中文 NLP 工具总结
文章目录
- 中文 NLP 工具总结
- 1. Jieba 分词
- 1.1 简介
- 1.2 模型原理
- 1.3 安装
- 1.4 使用
- 1.5 分词评测
- 2. pyltp——哈工大
- 2.1 简介
- 2.2 模型原理
- 2.2.1 分词
- 2.2.2 词性标注
- 2.2.3 依存分析
- 2.3 安装
- 2.4 使用
- 2.4.1 分词
- 2.4.2 词性标注
- 2.4.3 依存分析
- 2.4.4 分词、词性标注和依存分析的整合
- 2.5 分词评测
- 3. thulca——清华
- 3.1 简介
- 3.2 模型原理
- 3.3 安装
- 3.4 使用
- 3.5 分词评测
- 4. NLPIR —— 中科院
- 4.1 简介
- 4.2 模型原理
- 4.3 安装
- 4.4 使用
- 4.5 分词评测
- 5. Zpar —— 新加坡科技大学
- 5.1 简介
- 5.2 模型原理
- 5.3 安装
- 5.4 使用
- 5.4.1 训练
- 5.4.2 使用训练的模型进行分词
- 5.5 分词评测
- 6. CoreNLP —— 斯坦福大学
- 6.1 简介
- 6.2 模型原理
- 6.3——6.4 安装与使用
- 6.5 分词评测
- 7. Hanlp —— 开源库
- 7.1 简介
- 7.2 模型原理
- 7.3 安装
- 7.4 使用
- 7.5 分词评测
- 8. 对比总结
- 8.1 分词对比
- 8.2 各个工具的词性标注体系
- 8.3 各个工具所支持的功能
- 9. 附录
中文 NLP 工具总结
前言: 最近由于实验室研究需要,需要调研一下目前已有的中文 NLP 工具,于是在调研完了之后就写了这篇总结,如果哪里有错误还请指出。
1. Jieba 分词
1.1 简介
官网介绍:“结巴”中文分词:做最好的 Python 中文分词组件
但是不是最好的呢?详情见最后的横向对比。
GitHub地址:https://github.com/fxsjy/jieba
1.2 模型原理
- 基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
- 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
- 对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
1.3 安装
安装方式很简单,只要一个命令即可:
pip install jieba
#或者
pip3 install jieba
1.4 使用
# encoding=utf-8
import jieba
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
输出:
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
【精确模式】: 我/ 来到/ 北京/ 清华大学
【新词识别】:他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了)
【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
1.5 分词评测
| ctb6 | msra | pku | |
|---|---|---|---|
| jieba | 80.79 | 81.45 | 81.82 |
2. pyltp——哈工大
2.1 简介
pyltp 是 LTP 的 Python 封装,提供了分词,词性标注,命名实体识别,依存句法分析,语义角色标注的功能。
官网:https://ltp.readthedocs.io/zh_CN/latest/begin.html
官方pyltp介绍:https://pyltp.readthedocs.io/zh_CN/develop/api.html
标注体系等详细介绍:http://www.ltp-cloud.com/intro
GitHub 主页:https://github.com/HIT-SCIR/pyltp
2.2 模型原理
2.2.1 分词
基于字的序列标注,对于输入句子的字序列,模型给句子中的每个字标注一个标识词边界的标记,通过机器学习算法框架从标注数据中学习参数。
2.2.2 词性标注
与分词模块相同,将词性标注任务建模为基于词的序列标注问题。对于输入句子的词序列,模型给句子中的每个词标注一个标识词边界的标记。
2.2.3 依存分析
依存句法分析模块的主要算法依据神经网络依存句法分析算法,Chen and Manning (2014)。同时加入丰富的全局特征和聚类特征。在模型训练时,我们也参考了Yoav等人关于dynamic oracle的工作。
2.3 安装
- 安装
pyltp的包
pip install pyltp
- 下载模型文件:https://pan.baidu.com/share/link?shareid=1988562907&uk=2738088569#list/path=%2F
目前最新的模型是 3.4.0 ,解压之……

2.4 使用
2.4.1 分词
# -*- coding: utf-8 -*-
import os
LTP_DATA_DIR = '/home/username/pyltp/ltp_model' # ltp模型目录的路径
cws_model_path = os.path.join(LTP_DATA_DIR, 'cws.model') # 分词模型路径,模型名称为`cws.model`
from pyltp import Segmentor
segmentor = Segmentor() # 初始化实例
segmentor.load(cws_model_path) # 加载模型
words = segmentor.segment('元芳你怎么看') # 分词
print(list(words))
for word in list(words):
print(word)
segmentor.release() # 释放模型
输出:
['元芳', '你', '怎么', '看']
元芳
你
怎么
看
2.4.2 词性标注
# -*- coding: utf-8 -*-
import os
LTP_DATA_DIR = '/home/knight/pyltp/ltp_model' # ltp模型目录的路径
pos_model_path = os.path.join(LTP_DATA_DIR, 'pos.model') # 词性标注模型路径,模型名称为`pos.model`
from pyltp import Postagger
postagger = Postagger() # 初始化实例
postagger.load(pos_model_path) # 加载模型
words = ['元芳', '你', '怎么', '看'] # 分词结果
postags = postagger.postag(words) # 词性标注
print('\t'.join(postags))
postagger.release() # 释放模型
输出:
nh r r v
2.4.3 依存分析
# -*- coding: utf-8 -*-
import os
LTP_DATA_DIR = '/home/username/pyltp/ltp_model' # ltp模型目录的路径
par_model_path = os.path.join(LTP_DATA_DIR, 'parser.model') # 依存句法分析模型路径,模型名称为`parser.model`
from pyltp import Parser
parser = Parser() # 初始化实例
parser.load(par_model_path) # 加载模型
words = ['元芳', '你', '怎么', '看']
postags = ['nh', 'r', 'r', 'v']
arcs = parser.parse(words, postags) # 句法分析
print("\t".join("%d:%s" % (arc.head, arc.relation) for arc in arcs))
parser.release() # 释放模型
输出:
4:SBV 4:SBV 4:ADV 0:HED
2.4.4 分词、词性标注和依存分析的整合
# -*- coding: utf-8 -*-
import os
LTP_DATA_DIR = '/home/username/pyltp/ltp_model' # ltp模型目录的路径
cws_model_path = os.path.join(LTP_DATA_DIR, 'cws.model') # 分词模型路径,模型名称为`cws.model`
pos_model_path = os.path.join(LTP_DATA_DIR, 'pos.model') # 词性标注模型路径,模型名称为`pos.model`
parse_model_path = os.path.join(LTP_DATA_DIR, 'parser.model') # 词性标注模型路径,模型名称为`parser.model`
from pyltp import Segmentor, Postagger, Parser
class PyltpTool:
def __init__(self, filname, corpus_name):
self.filname = filname
self.corpus_name = corpus_name
self.segmentor = Segmentor() # 初始化实例
self.segmentor.load(cws_model_path) # 加载模型
self.postagger = Postagger()
self.postagger.load(pos_model_path)
self.parser = Parser()
self.parser.load(parse_model_path)
self.raw_data = []
self.seg_sentences= []
self.pos_tags = []
self.deps = []
def read_data_from_file(self):
with open(self.filname, encoding='utf-8') as f_obj:
data = f_obj.readlines()
for row in data:
self.raw_data.append(row.rstrip())
print(self.raw_data)
def get_seg_sentences(self):
for sentence in self.raw_data:
seg_sentence = self.segmentor.segment(sentence)
self.seg_sentences.append(list(seg_sentence))
print(self.seg_sentences)
self.write_to_file(self.seg_sentences, "pyltp_" + self.corpus_name + "_seg_sentences.txt")
def get_pos_tags(self):
for seg_sentence in self.seg_sentences:
pos_tag = self.postagger.postag(seg_sentence)
self.pos_tags.append(list(pos_tag))
print(self.pos_tags)
self.write_to_file(self.pos_tags, "pyltp_" + self.corpus_name + "_pos_tags.txt")
def get_deps(self):
index = 0
while index < len(self.pos_tags):
dep = self.parser.parse(self.seg_sentences[index], self.pos_tags[index])
dep_list = [str(dep_info.head) for dep_info in dep]
self.deps.append(dep_list)
index += 1
print(self.deps)
self.write_to_file(self.deps, "pyltp_" + self.corpus_name + "_deps.txt")
def write_to_file(self, data, filename):
with open(filename, 'w', encoding='utf-8') as f_obj:
for row in data:
for char in row:
f_obj.write(char + " ")
f_obj.write('\n')
def realease(self):
self.segmentor.release()
self.postagger.release()
self.parser.release()
#输入存放一行一行句子的文件,分别输出分词、词性标注和依存分析三个文件。
ctb6_pyltp_tool = PyltpTool("raw_ctb6_test.txt", "ctb6")
ctb6_pyltp_tool.read_data_from_file()
ctb6_pyltp_tool.get_seg_sentences()
ctb6_pyltp_tool.get_pos_tags()
ctb6_pyltp_tool.get_deps()
ctb6_pyltp_tool.realease()
2.5 分词评测
| ctb6 | msra | pku | |
|---|---|---|---|
| pyltp | 91.81 | 88.34 | 95.32 |
3. thulca——清华
3.1 简介
THULAC(THU Lexical Analyzer for Chinese)由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包,具有中文分词和词性标注功能。THULAC具有如下几个特点:
- 能力强。利用我们集成的目前世界上规模最大的人工分词和词性标注中文语料库(约含5800万字)训练而成,模型标注能力强大。
- 准确率高。该工具包在标准数据集Chinese Treebank(CTB5)上分词的F1值可达97.3%,词性标注的F1值可达到92.9%,与该数据集上最好方法效果相当。
- 速度较快。同时进行分词和词性标注速度为300KB/s,每秒可处理约15万字。只进行分词速度可达到1.3MB/s。
官网:http://thulac.thunlp.org/
GitHub地址:https://github.com/thunlp/THULAC-Python
3.2 模型原理
看官方介绍应该是基于概率语言模型的。
3.3 安装
sudo pip install thulac
3.4 使用
# encoding=utf-8
import thulac
thu1 = thulac.thulac(seg_only=True) #默认模式
thu1.cut_f("raw_ctb6_test.txt", "thulca_ctb6_seg_sentences.txt")
thu1.cut_f("raw_msra_test.txt", "thulca_msra_seg_sentences.txt")
thu1.cut_f("raw_pku_test.txt", "thulca_pku_seg_sentences.txt")
3.5 分词评测
| ctb6 | msra | pku | |
|---|---|---|---|
| thulca | 88.94 | 85.56 | 92.28 |
4. NLPIR —— 中科院
4.1 简介
主要功能包括中文分词;英文分词;词性标注;命名实体识别;新词识别;关键词提取;支持用户专业词典与微博分析。NLPIR系统支持多种编码、多种操作系统、多种开发语言与平台。
官网:http://ictclas.nlpir.org/
GitHub地址:https://github.com/NLPIR-team/NLPIR
4.2 模型原理
主要也是基于概率语言模型,详情可以见 \NLPIR-master\NLPIR\paper 这目录下的 paper
4.3 安装
GitHub 上面有给出 SVN 的安装方法,但一直都没下载成功,后来通过把那个项目克隆到码云,从码云下载压缩包才下载成功,所以这里直接把我下载好的压缩包上传到百度云了,直接贴贴出来:
链接:https://pan.baidu.com/s/1cpiTd_QAxTtYTNuy09dWxg
提取码:8r3x
下载解压即可。
4.4 使用
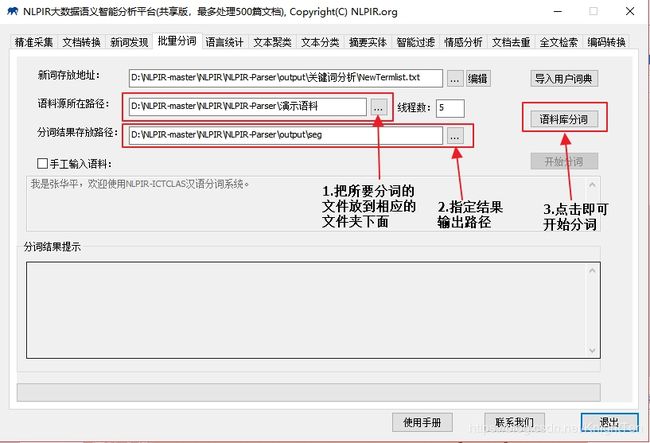
目前我只用了它的分词,打开目录:D:\NLPIR-master\NLPIR\NLPIR-Parser\bin-win64 下的 NLPIR-Parser.exe的可执行文件
4.5 分词评测
| ctb6 | msra | pku | |
|---|---|---|---|
| NLPIR | 87.30 | 88.76 | 93.11 |
5. Zpar —— 新加坡科技大学
5.1 简介
这是一款新加坡科技大学开发的中文分词工具,C++编写,效率很高,并且支持自己训练模型
GitHub地址:https://github.com/frcchang/zpar
5.2 模型原理
对于该模型原理的资料比较少,只知道也是基于概率语言模型的。
5.3 安装
直接克隆 GitHub 的代码进行编译安装
git clone https://github.com/frcchang/zpar.git
之后依次执行:
make zpar.zh
make zpar
make postagger
make depparser
make conparser
make segmentor
make chinese.postagger
make chinese.depparser
make chinese.conparser
5.4 使用
源码里面没有模型,因此模型需要自己训练或者去下载
模型下载:https://github.com/frcchang/zpar/releases
因为模型文件有点大,所以一直没能下载下来,因此就用自己下的一些语料自己训练了一下。
5.4.1 训练
进入到路径:/zpar/dist/segmentor ,可以看到 segmentor 和 train 文件, train 是用来训练模型,segmentor 是用训练好的模型来进行分词的。
./train [train-file] [model-name] [number of iterations] #训练的参数
#msr_training.utf8是训练的分词文件, msra_model是训练后的模型名字,4 表示迭代次数,& 表示放在后台进行训练
./train msr_training.utf8 msra_model 4 &
等执行结束后,我们就获得了一个模型文件:msra_model
之后再加载这个模型文件进行分词
5.4.2 使用训练的模型进行分词
./segmentor [model-name] [input-file] [output-file] #分词的参数
#用刚才训练好的模型文件对 msr_test.utf8 里面的每句话进行分词,并输出到 msr_result.txt
./segmentor msra_model msr_test.utf8 msr_result.txt
5.5 分词评测
| ctb6 | msra | pku | |
|---|---|---|---|
| Zpar | 95.48 | 96.56 | 93.57 |
**注:**由于下载不到官方提供的模型,因此分别用 ctb6 、 msra 和 pku 的训练集来训练三个模型,然后再分别用各自的测试集测试,才得出以上结果。
6. CoreNLP —— 斯坦福大学
6.1 简介
斯坦福大学这个工具可以支持多种语言的 NLP 任务,具体介绍看官网。
官网:https://stanfordnlp.github.io/CoreNLP/
6.2 模型原理
现在最新的模型大多采用神经网络了。
6.3——6.4 安装与使用
详情看简书的这篇文章,讲得很清楚了。
https://www.jianshu.com/p/77c29af0c574
在这里我就讲一个里面没有讲到的功能:如果要对分好的词进行词性标注怎么弄?
修改配置文件既可以:
在配置文件 StanfordCoreNLP-chinese.properties 注释掉 tokenize.language = zh ,写上 tokenize.language = Whitespace
# Pipeline options - lemma is no-op for Chinese but currently needed because coref demands it (bad old requirements system)
#annotators = tokenize, ssplit, pos, lemma, ner, parse, coref
annotators = tokenize, ssplit, pos, parse
#tokenize.language = zh
tokenize.language = Whitespace
6.5 分词评测
| ctb6 | msra | pku | |
|---|---|---|---|
| CoreNLP | 96.75 | 83.99 | 89.71 |
7. Hanlp —— 开源库
7.1 简介
HanLP是由一系列模型与算法组成的Java工具包,目标是普及自然语言处理在生产环境中的应用。不仅仅是分词,而是提供词法分析、句法分析、语义理解等完备的功能。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。
HanLP完全开源,包括词典。不依赖其他jar,底层采用了一系列高速的数据结构,如双数组Trie树、DAWG、AhoCorasickDoubleArrayTrie等,这些基础件都是开源的。官方模型训练自2014人民日报语料库,您也可以使用内置的工具训练自己的模型。
通过工具类HanLP您可以一句话调用所有功能,文档详细,开箱即用。底层算法经过精心优化,极速分词模式下可达2,000万字/秒,内存仅需120MB。在IO方面,词典加载速度极快,只需500 ms即可快速启动。HanLP经过多次重构,欢迎二次开发。
官网:http://hanlp.linrunsoft.com/
GitHub主页:https://github.com/hankcs/HanLP
7.2 模型原理
最新的模型已经转用神经网络实现了,但同样是用 java 实现,效率没有斯坦福的 CoreNLP 高。
7.3 安装
-
下载工程代码压缩包:https://github.com/hankcs/HanLP/releases,下载后用
idea打开(我是用IDEA打开的,不知道eclipse可不可以) -
下载模型文件:https://github.com/hankcs/HanLP/releases ,根据里面提供的网盘地址下载最新模型文件
-
解压模型文件,把里面的文件拷到
\HanLP-master\data\model路径下。
7.4 使用
可以直接使用 HanLP/src/test/java/com/hankcs/demo/ 里面的代码
/*
* He Han
* [email protected]
* 2014/12/7 20:14
*
*
* Copyright (c) 2003-2014, 上海林原信息科技有限公司. All Right Reserved, http://www.linrunsoft.com/
* This source is subject to the LinrunSpace License. Please contact 上海林原信息科技有限公司 to get more information.
*
*/
package com.hankcs.demo;
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.corpus.dependency.CoNll.CoNLLSentence;
import com.hankcs.hanlp.corpus.dependency.CoNll.CoNLLWord;
import com.hankcs.hanlp.dependency.IDependencyParser;
import com.hankcs.hanlp.dependency.perceptron.parser.KBeamArcEagerDependencyParser;
import com.hankcs.hanlp.utility.TestUtility;
import java.io.IOException;
/**
* 依存句法分析(神经网络句法模型需要-Xms1g -Xmx1g -Xmn512m)
*
* @author hankcs
*/
public class DemoDependencyParser extends TestUtility
{
public static void main(String[] args) throws IOException, ClassNotFoundException
{
//CoNLLSentence sentence = HanLP.parseDependency("徐先生还具体帮助他确定了把画雄鹰、松鼠和麻雀作为主攻目标。");
//也可以用基于ArcEager转移系统的依存句法分析器
IDependencyParser parser = new KBeamArcEagerDependencyParser();
CoNLLSentence sentence = parser.parse("徐先生还具体帮助他确定了把画雄鹰、松鼠和麻雀作为主攻目标。");
System.out.println(sentence);
// 可以方便地遍历它
for (CoNLLWord word : sentence)
{
System.out.printf("%s --(%s)--> %s\n", word.LEMMA, word.DEPREL, word.HEAD.LEMMA);
}
// 也可以直接拿到数组,任意顺序或逆序遍历
CoNLLWord[] wordArray = sentence.getWordArray();
for (int i = wordArray.length - 1; i >= 0; i--)
{
CoNLLWord word = wordArray[i];
System.out.printf("%s --(%s)--> %s\n", word.LEMMA, word.DEPREL, word.HEAD.LEMMA);
}
// 还可以直接遍历子树,从某棵子树的某个节点一路遍历到虚根
CoNLLWord head = wordArray[12];
while ((head = head.HEAD) != null)
{
if (head == CoNLLWord.ROOT) System.out.println(head.LEMMA);
else System.out.printf("%s --(%s)--> ", head.LEMMA, head.DEPREL);
}
}
}
注:这里建议使用基于ArcEager转移系统的依存句法分析器,准确率更高!
7.5 分词评测
| ctb6 | msra | pku | |
|---|---|---|---|
| Hanlp | 93.83 | 88.71 | 91.29 |
8. 对比总结
8.1 分词对比
| ctb6 | msra | pku | 平均 | |
|---|---|---|---|---|
| jieba | 80.79 | 81.45 | 81.82 | 81.35 |
| pyltp | 91.81 | 88.34 | 95.32 | 91.82 |
| thulca | 88.94 | 85.56 | 92.28 | 88.93 |
| NLPIR | 87.30 | 88.76 | 93.11 | 89.72 |
| CoreNLP | 96.75 | 83.99 | 89.71 | 90.15 |
| Hanlp | 93.83 | 88.71 | 91.29 | 91.28 |
从结果可知:
在 CTB6 数据集上面,CoreNLP 表现是最好的;
在 msra 数据集上,NLPIR 变现是最好的;
在 pku 数据集上, pyltp 表现是最好的。
而 jieba 在三个数据集中的表现都是最差的。
整体表现 pyltp 和 Hanlp 表现相对较好,而 jieba 依旧是最差的。
综合准确率和分词速度,我认为 pyltp 是目前最优秀的分词工具了。
另外:
这次没有具体测速度,但是从目前比较直观的感受看,jieba 应该是最快的,其次是 pyltp 、thulca 和NLPIR,而CoreNLP 和 Hanlp 的速度比较慢,其中 Hanlp 的速度最慢。
8.2 各个工具的词性标注体系
| 词性标注体系 | |
|---|---|
| pyltp | 863词性标注集:http://www.ltp-cloud.com/intro |
| thulac | 自己的标注集:http://thulac.thunlp.org/#词性解释 |
| NLPIR | 北大标准:https://blog.csdn.net/kevin_darkelf/article/details/39520881/ |
| Zpar | 好像是CTB,但是由于没有下载到官方模型,所以不得而知 |
| CoreNLP | CTB 标注集 |
| Hanlp | 最新的模型也是 CTB 标注集 |
8.3 各个工具所支持的功能
| 分词 | 词性标注 | 依存句法分析 | 命名实体识别 | 语义角色标注 | 语义依存分析 | 新词发现 | 关键词短语提取 | 自动摘要 | 文本分类聚类 | 拼音简繁 | 情感分析 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Jieba | √ | |||||||||||
| Pyltp | √ | √ | √ | √ | √ | √ | ||||||
| thulac | √ | √ | ||||||||||
| NLPIR | √ | √ | √ | √ | √ | √ | √ | √ | √ | |||
| Zpar | √ | √ | √ | |||||||||
| CoreNLP | √ | √ | √ | √ | ||||||||
| Hanlp | √ | √ | √ | √ | √ | √ | √ | √ | √ |
9. 附录
语料库下载:http://sighan.cs.uchicago.edu/bakeoff2005/
主要是MSRA和PKU的语料库