Relation Networks for Object Detection [CVPR 2018]
论文:https://arxiv.org/abs/1711.11575
引入了object的关联信息,在神经网络中对object的relations进行建模。主要贡献点有两条:
1. 提出了一种relation module,可以在以往常见的物体特征中融合进物体之间的关联性信息,同时不改变特征的维数,能很好地嵌进目前各种检测框架,提高性能
2. 在1的基础上,提出了一种特别的代替NMS的去重模块,可以避免NMS需要手动设置参数的问题
1. Background
假设现在有一个显示屏幕,问这是电脑显示屏还是电视屏幕,该怎么判断?如果单纯把屏幕取出来,确实很难回答这个问题,但是如果结合周围的东西,就很好解决了……比如,放在客厅环境、旁边有茶几的是电视,而旁边有键盘和鼠标的是电脑显示屏;又或者,宽度有沙发那么大的是电视,而只比一般座椅稍大一点的是电脑屏……
总之,周边其他物体的信息很可能对某个物体的分类定位有着帮助作用,这个作用在目前的使用RoI的网络中是体现不出来的,因为在第二阶段往往就把感兴趣的区域取出来单独进行分类定位了。这篇文章作者就考虑改良这个情况,来引入关联性信息。
放一个直观的例子,蓝色代表检测到的物体,橙色框和数值代表对该次检测有帮助的关联信息。
![Relation Networks for Object Detection [CVPR 2018]_第1张图片](http://img.e-com-net.com/image/info8/bf7edce817b94741970da2de2e641047.jpg)
实际上以往也有人尝试过类似的工作,但是由于关联性涉及到对其它物体特征和位置的假设等原因,一直不是个容易的问题,本文作者从google在NLP文章Attention is all you need方面的一篇论文中的Attention模块得到启发,设计了本文的这种思路。
![Relation Networks for Object Detection [CVPR 2018]_第2张图片](http://img.e-com-net.com/image/info8/3888cdfca39d457190f2a0152234a22a.jpg)
2. Object Relation Module
这个模块的特点就是联合所有object的信息来提升每个object recognition的准确性。它的模块示意图如下图所示:
作者设计的 Attention 权重由两部分组成,外观特征关系权重和空间关系权重。
![Relation Networks for Object Detection [CVPR 2018]_第3张图片](http://img.e-com-net.com/image/info8/f9fe7c49284845ecb9dde8d6998ef0af.jpg)
解释下,这里的 代表第n个物体的apperance特征,其实就是物体自身的大小、颜色、形状这些外观上的特征,而 对应的是是第n个物体的geometry特征,代表物体的位置和大小(bounding box)。这里有多个relation模块(数量为 ),可以类比神经网络中我们每层都会有很多不同的通道,以便于学习不同种类的特征……每个relaiton模块都用所有object的两个特征做输入,得到不同的relaiton特征后再concat,并和物体原来的特征信息融合,作为物体的最终特征……
那么右面的图怎么理解呢?看下面的公式:

是第n个relation模块的输出,它是由各个所有物体的apperance特征经过Wv的维数变化后,又赋予不同的权重叠加得到的……位置特征是体现在权重里的,第m个物体对于当前第n个物体的权重 的求法如下:
![Relation Networks for Object Detection [CVPR 2018]_第4张图片](http://img.e-com-net.com/image/info8/3fe549f0bfc74c14afc0dcce69159dc1.jpg)
公式分母是个归一化的项,重点看分子,主要是由两者决定的,那就是第m个物体对于当前第n个物体在geometry上的权重 和在apperance上的权重 ,它们各自的求法如下:
![Relation Networks for Object Detection [CVPR 2018]_第5张图片](http://img.e-com-net.com/image/info8/bab1e029eab84db6b9ac8d222f7bcb66.jpg)
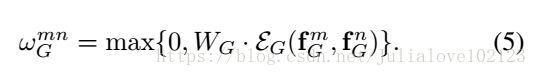
这里的WK,WQ包括下面的WG都起到类似的变化维数的效果,dot代表点乘,dk是点乘后的维数;比较值得在意的是这里的 ,这里是通过另一篇论文(Attention Is All You Need)中提到的方法将低维数据映射到了高维,映射后的维数为dg。
作者选取了dk=dg=64,Nr=16。总结一下这个模块的求法:
- 分别根据两个特征计算它们各自的权重
- 由两个特征的权重获得总权重
- 按照第m个物体对当前物体的总权重,加权求出各个relation模块
- concat所有relation模块,与原来的特征叠加,最终输出通道数不变的新特征
在这个过程中,要留意通道数,比如16个relation模块输出concat可以和$f_A^n$叠加,那么它们每个的通道应该就是 的通道数(记作df)的16分之一。
这个模块直接应用在第二阶段,得到和原来相同的Output(score和bbox),应用是直接在fc层之后,即从原来的:
![Relation Networks for Object Detection [CVPR 2018]_第6张图片](http://img.e-com-net.com/image/info8/28f054c3d9c64e1889486ae22b7e7191.jpg)
改变为:
![Relation Networks for Object Detection [CVPR 2018]_第7张图片](http://img.e-com-net.com/image/info8/79cd82f46a5d4f73a3fbb800b168b545.jpg)
r1,r2代表重复次数,也可以用图来表示:
![Relation Networks for Object Detection [CVPR 2018]_第8张图片](http://img.e-com-net.com/image/info8/72d95a6258b4427e9c18918c48fb2436.jpg)
3. Duplicate removal
作者的另一个贡献就是提出了这种可以代替NMS的消除重复框的方法。框架如下:
![Relation Networks for Object Detection [CVPR 2018]_第9张图片](http://img.e-com-net.com/image/info8/8e2c79c064ec405ea0e6a4857bc42c67.jpg)
要先说明的是,作者把duplicate removal当成一个二分类问题,对于每个ground truth,只有一个detected object被归为correct类,而其余的都是duplicate。
这个模块的输入是instance recognition模块的output,也就是一系列的detected objects,它们每个都有1024-d的特征,分类分数s0还有bbox。而输出则是s0*s1得到的最终分类分数。
s1是怎么算的呢?首先,对于detected objects作者按照它们的scores对它们进行排名,然后将scores转化为rank,据作者说这样更加有效,随后rank信息会按照类似$\varepsilon_G$的求法映射到高a和sigmoid函数,得到$s_1$。
如何判断哪个detected object是correct,而哪些是duplicate?在这里,作者设置了一个阈值 ,凡是IoU超过该阈值的样本都会被选择;接着,在选择的样本中,IoU值最大的为correct,其余为duplicate。当对定位要求比较高的时候,可以设置较高的 ,相应的被选择的样本就会发生变化,s1也会发生变化,直接影响最终的分数。
作者认为这样做的好处如下:
- output的时候,NMS需要一个预设置的参数;而duplicate removal模块是自适应学习参数的。
- 通过设置不同的 ,可以将模块变成多个二分类问题,并取其中最高的值作为输出,作者经过试验,证明这种方式较单一阈值的方式更可靠。
- 作者发现阈值的设置和最后的指标有某种联系。例如mAP0.5在 为0.5时的效果最好,mAP0.75的t同理,而mAP使用多个 效果最好。
- 最后,就是 的含义问题。之前也发过邮件和作者沟通,对方的回复是,它本质上代表的是分类和定位问题的权重,它的值设置得越高,说明网络越看重定位的准确性。
这里作者也提出了问题:
- 只有一个样本被划分为correct,会不会导致严重的正负样本不均衡?
答案是否定,网络工作的很好,这是为什么呢?因为作者实际运行发现,大多数的object的s0得分很低,因此s0和s1就很小,从而导致 和梯度 都会比较小。
- 设计的两个模块功能是否矛盾?因为instance recognition要尽可能多地识别出high scores的物体,而duplicate removal的目标是只选择一个正样本。作者认为这个矛盾是由s0和s1来解决的,instance recognition输出的高s0可以通过较低的s1来调节。
- duplicate removal是一个可以学习的模块,和NMS不同,在end2end训练中,instance recognition输出的变化会直接影响到该模块,是否会产生不稳定性?答案也是否定的,实际上,作者发现end2end的训练方式更好,作者认为这是由于不稳定的label某种程度上起到了平均正则化的作用。
-
4. Experiment
作者主要使用了ResNet 50和101,用两个fc层作为baseline进行了很多对比实验。
包括:
验证检测阶段的效果
作者将使用两个FC层的网络设为baseline。
(1)空间特征
为了验证空间特征的有效性,作者设计了3组实验。将空间关系权重置为1,记为 none;将空间特征嵌入到高维,维度与fA相同,然后将该特征与fA相加,记为 unary。实验结果如表1(a)所示。
(2)关系数量Nr
结果如表1(b)所示。
(3)关系模块的数量
分别在两个FC层后添加不同数量的关系模块,实验结果如表1(c)所示。
效果的提升是来自参数和层数的增加吗?表2对比了不同深度,宽度的网络结构。
验证去重阶段效果
表3验证了去重网络所使用的特征是否有效。可以看出 rank 特征和 bbox 特征起了很重要的作用。
表4与NMS算法进行对比
端到端的目标识别
作者使用不同的检测框架,进行对比。每一个网络框架,分别使用了 2fc head+SoftNMS -> 2fc+RM head+SoftNMS -> 2fc+RM head+e2e(end-to-end)三种网络结构。实验结果如表5所示。
![Relation Networks for Object Detection [CVPR 2018]_第10张图片](http://img.e-com-net.com/image/info8/70c5a7cd9ee0473e87a5fb05a49923d4.jpg)
5. Summary
本文主要是在detection当中引入了relation的信息,我个人觉得算是个很不错的切入点,而且motivation是源自NLP的,某种方面也说明了知识宽度的重要性。但是一个比较可惜的点就是,relation module更像是拍脑袋思考了一个方法然后直接去实验验证了,对于relation到底学到了什么,能不能更好地理解这个信息,作者认为这还是个有待解决的问题。期待在relation问题上能看到更多有趣的思路吧。