Nvidia League Player:来呀比到天荒地老
写在前面
最近的深度学习圈子,NLP社区无疑是最热闹的,各种“碾压BERT”,“横扫排行榜”新闻满天飞,确实人家媒体就是靠点击量吃饭的嘛所以也不要太过苛刻。即便如此,也需要我们自己有独立思考的能力,虽然是被标题吸引进来的,但是对于每个模型我们都需要静下来好好思考。之前博客是有解析了一些BERT的后起之秀,比如ERNIE-Baidu,ERNIE-THU,XLMs,MASS, UNLIM等等,这篇博客呢就是带大家整理一下在那之后NLP社区发生的一些事…
- WWM-BERT from HIT
- SpanBERT from Facebook
- XLNet from CMU&Goole
- RoBERTa from Facebook
- ERNIE 2.0 from Baidu
1、Pre-Training with Whole Word Masking for Chinese BERT
这篇文章(准确说是技术报告)的重点可以从标题一眼看出:Whole Word Masking和Chinese BERT。
全词掩码Whole Word Masking
首先让我们回想一下vanilla BERT的mask策略,对于一个输入首先是进行分词(WordPiece Tokenizer),接着随机地对输入进行mask,最后利用MLM任务去训练模型。
解释一下WordPiece Tokenizer(主要是为了去除未登录词对模型效果的影响),举个栗子,对于英文输入
unaffable,分词结果就是["un", "##aff", "##able"];而对于中文,则是直接按字切分。
那么这样做会导致什么结果呢?大概就是模型只能死板地记住每个词中字母的出现顺序,而不能理解词语的语义。所以最直接的做法就是把整个短语进行mask,也就是这里的全词掩码。其实关于mask的范围,在这篇文章之前就有过BERT+N-gram masking,有过百度的ERNIE,BERT原创团队也是提出了Whole Word Masking(只不过是在英文数据上的)。所以的话这篇技术报告也是注重在对比ERNIE/BERT和WWM-BERT三者的模型效果上。
训练细节
虽然WWM-BERT-ZH只是在原始的BERT上修改的不多,但是按照惯例我们还是简单介绍一下模型训练的细节。
- 数据集
训练使用的语料是中文维基百科数据,包括简体和繁体的。分词的工具是哈工大的LTP,其他数据预处理的方式保持跟vanilla bert一致(一切为了公平) - post-train
接下来的训练可以说是pre-train, 也可以认为是post-train。因为作者认为WWM-BERT-ZH是BERT的一部分而不是一个全新model,所以他们选择在BERT-BASE-ZH的基础上继续训练。模型首先在最长样本长度为 128,批大小为 2560,使用 1e-4 的学习率,初始预热为 10% 的条件下训练了 100k 轮,然后在序列长度为 512,批大小为 384 的样本上进行了同样轮次的训练。训练使用了 LAMB 目标函数,而非 AdamWeightDecayOptimizer。训练使用的是 Google Cloud TPU v3,有 128G HBM。
模型效果比对
作为模型效果对比的下游任务,作者选取了sentence-level到document-level的以下几个任务:
- 机器阅读理解:CMRC 2018 , DRCD , CJRC(这些是数据集)
- 命名实体识别:People Daily, MSRA-NER
- 自然语言推理:XNLI
- 情感分类:ChnSentiCorp, Sina Weibo
- 句子对匹配:LCQMC, BQ Corpus
- 文档分类: THUCNews
okay,关于模型对比的具体结果这里篇幅有限就不贴上来了,大家感兴趣的可以点击标题超链接去文章里看。粗略统计了一下,六项比对任务中,ERNIE赢得四项,WWM-BERT-ZH赢得两项,BERT-ZH…
reference
- 【官方github】
- 【哈工大讯飞联合实验室发布基于全词覆盖的中文BERT预训练模型】
- 【中文最佳,哈工大讯飞联合发布全词覆盖中文BERT预训练模型】
2、SpanBERT: Improving Pre-training by Representing and Predicting Spans
和Whole Word Masking BERT以及ERNIE类似,SpanBERT这里也是选择对原始BERT的mask策略进行调整,不过前者是在phrase/entity的级别进行mask,而spanBERT则是选择了更长的范围进行mask,试验结果指出该种策略会对span selection任务有较明显的提高,比如问答、指代消解等。相比于原始BERT,这里创新点可以认为是以下两点:
mask策略:随机mask span,而不是token预训练目标:为了与新提出的mask策略相匹配,提出了span-boundary objective (SBO);同时发现NSP对下游任务的表现并不好,果断抛弃。
模型细节
okay,让我们来看看这个span masking和SBO到底是怎么实现的。
- Span Masking
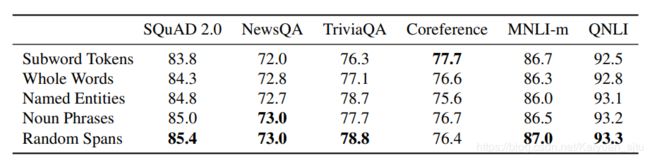
对于输入 X = ( x 1 , … , x n ) X=\left(x_{1}, \ldots, x_{n}\right) X=(x1,…,xn),span masking的具体做法是:首先通过几何分布 ℓ ∼ Geo ( p ) \ell \sim \operatorname{Geo}(p) ℓ∼Geo(p)采样出span的长度,然后随机选择span的起始位置。如此迭代进行,直到采样出的span长度达到15%的输入长度。作者设置 p = 0.2 p=0.2 p=0.2并且丢弃长度大于10的span(确实呀把十个单词都给抹去,还要求模型预测出来,这有点过分了),经过计算最后得出span的平均长度为3.8个单词,注意这里的单词是完整的单词而不是subword。
那么span masking相对于之前的全词masking以及entity masking效果怎么样呢?作者在ablation study中也对其进行了验证。挑选了几种不同的masking策略进行对比,除了指代消解任务,其他下游任务中span masking都表现出更好的效果。
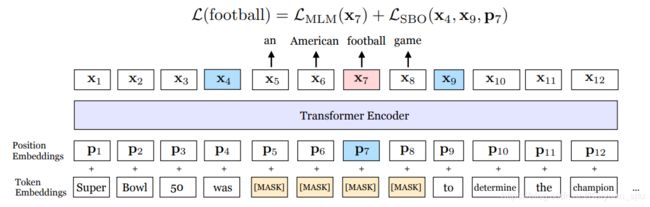
- Span-Boundary Objective (SBO)
SBO的思想就是通过已知的边界去预测未知的被mask掉的那些token。具体而言,对于一个span ( x s , … , x e ) \left(x_{s}, \ldots, x_{e}\right) (xs,…,xe),其中 x s x_s xs和 x e x_e xe分别是span的起始和终止位置。对于每一个被mask的词,SBO使用span起始位置的前一个token x s − 1 x_{s-1} xs−1和终止位置的后一个token x e + 1 x_{e+1} xe+1以及被mask掉token的位置向量 p i p_{i} pi来表示该token:
y i = f ( x s − 1 , x e + 1 , p i ) \mathbf{y}_{i}=f\left(\mathbf{x}_{s-1}, \mathbf{x}_{e+1}, \mathbf{p}_{i}\right) yi=f(xs−1,xe+1,pi) h = LayerNorm ( GeLU ( W 1 ⋅ [ x s − 1 ; x e + 1 ; p i ] ) ) \mathbf{h}=\text { LayerNorm }\left(\operatorname{GeLU}\left(W_{1} \cdot\left[\mathbf{x}_{s-1} ; \mathbf{x}_{e+1} ; \mathbf{p}_{i}\right]\right)\right) h= LayerNorm (GeLU(W1⋅[xs−1;xe+1;pi])) f ( ⋅ ) = LayerNorm ( GeLU ( W 2 ⋅ h ) ) f(\cdot)=\text { LayerNorm }\left(\operatorname{GeLU}\left(W_{2} \cdot \mathbf{h}\right)\right) f(⋅)= LayerNorm (GeLU(W2⋅h))
举个栗子可以看下图,最终的模型是将MLM和SBO两个损失相加进行训练。
- Single-Sequence Training
其实这里就是对原始BERT中NSP任务的解读,在作者们的实验中发现不使用NSP进行预训练得到的模型效果反而更好,即Single-Sequence Training,下表中2seq表示segment_a + segment_b的输入形式

推测可能是由于(a)长度更长的完整文本包含信息更全;(b)从另一个文档中选取下一句会对模型引入噪声。
3、XLNet: Generalized Autoregressive Pretraining for Language Understanding
可以看到,之前的预训练模型都是在BERT的基础上修改一些小组件,数据集啊预训练目标啊但是整体还是属于BERT派的。但是在这篇文章里,谷歌和CMU又放出了一个新的模型XLNet,果然…又屠榜了…首先数据和算力比BERT多是一个原因,另外一个的话也是找到了BERT中的一些缺点然后改进它导致的。
PS. 关于XLNet的解读网上现在已经有很多了,所以这里我仅仅列举比较重要的几个方面,可能捎带几句不会太具体,这一节reference部分会给出个人认为比较好的解读参考~
AE & AR
文章一开始就把大规模预训练模型分为两类autoregressive (AR) 和autoencoding (AE)。简单而言,自回归语言模型就是自左向右或者自右向左地对文本进行语言建模,它的好处是对生成任务有天然的优势,缺点呢就是只能得到单向的信息不能同时利用上下文的信息。而自编码就是类似BERT那样的通过[MASK]标记来获取前向和后向的信息。
BERT的不足
文章主要指出了BERT模型的几点不足:
- 为了利用起上下文信息,BERT引入的[MASK]标记会造成训练与预测阶段的不一致,出现 pretrain-finetune discrepancy,导致性能下降;
- BERT假设随机mask掉的token是条件独立的,但是实际上它们之间可能存在关系
XLNet的改进
为了改进上面BERT的缺陷,同时利用其AR和AE模型的优势,这就诞生了XLNet。那么XLNet到底是怎么做的呢?
- Permutation Language Modeling
为了不引入噪音的[MASK]标记,同时能够获取到上下文的信息。XLNet新提出了一种预训练目标:Permutation Language Modeling(PLM)。对于长度为T的训练,输入T的所有可能的排列组合共 T ! T! T!种(后面优化部分提出不会输入所有排列而是通过采样出一部分进行训练),但是整体的训练方向还是从左至右,这样处理就可以认为将上下文信息融入到模型当中去了。
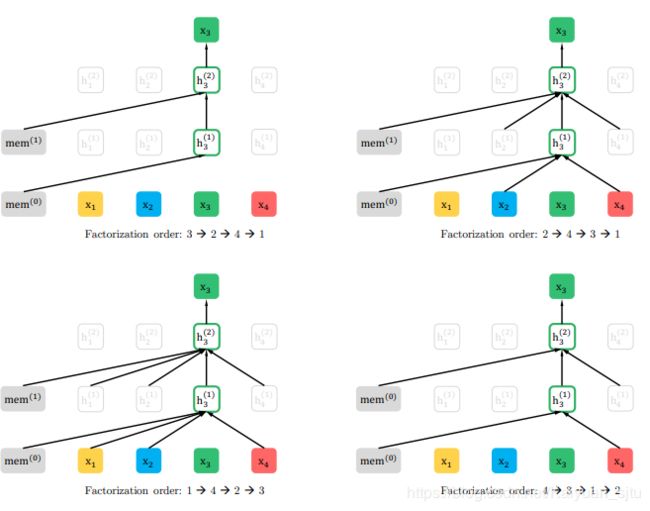
- Two-Stream Self-Attention
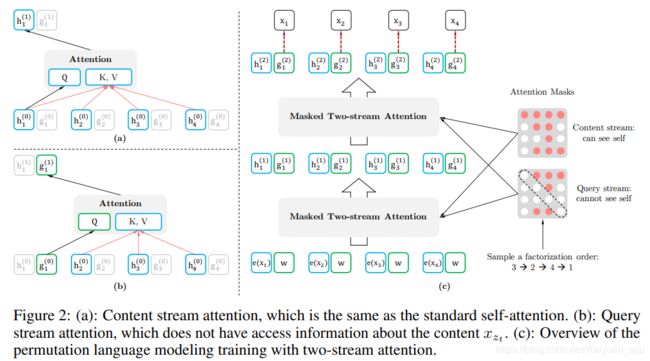
那么上述思想具体是怎么实现的呢?注意一下这里输入不同的排列组合不是真正地打乱原始输入,而是在网络结构内部进行一些操作让模型认为你的输入顺序改变了,因为我们在最后预测的时候输入是不会变的。这些操作就是通过注意力掩码来实现的,其实这个思想在之前的Unified Language Model Pre-training for Natural Language Understanding and Generation(Microsoft/2019) 也有出现过。下面简单介绍一下具体的双流注意力
(1)content流注意力: 就是常见的self-attention
h z t ( m ) ← Attention ( Q = h z t ( m − 1 ) , K V = h z ≤ t ( m − 1 ) ; θ ) h_{z_{t}}^{(m)} \leftarrow \text { Attention }\left(\mathrm{Q}=h_{z_{t}}^{(m-1)}, \mathrm{KV}=\mathbf{h}_{\mathrm{z} \leq t}^{(m-1)} ; \theta\right) hzt(m)← Attention (Q=hzt(m−1),KV=hz≤t(m−1);θ)
(2)query流注意力: 主要就是用来解决BERT里的[MASK]标记的
g z t ( m ) ← Attention ( Q = g z t ( m − 1 ) , K V = h z < t ( m − 1 ) ; θ ) g_{z_{t}}^{(m)} \leftarrow \text { Attention }\left(\mathrm{Q}=g_{z_{t}}^{(m-1)}, \mathrm{KV}=\mathbf{h}_{\mathrm{z}<t}^{(m-1)} ; \theta\right) gzt(m)← Attention (Q=gzt(m−1),KV=hz<t(m−1);θ)
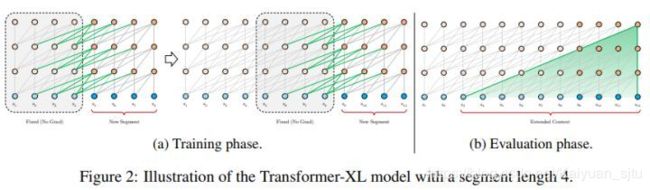
- Transformer-XL
作这一改进是支持长文本的任务
reference
- 官方开源代码
- XLNet:运行机制及和Bert的异同比较
- 如何评价在20个任务上超越BERT的XLNet?
- 【NLP】XLNet粗读
- XLNet原理浅析
4、RoBERTa: A Robustly Optimized BERT Pretraining Approach
看了一眼RoBERTa的作者和前面SpanBERT的作者基本都是一样的…可以…这都不是重点!重点是-----XLNet屠榜了,BERT坐不住了,文章指出BERT是完完全的underfit,于是他们又对BERT进行了一次改造计划,当然,最终结果又是:屠榜。恭喜BERT重回榜首
Our training improvements show that masked language model pretraining, under the right design choices, is competitive with all other recently published methods.
整理了一下RoBERTa相比原始BERT模型的新的配方:
- 使用更大的预训练语料(BERT为16G,RoBERTa直接到了160G)
- 更长的训练时间:100k to 300k steps
- 更大的batch:2k to 8k
- 丢弃了NSP任务
- 使用full-length sequences,而不是截断的文本
- 修改static masking策略为dynamic masking
- 优化器参数调整

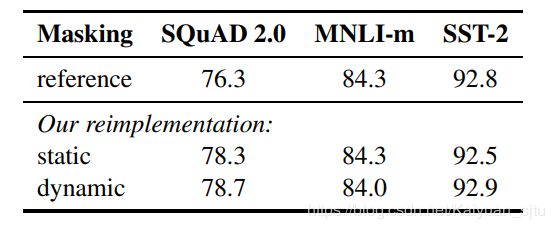
动态掩码
在原始的BERT实现中,mask操作是在数据预处理的时候就完成的,这样在每个训练epoch中数据的mask位置都是相同的,这显然是不太合适的。而动态mask则是对于每一个输入都生成一次新的mask,这对于更大训练数据集/更大训练步数是很重要的。实验结果如下,dynamic masking效果是比static好了一点点,但是四舍五入等于一样…
NSP任务
同XLNet/SpanBERT一样,作者在这里也是发现NSP任务对下游任务并不会起到帮助甚至有点小危害,

reference
- 官方开源代码
- 重回榜首的BERT改进版开源了,千块V100、160GB纯文本的大模型
- 如何评价RoBERTa?
5、ERNIE2.0: A Continual Pre-training Framework for Language Understanding
本文压轴留给国产模型ERNIE2.0。Baidu团队之前发布的ERNIE1.0效果就不错,虽然基础框架沿袭BERT,但是训练语料以及mask策略的改进,使其在中文任务上表现更好。这刚过了几个月,又发布了增强版的ERNIE,最近NLP社区更新速度可见一斑。
先前的模型比如ELMO、GPT、BERT、ERNIE1.0、XLNet等都是基于词和句子的共现关系来训练的,这导致模型不能够很好地建模词法、句法以及语义信息。为此,ERNIE2.0提出了通过不断增量预训练任务进行多任务学习来将词法句法以及语义信息融入到模型当中去。整体流程如下所示,首先利用简单的任务初始化模型,接着以串行的方式进行持续学习(Continual Learning),对于每次新增的训练任务,模型可以利用之前已经训练过的任务信息去更好地学习新任务,这跟人类的学习方式是一样的。
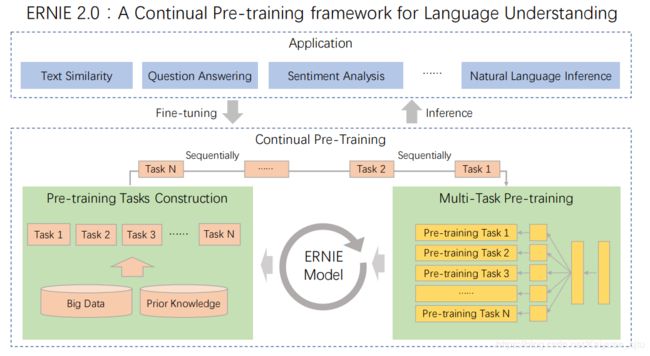
模型框架
整体框架还是基本跟ERNIE1.0的一样,不过ERNIE2.0为了匹配多任务持续学习的理念,需要在输入的时候额外增加一部分Task Embedding,用来告诉模型这是在处理哪个任务。
预训练任务
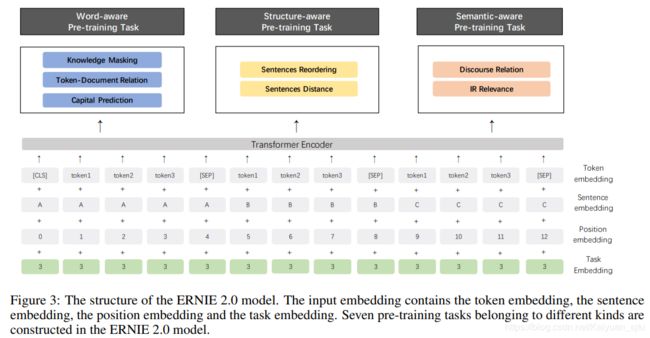
前面说到要让模型获取词法、句法以及语义的信息,那么怎么设计合适的预训练任务就成了非常重要的一环。其实BERT本身也可以看做是多任务(MLM+NSP),然后对于扩展BERT至多任务,MTDNN也有过尝试,使用了GLUE相似的任务进行训练然后在GLUE上SOTA了。不过ERNIE2.0与MTDNN在任务设计上不同的是,在预训练阶段使用的任务基本都是无监督或者是弱监督的。要知道在NLP中有标注的数据不多,但是无标注的数据可以说是源源不断,如果能好好利用起来简直功德圆满。okay,下面我们来介绍一下具体的任务设计
Word-aware Pre-training Tasks
基于单词的预训练任务用于获取词法信息
- Knowledge Masking Task: 就是ERNIE1.0使用的预训练任务,将实体与短语进行mask,具体可以参考站在BERT肩膀上的NLP新秀们(PART I)
- Capitalization Prediction Task: 预测单词是否大写。因为在语料中大写字词通常具有特殊含义
- Token-Document Relation Prediction Task : 预测某一个段落的token是否出现在同一篇文档的另外段落中。可以认为是对关键字进行建模
Structure-aware Pre-training Tasks
主要是用于建模句法信息
- Sentence Reordering Task: 具体而言是把一段话拆分成多个segment,之后对其进行排列组合,让模型去预测正确的原始顺序。感觉有点像高中英语试卷大作文前面的那一题hhh…
- Sentence Distance Task: 预测句子之间的距离,可以看做是三分类的任务,其中“0”表示两个句子是同一篇文档中相邻的,“1”表示两个句子在同一篇文档中但是不相邻,“2”表示两个句子不在同一个文档中。这个任务的话可以看做是BERT的NSP任务的扩展版
Semantic-aware Pre-training Tasks
主要用于建模语法信息
- Discourse Relation Task: 预测两个句子之间的语义或修辞关系。
- IR Relevance Task : 学习信息检索中短文本的相关性。百度作为搜索引擎的优势就是有大量的query和answer可以用于模型训练。这也是一个三分类的任务,输入为
query+title,输出为标签,其中“0”表示这两个是强相关的(定义为用户点击的结果条目),“1”表示弱相关(定义为搜索返回结果中不被用户点击的条目),“2”表示不相关(定义为没有出现在返回结果里的条目)
模型效果
okay,介绍完模型,我们来看看效果怎么样~ERNIE2.0以及BERT在GLUE上的表现,可以看出在所有任务上ERNIE2.0的效果都超过了原始的BERT和XLNet。但是有一点就是我去GLUE Leadboard上瞄了一眼,好像并没有看到ERNIE2.0的身影,不知道为什么还没有提交上去?
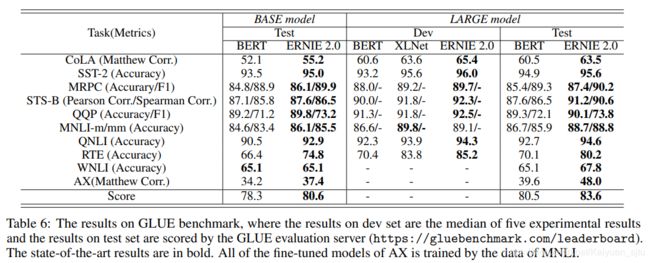
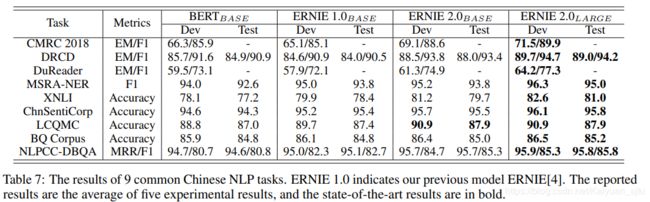
这是中文数据集上的模型比对效果,目前中文版的模型好像还没有发布出来~
reference
- 官方开源代码
- 如何评价百度最新发布的ERNIE2.0?
- ERNIE 2.0:芝麻街 2.0?
- 百度ERNIE 2.0强势发布!16项中英文任务表现超越BERT和XLNet
6、一点小结
不知道大家有没有get到题目的小彩蛋呢哈哈哈~ N.L.P—>Nvidia League Player可以说是非常准确地概括了现在的NLP发展趋势。
- 首先是对BERT的改进,不论是从输入的形式(BERT-pair forABSA/VideoBERT等),模型结构(MASS/MTDNN等),MASK策略(SpanBERT/wwm-BERT等),改进预训练任务(MTDNN/ERNIE-THU/XLMs等),数据语料规模(RoBERTa等)等BERT模型的360度死角都催生了一系列优秀的工作。
- BERT和XLNet的王位之争:这边XLNet刚发布屠榜的消息还没坐热位置呢,那边RoBERTa就出来叫板了。XLNet当然不服,没隔几天就发了一条:只要公平对比,BERT毫无还手之力。我咋记得没多久之前叫板的是BERT和GPT呀,GPT人呢???
- ERNIE2.0虽然论文中的效果超过了BERT和XLNet,但是还不够漂亮。多任务增量训练的思路是很好的,而且选取的几大类预训练任务都非常有启发性,但是论文中的具体细节还不够完善,比如看完论文你还不知道任务训练的顺序是怎么样的,到底是哪几个任务对最后的效果起到作用,增量训练任务有上限吗等等。不过ERNIE1.0给我的使用感觉是挺好的,期待作者们能够完善细节,并,开源2.0的中文模型~
- 另外,最近还有一篇论文受到了比较多的讨论:Probing Neural Network Comprehension of Natural Language Arguments,太扯,不说了
- 最后,希望大家都能客观尊重地去看待别人的工作。因为最近老是看到有人怼某某模型就是堆数据出来的,里面的方法论并不优越,只想说请好好看论文再来评论~
以上
2019.08.11