使用 deeplabv3+ 训练自己的数据集经验总结
简介
deeplabv3+是现今性能最好的语义分割模型之一,本文介绍如何在window环境下安装并运行deeplabv3+。
本文将详细介绍deeplabv3+的环境配置,训练自己的数据,参数调试等内容。
Update:
- 2018-8-22 环境搭建,数据集预处理,训练自己的数据
Todo:
- ✔环境介绍 Anaconda,使用gitbash运行 .sh 文件
- deeplabv3+简介
- ✔代码下载,本地测试
- ✔处理自己的数据集
- 内部的一些微调,及各项参数的用处
- 结果
-
- 简介
- 1、环境介绍
- 1.1 如何使用 Git Bash 运行.sh脚本
- 1.2 Windows环境安装 tf-model
- 1.3 本地测试
- 2、数据改造
- 2.1 去colormap,转换为class形式的标签
- 2.2 图像压缩
- 2.3 转换为TFRecord 格式
- 2.4 注册数据集
- 3 训练、测试、可视化及导出训练好的模型
- PS:使用 tensorboard 监控训练
1、环境介绍
本地工作站实验环境:
系统:windows 7
GPU:Geforce TITAN X × 2
CUDA:9.0 + CUDNN7.5
Tendorflow:1.9.0-gpu (使用1.8.0及以上版本,亲测1.4.0缺少函数,会报错)
上述环境安装的具体步骤可参考:win7+anaconda3+cuda9.0+CuDNN7+tensorflow-gpu+pycharm配置
1.1 如何使用 Git Bash 运行.sh脚本
由于deeplab官方github仓库clone下来的代码中使用了shell脚本进行自动化训练、评估、格式化等操作,然而这些脚本应当是在linux系统下运行的。由于我的机器Ubuntu14.04系统的环境配置不好,无奈只能想方法在Windows上运行。为了能在windows系统上运行shell脚本,这里强烈推荐Git Bash。它是Git(没错,就是那个代码管理系统)软件的一个子程序,感觉比windows自带的cmd和powershell要好用!
可以直接从Git 官网下载,然后正常安装,完毕后在任何文件夹的空白处鼠标右键,点击 Git Bash Here 选项,就可以在当前右键的路径下打开一个 Git Bash 控制台,长这个样子

以一个名 shell_script.sh为例,在脚本所在文件夹下打开 Git Bash,然后键入 ./shell_script.sh 就可以运行了。
虽然deeplab中的
.sh脚本能够在Git Bash中运行,但是一些语句无效的,需要做其他修改,下面会提到。
在运行之前,我还遇到了一个小问题,就是工作站原本就有python环境,如果不修改默认 python 路径,容易发生 import 问题(纯净环境配置后是否有这样的问题未知,总之添加一下环境变量就好了),安装Anacoda后需要将默认的 python 路径改成Anaconda的 python 路径。在用户变量中的 PATH 变量中添加 C:\ProgramData\Anaconda3\Scripts 和 C:\ProgramData\Anaconda\Library\bin 两个路径,此处只是举例,具体路径请按照真实的安装路径添加!!
环境变量设置具体可参考 win10+python3下Anaconda的安装及环境变量配置
1.2 Windows环境安装 tf-model
先给出 tf-model 的Github地址:Tensorflow Models Github官方仓库
deeplab 的源码就在 research 文件夹中。
在 deeplab/g3doc/installation.md 中提到,安装deeplab需要将 research/slim 路径加入 PYTHONPATH 中去,官方给出的方法是在每次运行之前都执行,但仅在linux系统中起作用
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim在cmd和powershell中会报错,亲测虽然Git Bash中不报错但仍然无效(这里我也不懂原理)。
windows 系统下的解决方案为:在py脚本中动态添加地址
将 deeplab 文件夹下的 train.py、 eval.py, vis.py, export_model.py 这四个脚本的开头加语句,没错四个文件都要加(必须加在 import deeplab 语句之前)。
import sys
sys.path.append(r'D:\Code\tf-models\research')
sys.path.append(r'D:\Code\tf-models\research\slim') # 以上两处的路径请按照真实的路径添加1.3 本地测试
环境配置完成之后,在 deeplab 路径下打开Git Bash,运行 ./local_test.sh 脚本进行环境测试。如果机器不够好(显存或内存不够),可以试试 ./local_test_mobilenetv2.sh 测试,是一个小模型,在我的 8G 内存笔记本上,用CPU版本的tensorflow也能跑通。
./local_test.sh如果本地测试运行正常,那么恭喜你,环境的配置已经完成!下一步,也是最重要的一步,处理自己的数据集,使其符合 deeplab 的规范。
2、数据改造
后续99%的bug都源于前期没处理好的数据。 ——沃兹基硕德
自己的数据,格式肯定是五花八门,为了能在deeplab上训练,一定要重视数据预处理过程(深刻的教训)!
简单来说,需要把数据预处理成规定的格式和尺寸范围(因为我测试的时候,太大尺寸的图像导致耗尽OOM,吐槽一下我的原始数据集真的稀烂),生成包含文件名的文本文件,最后以规定的目录形式组织起来。
数据的目录组织形式应当这样:
+ Database # 自己的数据集名称
+ JPEGImages
+ SegmentationClass
+ ImageSets
+ Segmentation
- train.txt
- val.txt
- trainval.txt
+ tfrecord其中:
JPGImages文件夹存放RGB图像;SegmentationClass存放转换为class的标签,格式为单通道的png图像。对应的图像和标签的文件名相同!!扩展名分别为.jpg和.pngImageSets/Segmentation存放有图像文件名的.txt文件,这里我按文件名将数据分为train,val,trainval;tfrecord存放转换的tfrecord格式的数据。.txt文件中的内容应当为对应图像的文件名,不带扩展名:
filename1
filename2
filename3
.....2.1 去colormap,转换为class形式的标签

原始的 label 图像是有着色的,每一种颜色对应了一个类别,这里就需要提供一个颜色到类别的映射——这样每个像素点的值就转换为对应类别的 int 值。
值得一提的是, deeplab/datasets 中自带的 remove_gt_colormap.py 脚本仅适用于带有 colormap 的单通道png图像。这种类型的数据感觉比较少见,在MATLAB中读取会发现,读入的数据包含两个矩阵,一个代表图像灰度值,一个代表灰度值对应的RGB值。

(PASCAL VOC数据集的标签就是这种形式,之前没有见过,推测应该是能压缩数据?)与一般RGB图像不一样。请事先检查数据,如果是这种类型的png图像,则可以使用自带的 remove_gt_colormap.py 脚本进行转换。
具体如何转换,还是要结合实际,无论用什么方法将 colored label 转换为 class label。比如加上背景共有151类,那就分别标记为0~150。
2.2 图像压缩
由于我原始数据集不是很好,图像的尺寸从200到6000多不等,虽说训练时不会有问题(有选项进行缩放),但是测试时太大的图像导致用光显存。(我使用数据集有151个类别,TITAN X 11GB的显存都爆了…)
于是对原始数据进行压缩还是必要的(此处存疑,写本文时发现测试有 reshape 配置选项,暂未研究透彻),我的处理方法是将图像按原比例缩放,使 max{width, height} <= 512。这里附上我的调整图像大小的代码,比较粗糙,献丑了:
import os
from PIL import Image
image_dir = 'JPEGImages/' # 输入RGB图像文件夹
label_dir = 'SegmentationClassRaw/' # 输入label图像文件
image_output_dir = 'JPEGImages_resized/' # 输出RGB图像文件夹
label_output_dir = 'SegmentationClassRaw_resized/' # 输出label图像文件夹
if not os.path.exists(image_output_dir):
os.mkdir(image_output_dir)
if not os.path.exists(label_output_dir):
os.mkdir(label_output_dir)
image_format = '.jpg'
label_format = '.png'
image_names = open('ImageSets/Segmentation/trainval.txt', 'r').readlines()
image_names = list(map(lambda x: x.strip(), image_names))
backup_file = open('ImageSizeBackUP.txt', 'w') # 图像原始尺寸记录下来,备份
for name in image_names:
# Open an image file and print the size
image = Image.open(image_dir+name+image_format)
label = Image.open(label_dir+name+label_format).convert('L')
# Check image size
assert image.size == label.size
# Check image mode
assert image.mode == 'RGB'
print('>> Now checking image file: %s', name+image_format)
print(' Origin size: ', image.size)
width, height = image.size
# Log the original size of the image
backup_file.write('%d,%d\n' % (width, height))
# Resize a image if it's too large
if width > 512 or height > 512:
print(' Resizing...')
scale = 512.0 / max(image.size)
resized_w = int(width*scale)
resized_h = int(height*scale)
image = image.resize((resized_w, resized_h), Image.BILINEAR)
label = label.resize((resized_w, resized_h), Image.NEAREST)
# Save new image and label
image.save(image_output_dir+name+image_format)
label.save(label_output_dir+name+label_format)
print(' Done.')
else:
# Save new image and label
image.save(image_output_dir+name+image_format)
label.save(label_output_dir+name+label_format)
print(' Pass.')
backup_file.close()2.3 转换为TFRecord 格式
对于不大的数据集来说,tensorflow提供了一种高效率的数据读取模式,将数据转换为 TFRecord 格式。这里不多作解释,想要更深入的了解请寻它处。tensorflow读取数据-tfrecord格式
做完上述预处理后,就可以进行数据格式转换了,这里可以直接使用 datasets/build_voc2012_data.py 的代码,在Git Bash中运行:
python build_voc2012_data.py --image_folder=./Database/JPEGImages \
--semantic_segmentation_folder=./Database/SegmentationClass \
--list_folder=./Database/ImageSets/Segmentation \
--output_dir=./Database/tfrecord可在代码中调节参数 _NUM_SHARDS (默认为4),改变数据分块的数目。(一些文件系统有最大单个文件大小的限制,如果数据集非常大,增加 _NUM_SHARDS 可减小单个文件的大小)
转换成功的数据保存在 tfrecord 文件夹中:

2.4 注册数据集
距离开始训练我们的数据集仅一步之遥了,接下来注册我们的数据集,在 segmentation_dataset.py 文件中找到这段:
_DATASETS_INFORMATION = {
'cityscapes': _CITYSCAPES_INFORMATION,
'pascal_voc_seg': _PASCAL_VOC_SEG_INFORMATION,
'ade20k': _ADE20K_INFORMATION,
'dataset_name': _DATASET_NAME, # 自己的数据集名字及对应配置放在这里
}然后添加数据集的相关配置,名字要和上面注册的数据集相同。
_DATASET_NAME = DatasetDescriptor(
splits_to_sizes={
'train': 10000,
'val': 2000, # 这里根据Segmentation中的.txt文件名对应,
'trainval': 12000 # 数字代表对应数据集包含图像的数量
},
num_classes=151, # 类别数目,包括背景
ignore_label=255, # 有些数据集标注有白色描边(VOC 2012),不代表任何实际类别
)最后为了最后的分割结果可视化,也就是将输出的 class map 着色为 colored map 。需要在 get_dataset_colormap.py 文件中修改
# Dataset names.
_ADE20K = 'ade20k'
_CITYSCAPES = 'cityscapes'
_MAPILLARY_VISTAS = 'mapillary_vistas'
_PASCAL = 'pascal'
_DATASET_NAME='dataset_name' # 添加在这里,和注册的名字相同
# Max number of entries in the colormap for each dataset.
_DATASET_MAX_ENTRIES = {
_ADE20K: 151,
_CITYSCAPES: 19,
_MAPILLARY_VISTAS: 66,
_PASCAL: 256,
_DATASET_NAME: 151, # 在这里添加 colormap 的颜色数
}接下来写一个函数,用途是返回一个 np.ndarray 对象,尺寸为 [classes, 3] ,即colormap共有 classes 种RGB颜色,分别代表不同的类别。
这个函数具体怎么写,还是由数据集的实际情况来定,我的数据集提供了 colormap ,就直接返回就可以了,就像下面这样。
def create_dataset_name_label_colormap():
return np.asarray([
[165, 42, 42],
[0, 192, 0],
[196, 196, 196],
[190, 153, 153],
[180, 165, 180],
[102, 102, 156],
[102, 102, 156],
[128, 64, 255],
...
])最后修改 create_label_colormap 函数,在这个调用接口中加上我们自己的数据集:
def create_label_colormap(dataset=_PASCAL):
"""Creates a label colormap for the specified dataset.
Args:
dataset: The colormap used in the dataset.
Returns:
A numpy array of the dataset colormap.
Raises:
ValueError: If the dataset is not supported.
"""
if dataset == _ADE20K:
return create_ade20k_label_colormap()
elif dataset == _CITYSCAPES:
return create_cityscapes_label_colormap()
elif dataset == _MAPILLARY_VISTAS:
return create_mapillary_vistas_label_colormap()
elif dataset == _PASCAL:
return create_pascal_label_colormap()
elif dataset == _DATASET_NAME: # 添加在这里
return create_dataset_name_label_colormap()
else:
raise ValueError('Unsupported dataset.')3 训练、测试、可视化及导出训练好的模型
全部可以通过模改 local_test.sh 来完成,参考 train.py 中的参数列表,设定好路径,就可以开始炼丹了。

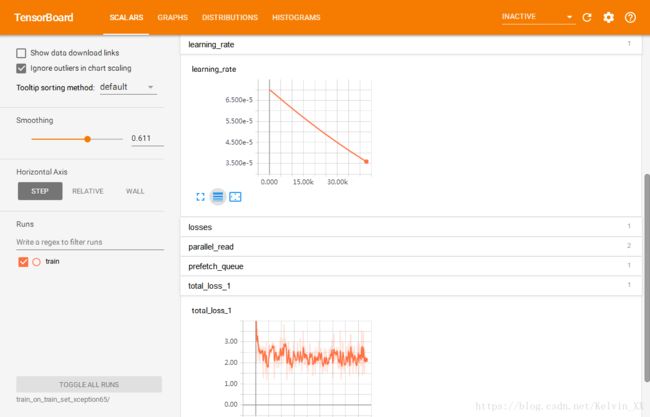
PS:使用 tensorboard 监控训练
正常开始训练后,在 exp 文件夹下打开一个 Git Bash ,输入
tensorboard --log_dir=... # 这里是 EXP_FOLDER 的路径然后在浏览器中打开对应的地址,就可以可视化监控训练中的 loss ,learning rate 了。