用Python3.6来做维基百科中文语料
首先介绍一下word2vec
参考http://www.cnblogs.com/iloveai/p/word2vec.html
2013年,Google开源了一款用于词向量计算的工具——word2vec,引起了工业界和学术界的关注。首先,word2vec可以在百万数量级的词典和上亿的数据集上进行高效地训练;其次,该工具得到的训练结果——词向量(word embedding),可以很好地度量词与词之间的相似性。随着深度学习(Deep Learning)在自然语言处理中应用的普及,很多人误以为word2vec是一种深度学习算法。其实word2vec算法的背后是一个浅层神经网络。另外需要强调的一点是,word2vec是一个计算word vector的开源工具。当我们在说word2vec算法或模型的时候,其实指的是其背后用于计算word vector的CBoW模型和Skip-gram模型。
python3.6维基百科中文语料
1.http://www.52nlp.cn/中英文维基百科语料上的Word2Vec实验中下载中文维基百科数据,也可从中文数据的下载地址是:https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2。中文维基百科数据特殊处理一下,包括繁简转换,中文分词,去除非utf-8字符等。
2.下载完安装包之后,不需要解压,使用 Wikipedia Extractor 抽取正文文本
Wikipedia Extractor 是意大利人用 Python 写的一个维基百科抽取器,使用非常方便。下载之后直接使用这条命令即可完成抽取,运行了大约半小时的时间。用https://github.com/attardi/wikiextractor/blob/master/WikiExtractor.py来复制下来新建一个py脚本进行存储。然后再cmd里运行一下命令中的任意一个(看自己的情况而定)
(1) python bzcat zhwiki-latest-pages-articles.xml.bz2 | python WikiExtractor.py -b1000M -o extracted >output.txt
参数 -b1000M 表示以 1000M 为单位切分文件,默认是 500K。由于最后生成的正文文本不到 600M,把参数设置的大一些可以保证最后的抽取结果全部存在一个文件里。
(2) python WikiExtractor.py -b 500M -o extracted zhwiki-latest-pages-articles.xml.bz2
(3)我再cmd运行(2)使出现NO such files 这样的提示,是因为找不到路径,所以输入这样命令:python G:\维基百科语料\WikiExtractor.py -b 500M -o extracted G:\维基百科语料\zhwiki-latest-pages-articles.xml.bz2
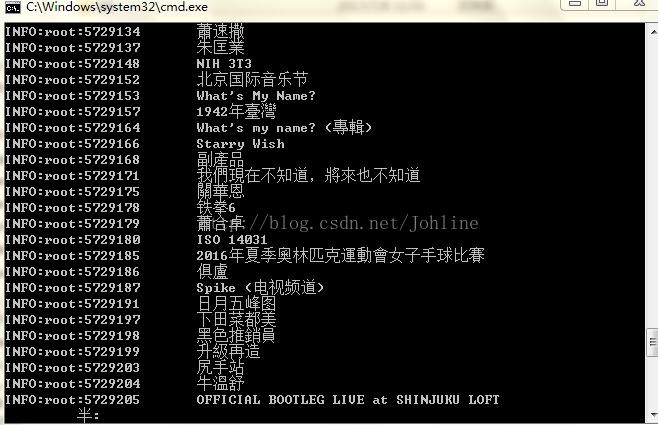
在cmd运行结果:
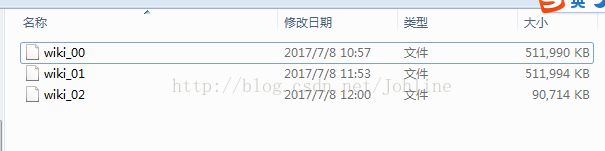
运行之后会存在C:\Users\xiaolin\extracted\AA
3.将中繁体化为简体
首先先安装opencc 安装exe的版本 到https://bintray.com/package/files/byvoid/opencc/OpenCC 中下载
| opencc-1.0.1-win64.7z |
参考一下博客上面写在cmd中运行该命令C:\Users\xiaolin\opencc-1.0.1-win64\opencc.exe -i wiki_00 -o zh_wiki_00 -c zht2hs.iniz
出现![]() 发现opencc-1.0.1-win64中没有这个文件,
发现opencc-1.0.1-win64中没有这个文件,
然后阅读了http://blog.sina.com.cn/s/blog_703521020102zb5v.html这篇博客知道 t2s.json Traditional Chinese to Simplified Chinese 繁體到簡體
所以更改命令为C:\Users\xiaolin\opencc-1.0.1-win64\opencc.exe -i C:\Users\xiaolin\extracted\AA\wiki_02 -o zh_wiki_02 -c C:\Users\xiaolin\opencc-1.0.1-win64\t2s.json
-i表示输入文件,-o表示输出文件,t2s.json表示繁体转换为简体
切记如果不把t2s.json和wiki_02 的绝对路径写出会找不到给文件,之后zh_wiki_02 存在于C:\Users\xiaolin下
也可以直接在AA文件执行,就不需要写wiki_02的绝对路径
最后总的执行结果:

我用了上面的命令得到的zh_wiki_00、zh_wiki_01、zh_wiki_02是空的,所以用了在直接在AA处打开命令行执行

这样得到的就不是空的了
4.用结巴进行中文分词处理参考了https://codesky.me/archives/ubuntu-python-jieba-word2vec-wiki-tutol.wind这篇博客
import jieba
import jieba.analyse
import jieba.posseg as pseg
import codecs,sys
def cut_words(sentence):
#print sentence
return " ".join(jieba.cut(sentence)).encode('utf-8')
f=codecs.open('C:\\Users\\xiaolin\\extracted\\AA\\zh_wiki_00','r',encoding="utf8")
target = codecs.open("C:\\Users\\xiaolin\\extracted\\AA\\zh_wiki_00.fenci", 'w',encoding="utf8")
print ('open files')
line_num=1
line = f.readline()
while line:
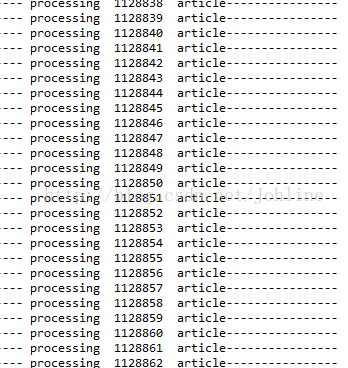
print('---- processing ', line_num, ' article----------------')
line_seg = " ".join(jieba.cut(line))
target.writelines(line_seg)
line_num = line_num + 1
line = f.readline()
f.close()
target.close()
exit()
while line:
curr = []
for oneline in line:
#print(oneline)
curr.append(oneline)
after_cut = map(cut_words, curr)
target.writelines(after_cut)
print ('saved ',line_num,' articles')
exit()
line = f.readline1()
f.close()
target.close()结果为: