tensorflow+faster rcnn代码理解(一):构建vgg前端和RPN网络
0.前言
该代码运行首先就是调用vgg类创建一个网络对象self.net
if cfg.FLAGS.network == 'vgg16':
self.net = vgg16(batch_size=cfg.FLAGS.ims_per_batch)该类位于vgg.py中,如下:
class vgg16(Network):
def __init__(self, batch_size=1):
Network.__init__(self, batch_size=batch_size)可以看到该类是继承于network类的。也就是vgg类创建的对象拥有network类的变量,同时又有自己新增的变量。我们在来看network类,位于network.py中。可以看到该类含有的变量就是训练一个网络所需要基本的变量了。
class Network(object):
def __init__(self, batch_size=1):
self._feat_stride = [16, ]
self._feat_compress = [1. / 16., ]
self._batch_size = batch_size
self._predictions = {}
self._losses = {}
self._anchor_targets = {}
self._proposal_targets = {}
self._layers = {}
self._act_summaries = []
self._score_summaries = {}
self._train_summaries = []
self._event_summaries = {}
self._variables_to_fix = {}下面代码都以输入图像为600×800举例。
1.构建vgg16的前端(build_head函数)
vgg16的网络模型图如下,代码就是完成红框的部分。
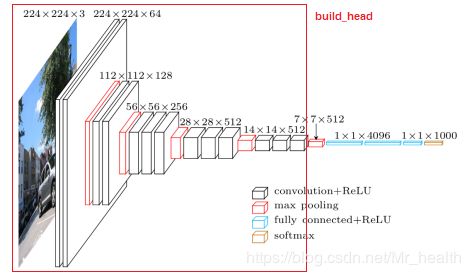
def build_head(self, is_training):
# Main network
# Layer 1
net = slim.repeat(self._image, 2, slim.conv2d, 64, [3, 3], trainable=False, scope='conv1') #224×224×64
net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool1') #112×112×64
# Layer 2
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], trainable=False, scope='conv2') #112×112×128
net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool2') #56×56×128
# Layer 3
net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], trainable=is_training, scope='conv3') #56×56×256
net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool3') #28×28×256
# Layer 4
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], trainable=is_training, scope='conv4')#28×28×512
net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool4') #14×14×512
# Layer 5
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], trainable=is_training, scope='conv5') #14×14×512
# Append network to summaries
self._act_summaries.append(net)
# Append network as head layer
self._layers['head'] = net
return net2.构建RPN网络(build_rpn函数)
我将build_rpn函数的内容拆成两部分来写,首先是生成anchor部分
2.1 生成anchor
def build_rpn(self, net, is_training, initializer):
# Build anchor component 调用network.py中的函数创建anchor的构成,主要有anchor_scale和anchor_ratio两个参数修改
self._anchor_component() #anchor的构成
def _anchor_component(self):
with tf.variable_scope('ANCHOR_' + 'default'):
# just to get the shape right 这里feat_stride = 16,因为此时对于vgg模型来说添加RPN的时候,得到的特征度是经过4次pool的,也就是下采样了16倍
height = tf.to_int32(tf.ceil(self._im_info[0, 0] / np.float32(self._feat_stride[0]))) #下采样后特征图的高度,这里为38(600/16)
width = tf.to_int32(tf.ceil(self._im_info[0, 1] / np.float32(self._feat_stride[0]))) #下采样后特征图的宽度,这里为50(800/16)
anchors, anchor_length = tf.py_func(generate_anchors_pre, #anchor_length是anchor的数量
[height, width,
self._feat_stride, self._anchor_scales, self._anchor_ratios],
[tf.float32, tf.int32], name="generate_anchors") #调用snippets.py中的generate_anchors_pre函数产生anchor
anchors.set_shape([None, 4])
anchor_length.set_shape([])
self._anchors = anchors
self._anchor_length = anchor_length在此基础上进而调用generate_anchors_pre函数生成anchor,位于snippets.py
def generate_anchors_pre(height, width, feat_stride, anchor_scales=(8, 16, 32), anchor_ratios=(0.5, 1, 2)):
""" A wrapper function to generate anchors given different scales
Also return the number of anchors in variable 'length'
"""
anchors = generate_anchors(ratios=np.array(anchor_ratios), scales=np.array(anchor_scales))
#anchors = generate_anchors() #采用generate_anchors默认的形参
#pdb.set_trace()
A = anchors.shape[0]
shift_x = np.arange(0, width) * feat_stride #对应到原图上产生anchor的中心点的位置
shift_y = np.arange(0, height) * feat_stride
shift_x, shift_y = np.meshgrid(shift_x, shift_y)
#shifts形成了(Xmin,Ymin,Xmax,Ymax)的形式,但是由于相当于枚举了achor的中心点,所以Xmin=Xmax,Ymin=Ymax,并且acnhor是按照一行一行排列的
shifts = np.vstack((shift_x.ravel(), shift_y.ravel(), shift_x.ravel(), shift_y.ravel())).transpose()
K = shifts.shape[0] #应该生成的anchor点的数量
# width changes faster, so here it is H, W, C
anchors = anchors.reshape((1, A, 4)) + shifts.reshape((1, K, 4)).transpose((1, 0, 2))
anchors = anchors.reshape((K * A, 4)).astype(np.float32, copy=False)
length = np.int32(anchors.shape[0])
return anchors, length生成anchor的的过程是(在fb的detectron框架中生成方式与这个也一样,见博客 detectron代码理解(六):对输入样本如何产生anchor):
(1)首先对一个cell生程anchor,此时这个anchor没有位置点信息,只有长宽而已,这个长宽满足我们设计的anchor_scales和anchor_ratios,对于generate_anchors的解释可以看:detectron代码理解(四):generate_anchors,生成完毕后A就是这个cell上anchor的数量,这里为9,因为是3个anchor_scales和3个anchor_ratios的尺度的相乘的结果。
(2)之后根据我们输入图片的长宽,以及feat_stride,计算在这样一张图片上以stride为步长要在哪些位置生成anchor,此时才有了放置这些anchor的点shifts
(3)有了这些放置点的位置,将(1)步骤的anchor挪过去,就相当于在每一个位置生成了包含9中形态的anchors。
最后生成的anchor个数为38×50×9 = 17100个anchor
2.2 构建RPN层
def build_rpn(self, net, is_training, initializer):
#生成anchor(代码在前)
#创建RPN层,利用3×3×512来实现
rpn = slim.conv2d(net, 512, [3, 3], trainable=is_training, weights_initializer=initializer, scope="rpn_conv/3x3")
self._act_summaries.append(rpn)
#rpn_cls_score.shape = (1,38,50,18) 每个anchor是二分类 这个H和W是最后一张特征图的大小(这里假设原图是600×800,经过16倍的下采样后成为38×50)
rpn_cls_score = slim.conv2d(rpn, self._num_anchors * 2, [1, 1], trainable=is_training, weights_initializer=initializer, padding='VALID', activation_fn=None, scope='rpn_cls_score')
# Change it so that the score has 2 as its channel size
# 过程:1.首先将rpn_cls_score变为to_caffe的形式,从 (1,38,50,18)变为(1,18,38,50)
# 2.再将to_caffe变为([self._batch_size], [num_dim, -1], [input_shape[2]]),其中num_dim 为下面输入参数2,input_shape[2]是rpn_cls_score的50
# to_caffe = (1,2,9×38,50)= (1,2,342,50)
# 3.最后将上面的第二维度放到最后,就改变为(1,342,50,2)
rpn_cls_score_reshape = self._reshape_layer(rpn_cls_score, 2, 'rpn_cls_score_reshape') #rpn_cls_score_reshape.shape = (1,342,50,2)
#经过上面之后rpn_cls_score_reshape = (1,342,50,2)
#将rpn_cls_score_reshape变为(1×342×50,2)即(17100 2),再增加softmax
#最后再reshape成(1,342,50,2)的大小,所以rpn_cls_prob_reshape的大小为(1,342,50,2)
rpn_cls_prob_reshape = self._softmax_layer(rpn_cls_score_reshape, "rpn_cls_prob_reshape")
rpn_cls_prob = self._reshape_layer(rpn_cls_prob_reshape, self._num_anchors * 2, "rpn_cls_prob") #rpn_cls_prob.shape = (1,38,50,18)
rpn_bbox_pred = slim.conv2d(rpn, self._num_anchors * 4, [1, 1], trainable=is_training, weights_initializer=initializer, padding='VALID', activation_fn=None, scope='rpn_bbox_pred')
return rpn_cls_prob, rpn_bbox_pred, rpn_cls_score, rpn_cls_score_reshape最后RPN层的输出为:
- rpn_cls_prob
- rpn_bbox_pred
- rpn_cls_score
- rpn_cls_score_reshape