干货 | 谷歌TensorFlow Extended 如何帮助开发者快速落地项目
作者简介
顾仁民,谷歌资深工程师,目前负责谷歌机器学习技术在国内的技术推广与企业合作。曾任谷歌展示广告系统研发团队主管,支撑国外若干大型网站的广告系统营收。
本文来自顾仁民在“2018携程技术峰会”上的分享。
一、身边的 TensorFlow 示例

上图是一副海洋区域内船只活动轨迹图,其中每个船的活动点都是一个亮点,可以看到人类在海洋区域的活动非常频繁。我们可以通过船只运行的轨迹了解到其深处的奥秘。
假如有一艘船运行的轨迹是转来转去的,而不是直接从 A 点开到 B 点,其实它是在捕鱼。我们根据这个轨迹可以判断出这艘船是货船或者是某一种特别的渔船,并用机器学习的方式来对船只的轨迹进行分类。

根据这一结论,我们可以进行进一步的环境保护的操作,从而保证鱼不会被过度捕捞。

除此之外,还有一些形象的示例,如关于保险公司商业策略:保险公司可以通过TensorFlow,针对一些比较容易发生事故的司机,特定地增加一定比率的保费。
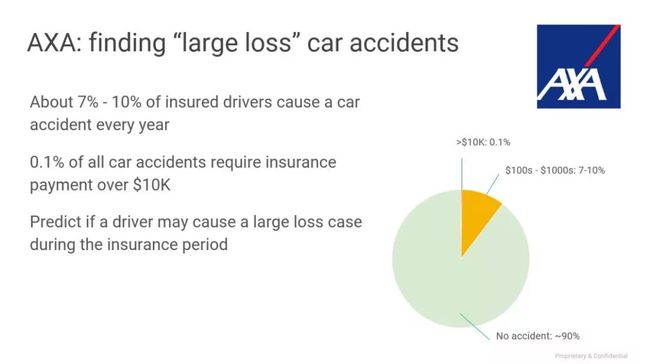
关于汽车拍卖定价:TensorFlow 可以帮助企业快速地通过图片完成汽车相关的各种车况检查,也包括理赔信息检查等。


上图中给出的是应用了 TensorFlow 的 Google 用例,如翻译、语音生成、医疗,以及节能等,他们有各自的意义,比如根据用户实际情况,节能用在数据中心最大可以节约 40% 。
二、一起进入 TensorFlow Extended 阶段
机器学习为我们带来了很多便利,但上面的三个示例具体应该如何实现呢?我们可以先想想机器学习的代码层面是什么样子。
用过 Keras 的工程师会比较清楚,它从代码上看比较简单。

再复杂一点的 Wide & Deep。可能大家很多时候需要做一个机器系统去做推荐工作,这个稍微有点复杂,但要实现这样一个模型要多少代码呢?
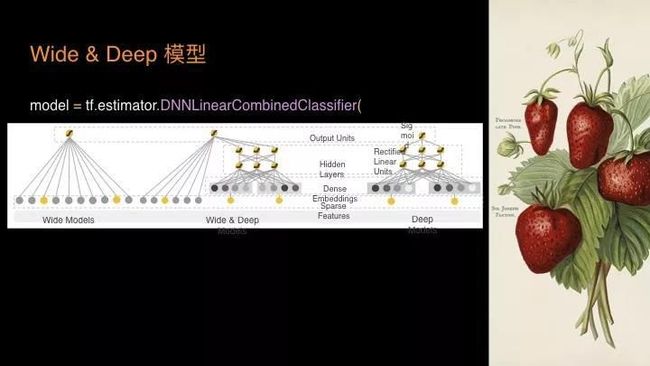
只有图中所示的这些,直接就可以上手了!所以,可以认为以往我们认为最难的机器学习核心部分的模型代码,实际上最终的量都比较小。

在机器学习里,我们非常关注模型代码,而 TensorFlow Extended ,不只是模型。
TensorFlow Extended 解决了哪些问题呢?前面提到,机器学习的代码很简单,但为了实现机器学习,开发者日常需要花费大量的人力在数据收集、配置、机器管理等各种各样的事情上,反而曾经认为最难的机器学习的模型代码部分是最简单的,那么这些需要花费外围力量的工作我们是必须铺人力去做,还是能够通过其他方式实现,从而让项目快速实施落地呢?


TensorFlow Extended 就是 Google 推出的一个能够帮助解决这些问题,帮助开发者实现快速实施落地项目的有效工具。

TensorFlow Extended 可以解决上图所列的一部分问题,虽然还有很多模块还没开源,但将会陆续开源出来,例如在上图中出现的最底层的储存层、管理层等工作。
TensorFlow Extended 可以分为四个部分。我们知道在机器学习中,有人工智能、机器学习、深度学习等多个概念,机器学习可以认为是数据驱动的智能,所以数据是非常重要的,它本质上是放入数据,产出模型,中间有些算法。
但如果数据是垃圾数据的话,出来的模型肯定也是有问题的。如果再加上迭代,用模型再去改进它获取新的数据,那相当于错上加错,所以这会进入一个恶性循环,效果会越来越差。

怎样防止这个问题?
要在第一步数据问题上做保证,这也是 TensorFlow Extended 的作用。举例说明它的作用:我们首先在 TensorFlow Extended 中收集一部分(比如一天)的数据,假设第一天数据可能有错,也可能是正确的,所以需要人工检查来确保无错,形成一个好的数据集,作为以后的参考。
怎样检查数据集是好还是坏?
一个方法是逐条查看,另一个方法是查看统计信息,此时,使用 TensorFlow Extended 可视化检查相对比较方便,能在下方看到它的最大值、最小值、均值、方差等相关统计信息。

人工检查信息后,我们还可以检查得更复杂一些。图中红色的部分能告诉我们哪些数据可能有问题,不一定真的有问题,但从统计的角度这些数据可能属于离群数据,是比较特别的数据,TensorFlow Extended 会提示人工进行更详细的检查。

待这些检查工作完成后,基本可以认为第一天的数据是比较干净、比较正确的。然后我们可以根据这个数据生成一个相对更固定的 schema ,形成刻划后的第一天的数据。当然还可以进一步细调这一 schema 并将之用在其他地方,如 TensorFlow 这个场景上。

解决好第一天的数据后,进入第二天,我们假设第二天的数据肯定是对的,但是有可能是特别的,这有两种情况:
第二天跟第一天不一样,模型需要调整。
第二天的数据是脏的。
怎样发现这个问题?
第二天的数据也可以生成 stats 数据,我们可以在 TensorFlow Extended 中把两天的数据合在一起,如将第一天和第二天的数据一起展现,来查看其均值、方差等各种指标是否匹配,如不匹配,说明第一天和第二天的数据在统计上的分布情况差异较大,则第一天训练的模型不太能用在第二天。我们也可以更详细的去查看很多可视化的解释。
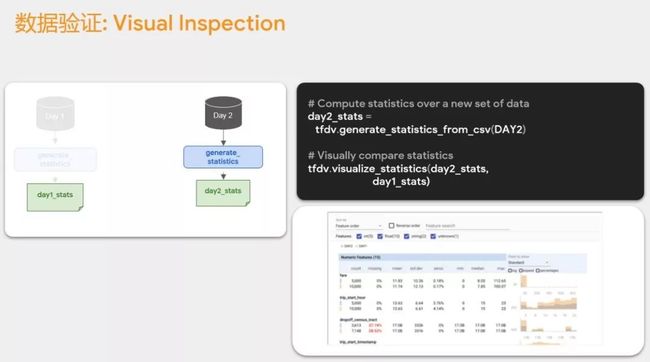
当查看完后,我们还要再进一步的看第一天和第二天是否还有较大的差异。除去可视化,如果想自动化这一过程,或不频繁看图表,该怎么办呢?用 stats 去检查差异性。比如,把第一天的 stats 和第二天的 stats 进行比较,如第一天统计出的值域是 0-100,第二天为120,说明最大化发生了变化,有可能发生了不太正常的事情。

接下来是 Data validation,有可能需要针对模型转换的数据、数据转换的数据,包括线上设定的数据等进行该工作, TensorFlow Extended 有多种处理方式可以完成这一验证。
数据整理完成后是 TensorFlow 中与机器学习相关的如分桶,或者一些 NLP 上做特征交叉的工作。
下面是 TensorFlow Extended 非常有用的一点,可能开发者使用单一模型不能解决所有的问题,需要用多个机器学习模型拼接起来才能解决一个大的问题。如做图象识别类、文本识别类的工作,第一步要建立一个检测模型,第二步做识别模型对行里做序列检测,接下来进入到机器学习核心代码部分去做训练。
此时开发者可能会面临一个问题:这个模型有可能是错的,或者说数据有可能还是错的,或者说这个模型定义是有问题的,没有表达出这个数据的一些特别的特征出来。此时,我们需要去做一些分析,要建立适合用来分析的版本,然后进入这个模块。
以一个典型的例子为例,刻划所做工作是否准确有几个指标,但这几个指标是针对所有测试集数据的宏观指标,它只能说明总体是怎么样的情况,就像一场考试,老师给给出的总分数,无法说明答题者选择题还是填空题做的好。如果我们知道哪一部分做的好、哪一部分做的不好,就可以针对做的不好的部分进行深挖,下次可以做的更好一点,这是 TensorFlow Extended 的一个重要功能,它可以告诉开发者更细致的信息。
下面有几个例子:
1)打车的场景,它可以体现上午比较好还是下午比较好,在高峰时间数据比较多,低谷时间数据比较小,我们可以用这样一个工具很快的去分析出到底哪些不对。
2)电商的场景,如果业务在大城市表现很好,但是在中小型城市表现不好,是不是中小型城市数据不够均匀,参数刻划的不够好等等问题,TensorFlow Extended 可以帮助你从数据切片的角度来分析到底哪些出了问题。
模型不可能一直不变,是要进行迭代更新的。迭代时,比如上个月的版本和本月的版本,两个模型是有差异的,原因可能是数据产生了变化,算法产生了变化,或者一些别的特殊的业务规则的变化等各种各样的原因。
这时如果能跟踪随着时间变化,这一机器学习小组的产出,或者说模型效果是越来越好,还是越来越不好,还是一直处于比较稳定的状态 —— 那将是比较好的情况。
我们可以从时间轴上跟踪多个版本来进行自动测试,到底这个系统的产出是不是一直变得更好,如果变得更好,我们可以看到哪个时间点开始变得更好了,可以总结出该时间段内做了怎样的工作使得模型变得好了,这样的话写报告给老板,这个工作做的意义;还有一种情形是昨天跑的很好,今天反而不好了,我们可以反思一下这段时间系统上线了什么东西,适当的调整模型或者修改特定的BUG,帮助我们第一时间找到模型哪里变得不好。
模型从时间、数据切片等角度效果都比较好之后,说明开发工作已经做得比较好了,需要考虑上线的问题。
上线我们保存为另一个更精简的版本,这时再用 TensorFlow 就可以直接部署使用了,当然部署的时候可以结合里面的一些工具直接进行部署等,这些资源管理类的开源框架都可以帮开发者完成一些事情。
我们现在提供两种部署方式,一种叫 gRPC,另一种是 RESTful。
所有东西做完之后要做一个回馈,日志是一个公司非常宝贵的资源,如果信息可以回馈到一开始最上面或者更上游一层,会有助于更良性的循环。
当然 TensorFlow Extended 在这里的开源可能还不够充分,但如果开发者可以结合自己公司已有的处理机制去做这些环节,再进入下一个迭代循环的话,可以帮助开发者第一时间去发现业务系统是不是发生了一些状况。
基本上走完整个流程后,便可以结合人工和自动的方式来确保机器学习整个处于一个良性的循环当中。这就是 TensorFlow Extended 体现出来的价值。

现在上图所示是 TensorFlow Extended 中已经开源的四个部分。还有更多的东西会陆续地开放,当然还会结合 TensorFlow 资源调度类的框架做一些更深度的整合。
TensorFlow Extended 能够在数据验证即转换,模型分析、部署上线等环节帮助开发者降低人力和投入的消耗,从而实现项目的快递实施落地,除此之外,TensorFlow 还在对日常开发中更多需要消耗大量人力及资源的模块进行改善和开发,并将之开源供开发者使用,希望开发者可以持续关注。
【推荐阅读】
《携程技术2018年度合辑》,送给爱学习的你
一张图带你了解携程码农们的2018
