模型剖析 | 如何解决业务运维的四大难题?
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~
本文由织云平台团队 发表于云+社区专栏

前言
作为业务运维,你是否经常会碰到这样的问题:
\1. 新业务上线,开发同学会对服务做性能测试,但是换一种机型后的性能如何?服务版本更新后性能是否发生变化?
\2. 节假日即将到来,某个业务预估用户活跃度提升2倍,但假日结束后只上升了0.5倍,提前扩容的资源白白浪费,如何解决?不同活动影响不同服务模块集群,如何分析?
\3. 某个业务下挂靠的服务模块几百个,如何分析出核心模块和旁路模块?
\4. 多地分布的业务,如何规划?
带着这些问题,我们来看一下腾讯SNG运维是如何通过业务画像来解决的。
通过分析模块性能数据(CPU,内存,IO等)、路由关系(上下游访问关系)、抓包关系(更底层的访问关系)、活动指标(节假日和压测演习带来的下游模块增长)得出业务画像。
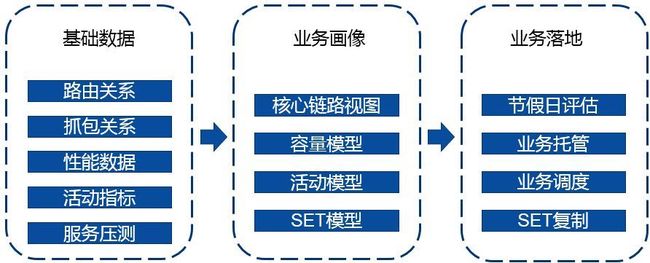
业务画像类型
业务画像包含了几个模型,用来解决上面的四个问题:
1. 容量模型:通过自动化压测不同配置,不同版本的TPS和其他性能瓶颈。发现异常,推动性能优化,数据
2. 活动模型:分析业务历史活动和关联模块的变化趋势,评估未来活动的变化趋势,解放人力,优化成本。
3. 链路核心视图:根据不同业务场景过滤出核心链路访问关系图,可用于告警收敛,根因分析,架构优化。
4. SET规划:业务条带化,多地分布,快速调度能力。
新业务上线,开发同学会对服务做性能测试,但是换一种机型后的性能如何?服务版本更新后性能是否发生变化?
容量画像:通过自动化压测系统,压测出服务在不同机型、不同版本的TPS阈值。通过阈值基准来自动化管理容量。基于TPS的容量管理相比传统的基于单机性能(CPU、内存等)的容量管理更精细。
举个很常见的例子,基于运维经验,单机CPU使用率超过80%时,我们会认为这台机器的负载很高,服务已经有超时的风险了,所以我们一般会在单机CPU使用率达到70%左右就开始扩容。
但是,实际上有很多服务在CPU使用率30%左右就已经出现大量超时,具体原因此文不细说。如果还是按传统的CPU使用率来评估,业务早已受影响。
TPS容量模型则很好的避免了这个问题,不同机型承载的TPS都有一个压测阈值,只需要评估当前模块下的TPS总量(服务框架自动上报),超过TPS阈值才触发扩容。扩容的设备量也是基于不同机型的TPS标准来自动评估。
支持自动上报TPS数据的标准服务框架我们使用TPS模型,剩余非标准框架,也可通过压测找出性能瓶颈,只是瓶颈指标从TPS变成了CPU/流量/或服务主被调次数。

节假日即将到来,某个业务预估用户活跃度提升2倍,但假日结束后只上升了0.5倍,提前扩容的资源白白浪费,如何解决?不同活动影响不同服务模块集群,如何分析?
活动画像:每个核心链路视图在每个活动周期内的容量增长幅度,都会被记录在活动模型内,用于评估后续活动的增长服务。
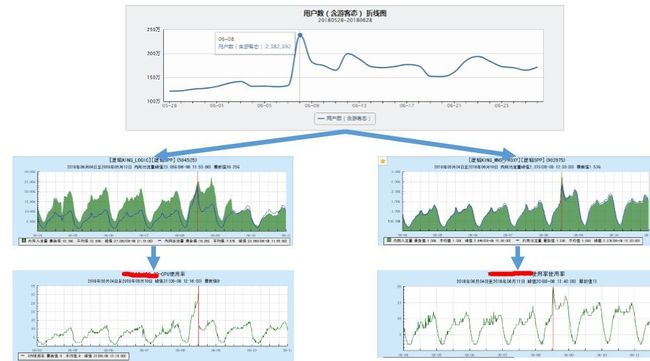
可以看到,某次活动带来的活跃用户数增长,不同模块的流量和CPU增长幅度都是不一样的。
活动模型会将每一次活动用户增长幅度和下游模块的流量、CPU、TPS增长幅度都保存下来用于支撑后续活动关联模块的容量评估。
介绍一个基于活动模型评估活动容量的基础模型:
活动关联模块,通过活动过程中产品指标和模块流量变化幅度分析得出
历史增长幅度:模块过去12个月活动对应产品指标的变化趋势
容量指标增长幅度:TPS、流量、CPU绝对使用核心数三个指标在活动期间的增长幅度。
CPU的评估专门提一下,容量增长幅度需要计算某个指标的绝对值,所以CPU的维度我们把CPU的使用率量化成了CPU绝对核心数。比如一个模块包含了N种机型,每种机型的CPU使用率都不一样,我们会这样算:
CPU_total_core=n∑1=A1_core*A1_CPU_average+…+An_core*An_CPU_average
结合上述三个维度,可以预估出最近一次活动对应模块的容量增长幅度,容量托管后台可根据容量预估结果制定不同的扩缩容或调度方案。
每一次活动评估结束后,需要对比现网真实数据和评估结果。差异超过20%的模块会被要求做二次分析,增加更多高级维度优化评估模型。比如模块业务场景维度,某些离线场景,我们会单独打标,使用专门的算法进行评估。
*某个业务下挂靠的服务模块几百个,如何分析出核心模块和旁路模块?*
核心链路视图
业界流行的链路视图方案是google dapper模型。但是体量庞大的社平业务因为历史原因,短期内将所有业务都增加上报各种链路节点信息是不现实的。
于是我们采用另外一种方法来实现核心链路视图的绘制:根据路由、抓包、主被调关系梳理出接入->逻辑->存储三层的完整调用关系链路。结合不同的场景,在完整关系链的基础上根据服务主被调次数,出入包量等指标做进一步过滤。最终得出业务核心关系链。
未经处理过的业务链路视图看起来是这样的:

经过抓包数量、主被调次数过滤后的核心业务链路视图是这样的:

核心链路视图可以用于告警关联分析,根因分析,活动实时大盘视图等业务场景。
*多地分布的业务,如何规划?*
SET规划
对于一些要求高可用低延迟的业务就可以通过业务画像来实现业务多地分布了。
SET画像包含了:
\1. 可视化视图:业务核心链路
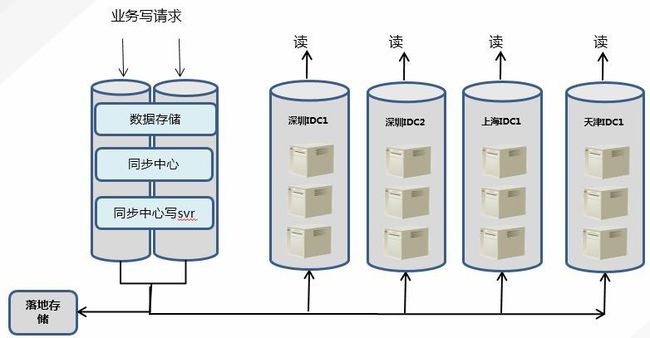
\2. 多地数据同步策略:这是SET画像的核心能力,对于多地分布的业务,难点就是如何实现多地数据一致。社交类业务形态主要是多读少些,我们使用单点写,多点读的策略规划多地分布架构。如图:所有的写请求都收归到深圳(因写入量相对少,跨地域访问的延时用户并无明显感知),深圳存储的数据通过同步中心同步到其他地域。所有的读请求都读本地存储。
\3. 可度量指标:核心业务指标(比如承载多少用户,上传多少张图片等)、达到对应指标时各模块的容量等维度。
拿空间业务举例:
业务目前主要分布在深圳、上海、天津三地,每个地域可以承载各1/3的用户接入,每个地域的SET容量维持在50%,当一地故障时,另外两地可以分别承载25%的用户。
根据核心链路内模块的不同功能分类,划分不同子功能SET。
根据同地域不同机房分类,划分不同子机房SET。
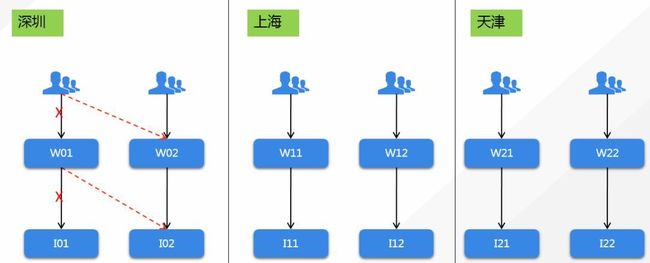
下图是空间基于SET画像的业务架构示例:用户通过手Q接入,在空间上层接入获取用户的读写操作,将读请求路由到本地,写请求路由到深圳SET。底层数据通过同步中心通过到异地。进而实现了空间的多地分布。
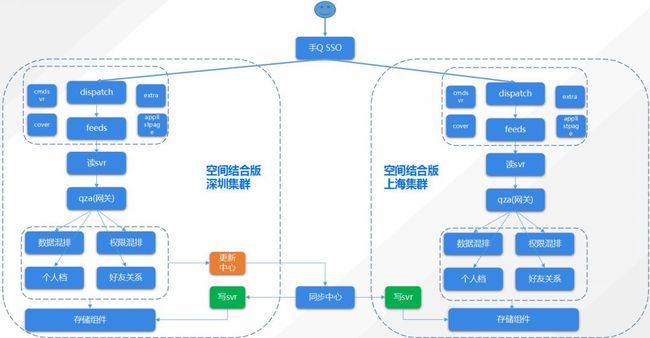
随着后端服务的不断迭代,SET核心指标也会不断变化,我们通过定期的SET调度演习来保证SET画像的准确性。演习过程中我们可以找出SET内瓶颈模块,提前修正模块容量。
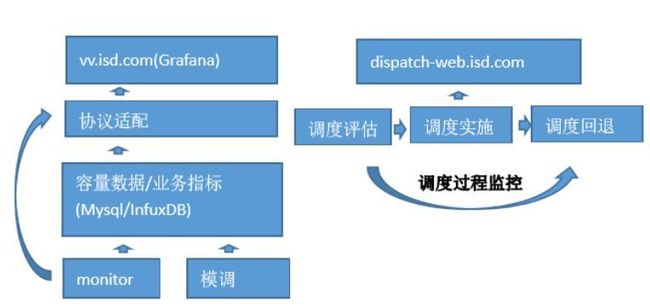
SET建调度的流量变化:

结语
业务画像的目的是将多年运维经验的沉淀成模型,自动化解决运维问题。
容量模型提供基础支撑数据到容量托管平台,上百个模块全自动扩缩容,容量稳定保持在45%左右。
活动模型智能预估业务活动期间各核心模块的容量变化趋势,提供预估结论到资源池,自动完成模块活动前扩容,活动后缩容,节约大量人力,预估准确率80%。
核心链路视图解决了社平业务复杂架构模型自动化梳理,目前统一告警ROOT平台使用核心链路视图做告警收敛以及根因分析。业务上云过程中,也会使用链路视图分析优化业务架构。
SET规划则主要解决了业务多地分布,持续保证业务高可用。业务多地分布,经历了天津机房爆炸,深圳光缆被挖断等大规模故障的检验。
业务画像随着业务的海量和多样化也在不断变化,同时也会根据运维需求沉淀出更多的业务画像。在处理日常的运维困难中,需要不断积累,多多关注业务的需求,善于总结。希望这些能够给大家带来一些启发。
问答
Angular2如何处理http响应?
相关阅读
HTTP/2之服务器推送(Server Push)最佳实践
如何备份你的MySQL数据库
MySQL 8.0 版本功能变更介绍
云学院 · 课程推荐 | 腾讯高级工程师,带你快速入门机器学习
此文已由作者授权腾讯云+社区发布,原文链接:https://cloud.tencent.com/developer/article/1184837?fromSource=waitui
搜索关注公众号「云加社区」,第一时间获取技术干货,关注后回复1024 送你一份技术课程大礼包!
海量技术实践经验,尽在云加社区!