ =>
false
}
override def hashCode: Int = numPartitions
}
哈希分区器的实现在HashPartitioner中,其getPartition方法实现很简单,取键值的hashCoder,除上子RDD分区个数,取余即可。

尽管哈希分区器实现很简单,运行速度很快,但是它不关心键值的分布情况,所以散列到不同发哪去的概率会因数据而异,所以会出现数据倾斜的现象,也就是一部分分区分配的数据很多,一部分很少。
范围分区器
对于范围分区器,之后会单独写篇博客,这里附上一片博客给大家作为参考 分区器
针对哈希分区器的缺点,范围分区器则在一定程度上避免了这个问题,范围分区器尽量使得所有分区的数据均匀,并且分区内的数据的上界是有序的。
持久化(Persistence)
持久化方法有两个,分别是cache和persist。Cache等价于StorageLevel.Memory_ONLY的persist方法,而persist方法也仅仅是修改当前RDD的存储级别而已。SparkContext中维护了一张哈希表persistentRdds,用语等级所有被持久化的RDD,执行persist操作是,会将RDD的编号作为键值,把RDD记录到persistentRdds表中,unpersist函数会调用SparkContext对象的unpersistRDD方法,除了将RDD从哈希表中移除之外,该方法还会降RDD中的分区对应的所有块从存储介质中删除。
检查点(CheckPoint)
检查点机制的实现与持久化是的实现有着较大的区别。检查点并非第一次计算就将计算结果进行存储,而是等到第一个作业结束之后再启动专门的一个作业去完成存储的过程。
详见链接 [检查点] (https://www.cnblogs.com/tongxupeng/p/10439889.html)
引用
1. 检查点
2. 范围分区