通过上一篇文章的扯淡,我们应该已经明白了存储器的层次结构,技术细节很复杂,但是思想却不难理解,因为就是很简单的缓存思想。那么本文我们开始讨论关于内存的另一个话题.虚拟内存。其实思想也是很容易理解的。
我不知道有多少人听过虚拟内存这个概念,但是虚拟内存是计算机系统最重要的概念之一,并且它成功的主要原因就是它一直在沉默的,自动的工作,换句话说,我们这些做应用的程序员根本不需要干涉它的工作过程,但是一个没追求的码农不是好的搬砖民工,所以作为一个有理想有抱负的程序员,我们还是要去理解虚拟内存,甚至可以这样说,如果不理解虚拟内存,你根本不可能理解程序的深层次运行原理。也不可能去理解汇编器,链接器,加载器,共享对象,文件和进程等概念。
上篇文章中提出了几个让大家思考的问题:
- 不管什么程序,最后的直接/间接的编译结果都是0和1,(我们直接理解为汇编)。(这点不知道的,欢迎阅读我的另一篇文章关于跨平台的一些认识),比如这句汇编代码:
mov eax,0x123456;它的意思是将内存0x123456处的内容送往eax这个寄存器。各个应用的数据共同存在内存中的。假设有一个音乐播放器应用的汇编代码中,引用了0x123456这个内存地址。但是同时运行的应用有很多,那其他应用也完全有可能引用0x123456这个地址。那为什么竟然没起冲突和错误呢?
- 进程是计算机领域最重要的概念之一,什么是进程?进程是关于某次数据集合的一次运行活动, 是运行在它自己地址空间的一段自包容程序, 解释的通俗的点, 一个程序在运行时,我们会得到一个假象,该进程好像是独占地使用CPU和内存,CPU是没有间断地一条接一条的执行该程序的指令,所有的内存空间都是供该进程的代码和数据分配使用的。(这点不严谨,其实内存还有一部分要分给
内核kernel)。说起来,这个程序就好像得到了全世界一样。,CPU是我的,内存也全部我的,妹子们还是我的。当然这是假象而已。但是这些假象又是怎么做到的呢?
- 程序中都会引用库API,比如每个C程序都要引用
stdio.h库的printf(),在程序运行时,库代码也要被加入到内存,这么多程序都引用了这个库,难道我内存中需要加很多份吗?这自然不可能,那么库代码又是怎么被所有进程共享的呢?
这些让我们细思恐极的疑问,都将通过这篇文章来给大家解答。
物理和虚拟寻址
在访问者看来,主存就是一个有M个字节大小的单元组成的数组,每字节都有一个唯一的物理地址(Physical Address, PA)。 它的访问地址和数组一样,第一个地址为0,后面地址依次为1,2,3-----M-2, M-1;这叫做线性地址空间。这种自然的访问内存的方式我们称之为物理寻址(physical addressing)。
注意:在访问内存时,对于任意一个地址,(不管是第0个还是第M-1个),访问该地址的时间总是相同的。
在各种数据结构中,我们都说hash表是最快的,比红黑树之类的都要快,那hash表为什么最快?那是因为hash表内部本质上是使用了数组。所以还是数组最快,那数组为什么最快?这是因为我们知道数组的起始地址以及某个元素的序号,就可以得到该元素在内存中的地址,而对于内存,访问任意一个地址,访问时间总是相同的。而类似链表,树等结构,却只能靠遍历了。(不过好的hash算法还是很难设计的,这是另外一个话题了)。
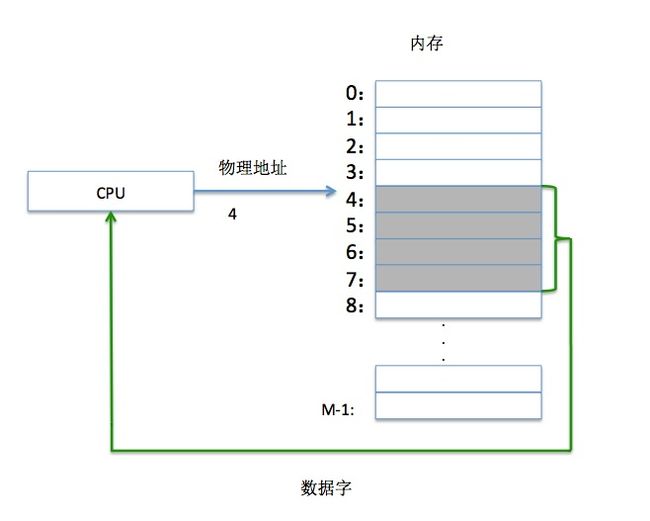
图10:一个使用物理寻址的系统
上图是一个物理寻址的示例,这是一条加载指令,它读取从物理地址4开始的4个字节,CPU通过内存总线,将指令和地址传递给主存,主存读取从物理地址4处开始的4个字节,返回给CPU。
因为这篇文章主要讨论 虚拟内存,是关于L4级主存和磁盘之间的交互问题,为行文方便,文章中有时候直接说内存代指主存。所以这些不要误以为是指L1,L2之类的缓存。如果看不懂这段话啥意思,务必看看我的上一篇文章什么是内存(一):存储器层次结构,然后再来看这篇文章。
早期计算机使用物理寻址方式,但是到了现在的多任务计算机时代,普遍使用的是虚拟寻址(virtual addressing)。如下图所示:
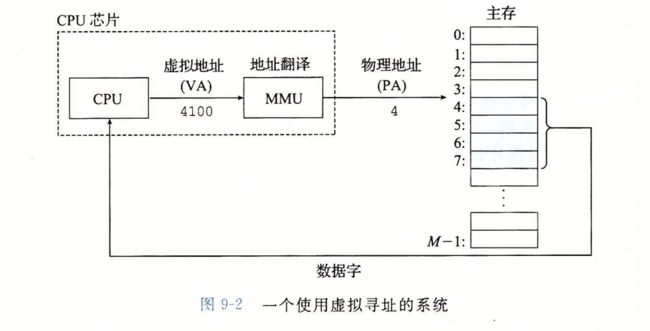
图11:一个使用虚拟寻址的系统
CPU 通过一个虚拟地址(virtual address,VA)来访问主存,这个虚拟地址在被送到主存之前会先转换成一个物理地址。将虚拟地址转换成物理地址的任务叫做地址翻译(address translation)。
地址翻译需要 CPU 硬件和操作系统之间的配合。 CPU 芯片上叫做内存管理单元(Menory Management Unit, MMU)的专用硬件,利用存放在主存中的查询表来动态翻译虚拟地址,该表的内容由操作系统管理。
有少数现代计算机系统依旧在使用物理寻址方式,比如DSP,嵌入式系统,超级计算机系统。这些系统的主要任务是执行单一任务,不像通用性计算机那样需要执行多任务。可以想象到,物理寻址方式更快。这个道理和关于跨平台的一些认识文章中,理论上java比C++慢的道理是一样的。
前面解释完虚拟地址,那么关于文章开头时提的那些疑问,可能有些人心里面都有数了。因为那些地址都是虚拟地址,并非真实的物理内存当中的地址。基本思想已经懂了,那么剩下的我们就更具体的讨论细节。
进程地址空间
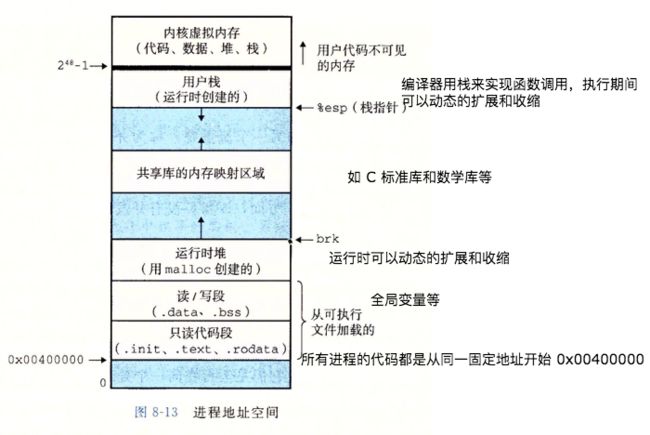
图12:进程地址空间
上图是一个64位的进程地址空间,编译器在编译程序时,将结果编译成32/64位的地址空间。虚拟寻址方式简化了编译器,链接器的工作。同样也因为虚拟内存,每个进程才能有很大的,一致的,私有的的地址空间。这方便了内存管理,保护了每个进程的地址空间不被其他进程破坏。同时也方便了共享库。
虚拟内存也是一种缓存思想
虚拟内存将主存看成是一个磁盘的高速缓存,主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据。
从概念上来说,虚拟内存被组织成为一个由存放在磁盘上的 N 个连续的字节大小的单元组成的数组,也就是字节数组。每个字节都有一个唯一的虚拟地址作为数组的索引。虚拟内存的地址和磁盘的地址之间建立影射关系。磁盘上活动的数组内容被缓存在主存中。在存储器层次结构中,磁盘(较低层L5,参见我们上篇文章图4)的数据被分割成块(block),这些块作为和主存(较高层,L4)之间的传输单元。主存作为虚拟内存(或者说磁盘)的缓存。
虚拟内存(VM)系统将虚拟内存分割成称为大小固定的虚拟页(Virtual Page,VP),每个虚拟页的大小为固定字节。同样的,物理内存被分割为物理页(Physical Page,PP),大小也为固定字节(物理页也称作页帧,page frame)。
在任意时刻,虚拟页面都分为三个不相交的部分:
- 未分配的(Unallocated):VM 系统还未分配(或者创建)的页,未分配的页没有任何数据和它们关联,因此不占用任何内存/磁盘空间。
- 缓存的(Cached):当前已缓存在物理内存中的已分配页。
- 未缓存的(UnCached):该页已经映射到磁盘上了,但是还没缓存在物理内存中。
其中未分配的VP不占用任何的实际物理空间,这点要理解。32位程序地址空间就有4G,至于64G的程序它的地址空间是一个非常大的天文数字(貌似是16777216T),而目前我们的电脑高配的也就2T磁盘,16G内存。如果64位程序每个VP都映射着实际的PP。无论如何也对应不上的。并且也完全没必要一一映射,"图12:进程地址空间"中可以看到,地址空间内有大量的空白。毕竟程序不可能实际使用那么大的地址空间。
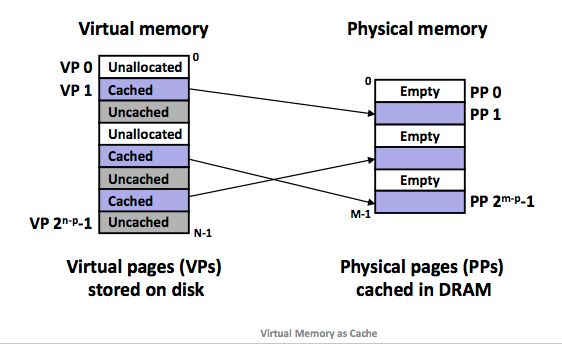
图13:VM使用主存来作为缓存
上图展示了在一个有 8 个页面的虚拟内存中,虚拟页 0 和 3 还没有被分配,所以在磁盘上不存在。虚拟页 1,4,6 被缓存在物理内存中。虚拟页 2,5,7 已经被映射分配了,但是还没有缓存在主存中。
当然,那个图上标注的不对,VP 部分,
n-p和N-1应该分别标注为3和7,不过我们找不到更合适的图了,(这种图自己画压力太大了)。所以大家知道我们假设共有8个VP就好了。
页表(page table)
系统必须得有办法判定某个虚拟页是否缓存在主存的某个地方。这具体可分为两种情况。
- 已经在主存中,就需要判断出该虚拟页存在于哪个物理页中。
- 不在主存中,那么系统必须判断虚拟页存放在磁盘的哪个位置,并且在物理主存中选择一个牺牲页,并将该虚拟页从磁盘复制到 主存,替换这个牺牲页。
这些功能由软硬件联合提供,包括操作系统,CPU中的内存管理单元(Memory Management Unit,MMU)和一个存放在物理内存中叫页表(page table)的数据结构,页表将虚拟页映射到物理页。每次地址翻译硬件将一个虚拟地址转换成物理地址时都会读取页表。
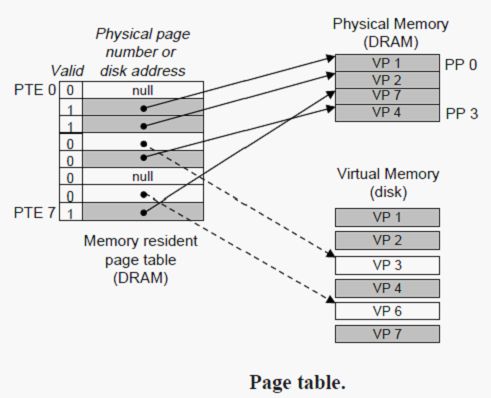
图14:页表
上图展示了一个页表的基本结构,页表就是一个页表条目(Page Table Entry,PTE)的数组。虚拟地址的每个页在页表中都有一个对应的PTE。在这里我们假设每个 PTE 是由一个有效位(Valid bit)和一个 n 位地址字段组成的。有效位表明了该虚拟页当前是否被缓存在 主存 中。
- 有效位为 1,则主存缓存了该虚拟页。地址字段就表示主存中相应的物理页的起始位置。
- 有效位为 0,则地址字段的null表示这个虚拟页还未被分配,否则该地址就指向该虚拟页在磁盘上的起始位置。
页命中与缺页
我们在上篇文章什么是内存(一):存储器层次结构中说过缓存命中与不命中的问题,都是缓存思想,在这里肯定也会存在同样的问题。并且磁盘与主存之间的缓存不命中代价肯定大的多。因为L0-L4之间,每级缓存的速度大约相差10倍左右,但是L4主存与L5磁盘之间,它们的速度相差约十万倍。所以主存与磁盘之间交换的页容量是最大的,尽可能的增加命中率。相应的替换策略,操作系统也使用了更加复杂精密的算法。
在上篇文章什么是内存(一):存储器层次结构,每次替换的区域,我们用了块(block),而这里我们却在说页(page), 其实同一个意思。只是因为历史原因,叫法不同罢了。
当CPU想要读取包含在某个虚拟页的内容时,如果该页已经缓存在主存中,也就是页命中。perfect,很完美。但是如果该页没有缓存在主存中,则我们称之为缺页(page fault)
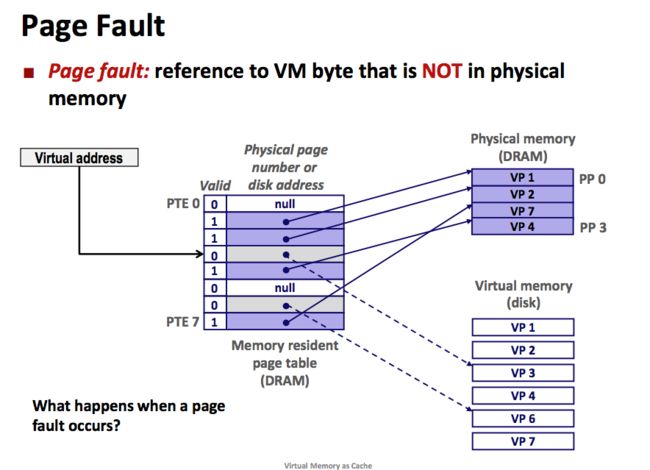
图15:对VP3中的字的应用会引起不命中
如上图所示,CPU 引用了 VP3 中的内容, VP3 并未缓存在主存中。系统从内存中读取 PTE3,得知 VP3 未被缓存,这会触发了一个缺页异常。缺页异常会调用kernel的缺页异常处理程序,该程序会选择一个牺牲页。如下图所示,牺牲页选择了存放在 PP3 中的 VP4。
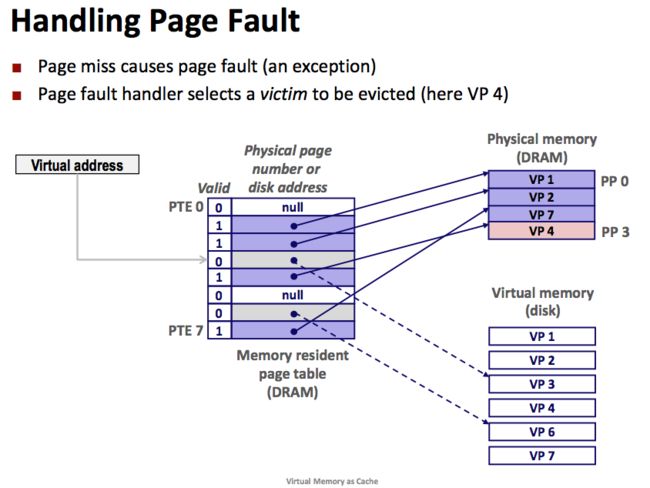
图16:VP4被牺牲了
此时如果 VP4 的内容被修改了,kernel会将它复制回磁盘。接下来,kernel从磁盘赋值 VP3 到内存中的 PP3并更新 PTE3。随后返回用户进程。当异常处理程序返回时,它会重启执行导致缺页的指令,当重新执行这条指令时,因为 VP3 已经在主存中了,此时就是页命中了。
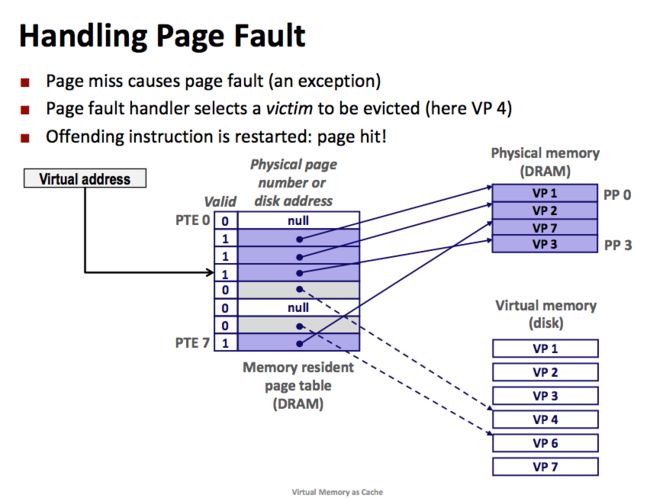
图17:VP3被缓存到PP3
根据习惯性的叫法,我们在磁盘和内存之间传送页的活动叫做交换(swapping)或者页面调度(paging)。这种交换活动,只有当不命中发生时才会发生,(也就说,系统并不会将磁盘内容预存到内存中)。这种策略被称之为按需页面调度(demand paging)。
我们刚才说,缺页错误是一种异常,但是实际上,在计算机系统中,被0除,读写文件,还有上篇文章中我们所说的中断(interrupt),甚至包括我们代码中写的
try catch,都是一种异常。 比如被0除是intel 的CPU规定的的第0号故障(fault)类型的异常。而读写文件,分别是linux规定的第0号和第1号陷阱(trap)类型的异常。多任务的上下文切换,进程的创建回收等,等与系统中这种异常流的处理密切相关。当然,这是另外一个话题了。我们在这里不做累述。
虚拟内存作为内存管理和内存保护的工具
理所当然的,每个进程都有一个独立的页表和一个独立的虚拟地址空间
回到文章开头的问题,比如每个C程序都要调用的 stdio这个库,不可能为每个进程都添加一份库,内存中只有一份stdio库的内容,供每个使用该库的进程共享。
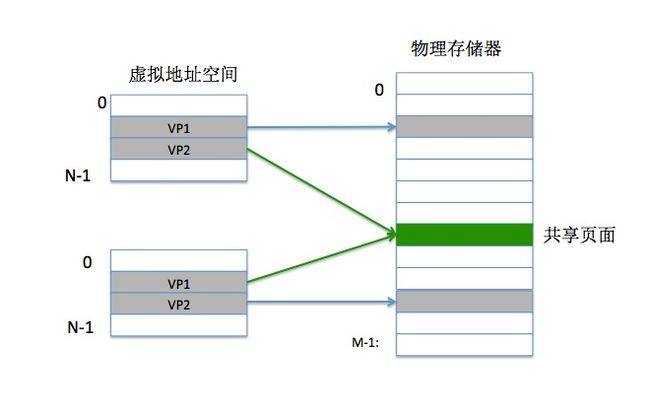
图18:共享页面
如上图所示: 第一个进程的的页表将 VP2 映射到 某个物理页面。而第二个进程同样将它的 VP2 映射到 该物理页面。所以该物理页面都被两个进程共享了。
此时,大家再看一下"图:12 进程地址空间",就会发现在地址空间当中,"共享库的内存映射区域"对于每个进程起始地址都是相同的。再想想进程之间共享内存的通信方式, 所以说虚拟内存简化了共享机制
大家知道,C语言中存在指针,可以直接进行内存操作。因为有了虚拟内存,所以我们的指针操作也不会访问到其他进程的区域,但是哪怕是对于自己的地址空间,很多内存区域也应该是禁止访问的,这不仅包括kernel的区域,也包括自己的只读代码段。那么虚拟内存就提供了这样的一种内存保护工具。
地址翻译机制可以使用一种自然的方式来提供内存的访问控制。PTE 上添加一些额外的控制位来添加权限。每次 CPU 生成一个地址时,地址翻译硬件都会读一个 PTE 。
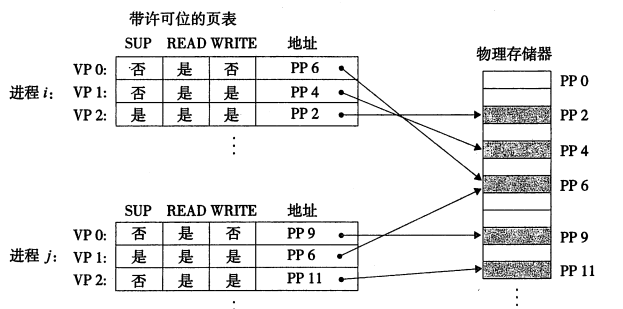
图19:虚拟内存提供内存保护
在上图中,每个 PTE 额外添加了三个控制位, SUP 位表示进程是否必须运行内核模式,READ和WRITE位分别控制页面的读写权限。如果有指令违反了这些控制权限,那么 CPU 会触发一个故障,并将控制传递给内核中的异常处理程序。该种异常一般称为段错误(segmentation fault)。
段 和 页
我们明白了页,页是操作系统为了管理主存方便而划分的,对用户不可见。但是思考这种情况,假设一个页的大小是1M。但是某个程序数据加起来也就0.5M,所以在内存和磁盘进行页交换明显的浪费内存了。所以还一种划分方式是分段。上面那个例子,我将该段划分为0.5M,在内存和磁盘之间交换,这样就避免了浪费。
段是信息的逻辑单元,是根据用户需求而灵活划分的,所以大小不固定,对用户是可见的,提供的是二维地址空间。
对于段,我没找到比较好的资料,所以也没有理解的更清楚,网上的很多文章都相互抄袭。据我所了解,汇编程序员是可以直接操作段的,但是我们写高级语言的程序员有相应的API能进行段操作吗?所以对于段的相关知识,真心不了解,也希望了解的同学可以在留言区指点批评,或者留言相关的文章链接。我回头会再补充这篇博客。谢谢
swap分区的作用
熟悉linux的同学,应该知道linux有一个swap分区。Swap空间的作用可简单描述为:当系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前运行的程序使用。那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间中的信息被临时保存到Swap空间中,等到那些程序要运行时,再从Swap中恢复保存的数据到内存中。系统总是在物理内存不够时,才进行Swap交换。
你电脑打开了一个音乐播放器,但是也没播放歌曲,然后你几天不关机,也一直没关闭这个音乐播放器,随着运行的程序越来越多,内存快不够用了,所以操作系统就选择将这个音乐播放器的内存状态(包括堆栈状态等)都写到磁盘上的swap区进行保存。这样就腾出来一部分内存供其他需要运行的程序使用。你啥时候想听歌了,就找到了这个音乐播放器程序操作。此时, 系统会从磁盘中的swap区重新读取该音乐播放器的相关信息,送回内存接着运行。
在window下也有类作用的硬盘空间,属于对用户不可见的匿名磁盘空间(在C盘)。
特别注意:按照字面意思,swap交换区也可以称为虚拟内存
硬盘上的swap交换区,其实就相当于承担了内存的作用(只是速度很慢罢了)。swap交换区起到了扩大内存的作用。所以从某些意义上来讲,swap区也可以叫做虚拟内存,但是这个虚拟内存是字面意思。和我们本文当中站在计算机系统的角度来解释的虚拟内存不是一个概念。所以特别注意这一点。因为有些人理解的虚拟内存,就是swap交互区。此虚拟内存非彼虚拟内存,所以明白各自的概念和作用。不然和其他人讨论虚拟内存,可能出现驴头不对马嘴的情况。
linux环境下叫做swap分区,window下这块区域没叫做swap分区,就直接按照字面意思叫做"虚拟内存"了。所以两个含义不同的虚拟内存,读者一定要搞清楚了。
百度百科上对虚拟内存的解释非常混乱
关于虚拟内存,看了百度百科的内容,有些地方解释的比较混乱,有些地方是对的,但是有些地方解释的是关于swap分区的内容。如果光从字面意思来看,swap交换区的确可以称为虚拟内存,但是此虚拟内存非彼虚拟内存。百度百科关于这点的介绍比较混乱,百度百科的内容比较多,但是没分清这一点,只会越来越混乱。我又查了维基百科的内容,该词条内容不长,但是下面这段话很重要。
注意:虚拟内存不只是“用磁盘空间来扩展物理内存”的意思——这只是扩充内存级别以使其包含硬盘驱动器而已。把内存扩展到磁盘只是使用虚拟内存技术的一个结果,它的作用也可以通过覆盖或者把处于不活动状态的程序以及它们的数据全部交换到磁盘上等方式来实现。对虚拟内存的定义是基于对地址空间的重定义的,即把地址空间定义为“连续的虚拟内存地址”,以借此“欺骗”程序,使它们以为自己正在使用一大块的“连续”地址。
所以我认为百度百科的解释是混乱的,而维基百科上的应该才是正确的。
两篇关于内存的文章都写完了。因为本人才疏学浅,若有理解错误或解释不清楚的地方,希望各位读者打脸批评。
作者: www.yaoxiaowen.com
博客地址: www.cnblogs.com/yaoxiaowen/
github: https://github.com/yaowen369
欢迎对于本人的博客内容批评指点,如果问题,可评论或邮件([email protected])联系
欢迎转载,转载请注明出处.谢谢