Learning to Navigate for Fine-grained Classification,细粒度图像识别
简介
细粒度图像识别主要是对某个类别的子类进行细分类,例如狗的品种、不同品牌不同型号的车。往往大类总体外观差不多,需要通过一些局部的细节来进行区分,而局部的细节又随着当前目标的姿态不同在图像中的位置也不同,因此一般用于ImageNet的分类网络进行这种细类分类就会比较难。因此假设:有意义的局部信息可以辅助分类,局部信息加全局信息可以进一步提高分类效果。因此目标是找到更有意义的局部位置。
按照上面的假设,首先需要一个方法来给出每个局部位置一个信息量I,信息量越大表明此局部用于预测此类别得到的概率C越高,此局部区域可提升细粒度识别的效果。然后取M个信息量最大的区域加上整图,输入预测网络来预测类别。
本文使用类似faster-rcnn的rpn来生成局部位置的信息量I,本文叫Navigator网络。将信息量最大的M个部分加上整图输入分类网络预测最终结果,本文将预测网络叫Scrutinizer网络。但是Navigator网络也是需要训练的,而且并没有局部区域框的标注,要考虑其他方法训练此rpn。所以作者将Navigator输出的所有区域(NMS后)输入到一个Teacher网络得到每个区域的置信度C,置信度越大的区域信息量也应该最大,通过迫使每个区域的信息量I的顺序与置信度C的顺序一样(通过rank loss)来训练Navigator网络。因此本文的网络叫NTS-Net(Navigator-Teacher-Scrutinizer Network),整个训练是End-to-End的。测试的时候只需要Navigator跟Scrutinizer网络,不需要Teacher网络。总体流程如下:
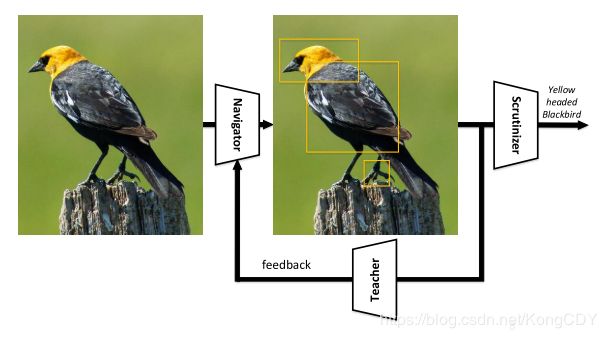
Learning to rank
学习顺序是指,假设X={X1, X2, X3...,Xn}是需要排序的数据(输入数据),Y={Y1, Y2, Y3...,Yn}是目标顺序(也可以是标签,比如[0, 1, 2, 3]),例如Y1在Y2前面,那么X1应该在X2前面。 所以目标是学习一个函数F(x),此函数可以告诉我们X应该怎样排序,例如F(x)可以输出实数,数字越小说明x越排前面。这里介绍了三种方法学习F:
- 回归方法(Point-wise),给每个X设置个目标数值Y,排序就可以按照数值大小来排序。函数F(x)就回归这个数值:

2. 每对判断法(Pair-wise),这个方法是判断随意两个数据的先后顺序,例如F(x1,x2)=1说明x1在x2前面,F(x1,x2)=0说明x2在x1前面,所以F就是个二分类分类器,用分类的方法训练F。
3. 整队判断法(List-wise),跟上面每对差不多也是分类方法,这个是直接预测F(x)是第几个位置,F(x)是个多分类,Y就是类别标签,类别数量为List长度。所以这个方法就只能用于List长度固定的情况了。
本分使用的是第二种方法,后面会用到。
Navigator and Teacher
Navigator为FPN结构的rpn网络,用来输出多个区域R,作者自定义了几个anchor,如下图。输入是448,anchors的scale是{48,96,192},ratio是{1:1,3:2,2:3}。
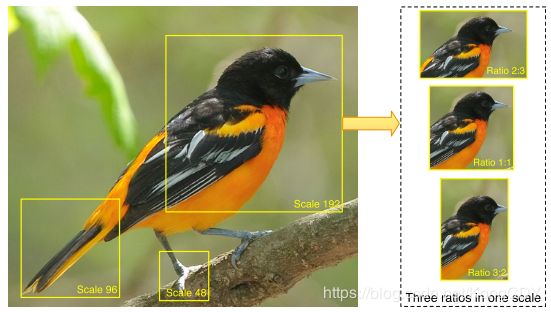
网络输出为每个区域R的信息量I(R),信息量越大的区域,其应该对分类的贡献也越大,也是本着这个原则来训练Teacher网络。利用I(R)使用NMS取M个区域,M是自定义的参数,本文M=3。Teacher网络对M个区域R的输出为置信度C(R),最小化C(R)的cross-entropy loss来优化Teacher网络,公式如下:
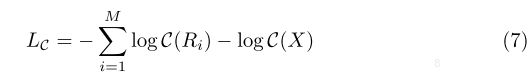
左半部分是M个区域的CE loss,右边是整图的CE Loss。并且置信度的概率值在顺序上应该与信息量相对应,即置信度越高的信息量应该越大,因此使用Rank Loss来通过C(R)优化I(R):
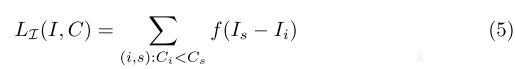
使用的是pair-wise ranking approach,即两两判别。作者的图解为:
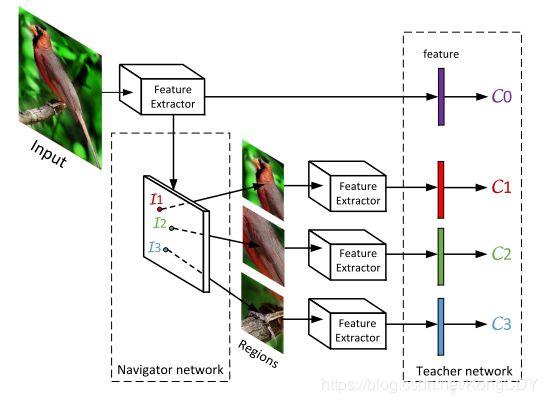
结构方面,主网络作者使用ResNet-50,在ImageNet上预训练,抽特征部分三个网络是共享的,就是上图的Feature Extractor。ResNet50最后的{14 × 14, 7 × 7, 4 × 4} feature map上接两层卷积层,输出多尺度的anchor的信息量I。这部分新加的卷积层的参数Wi是Navigator的参数。Teacher网络就是在ResNet最后的特征后加个softmax分类器,但是输入是M个anchor对应的区域resize到(224x224),参数Wc是softmax的参数。Scrutinizer网络跟Teacher差不多,就是特征是cat整图跟局部图的特征cat(c0, c1, c2, c3),做最终预测,新的参数Ws也是softmax的参数。
Scrutinizer & Others
S网络则综合M个区域及整图,将特征cat起来进行最终的判别。输入为224x224。

Loss也是CE Loss,特征更长了:
![]()
总的Loss为将上面三个Loss相加,权重都为1。
![]()
训练流程伪代码:

Experiments
几个数据集效果比Look closer to see better(RA-CNN)要好一些。 https://github.com/yangze0930/NTS-Net
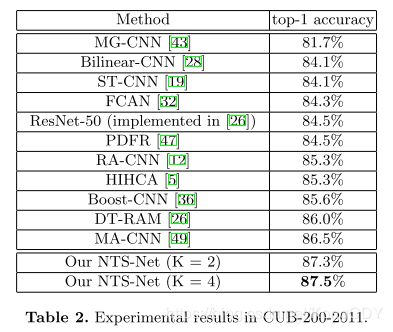

下表可以看出,T网络有2%的提升。k=2也有2%的提升,k加得更多提升就比较少了。
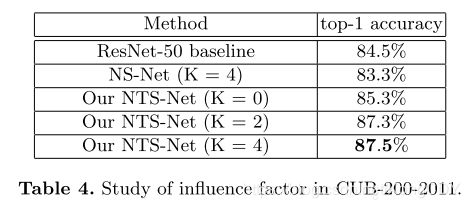
下图是rpn输出的信息量最高的四个区域,信息量按红、橘黄、黄、绿递减。
