深度学习: 从YOLOv1到YOLOv3
Introduction
从YOLOv1到YOLOv3,YOLO系独树一帜,自成一派,是检测算法领域的一股(朵)清(奇)流(葩)。
YOLOv1
论文地址:You Only Look Once: Unified, Real-Time Object Detection

是one-stage系检测算法的鼻祖。即只通过一个stage就直接输出bbox和类别标签:
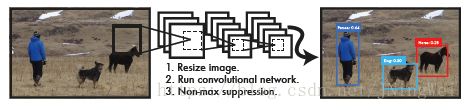
原理是将每张输入图片等分地化为 S×S S × S 个grid进行预测:

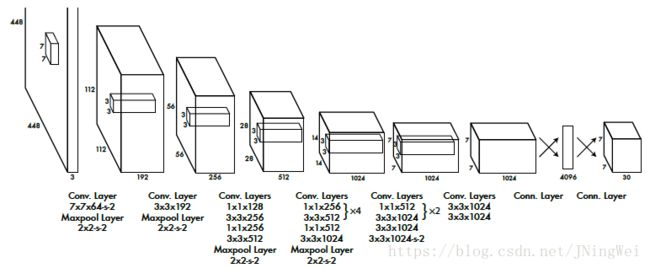
其网络结构如下:
关于YOLOv1的详细解读,请参见我的另一篇博客:YOLO: Unified, Real-Time Object Detection 笔记
YOLOv2
论文地址:YOLO9000: Better, Faster, Stronger

作者通过发明的一系列骚操作(Dimension Clusters、Direct location prediction、Multi-Scale Training、DarkNet-19),再加上博采众长,共同构成了此篇神作。创新点很多,也因此获得了2017CVPR最佳论文提名奖。
Dimension Clusters (维度聚类) 。经过对VOC数据集和COCO数据集中bbox的k-means聚类分析,将anchor机制中原本惯用的 9 anchor 法则 删减为仅保留最常出现的 5 anchor 。其中,狭长型的anchor是被保留的主体:

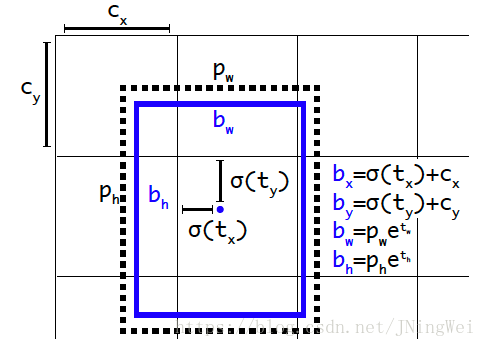
Direct location prediction (直接位置预测) 。用新的位置预测算法来缩小参数范围,使之更容易学习,也使得网络更加稳定:
看detection的主流backbone VGG-16不顺眼,嫌弃它计算量太大(224×224的图像需要计算30.69 billion次浮点运算),于是自己咔咔咔整了个DarkNet-19出来:

关于YOLOv2的详细解读,请参见我的另一篇博客:YOLO9000: Better, Faster, Stronger 笔记
YOLOv3
论文地址:YOLOv3: An Incremental Improvement 笔记

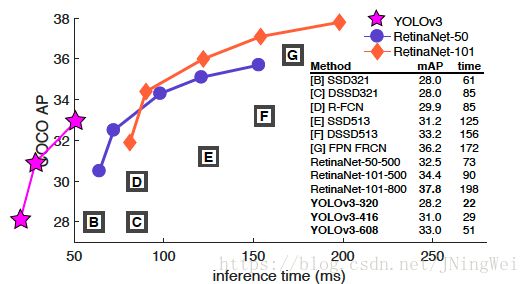
在保证较高检测速度的情况下,大大提升了YOLO系算法的检测精度:
把DarkNet-19玩到了DarkNet-53:

对于小物体的漏检情况得到了很大的改善:

关于YOLOv3的详细解读,请参见我的另一篇博客:YOLOv3: An Incremental Improvement
Summary
相信马上会有YOLOv4、YOLOv5等后传被作者做出来。静待。
[1] YOLO: Unified, Real-Time Object Detection 笔记
[2] YOLO9000: Better, Faster, Stronger 笔记
[3] YOLOv3: An Incremental Improvement 笔记
[4] You Only Look Once: Unified, Real-Time Object Detection
[5] YOLO9000: Better, Faster, Stronger
[6] YOLOv3: An Incremental Improvement
[7] 物体检测论文-YOLO系列