Andrew Ng机器学习入门学习笔记(四)之神经网络(二)
本文主要记录了神经网络的代价函数,神经网络中梯度下降的用法,反向传播,梯度检验,随机初始化等理论,并附上课程作业中相关部分的matlab代码及注释。
有关神经网络的概念,模型,以及利用前向传播预测分类的计算可参看Andrew Ng机器学习入门学习笔记(四)之神经网络(一)
http://blog.csdn.net/scut_arucee/article/details/50144225
一.神经网络解决分类问题模型参数
m 组训练数据 (x(1),y(1)),(x(2),y(2)),⋯,(x(m),y(m)) ;
神经网络总的层数 L ;
第 l 层的单元数 Sl (不包括偏差单元);
输出层的单元数 K 。
①对于两类分类问题
y=0或1 ,只有一个输出单元, hΘ(x)∈R ,故 SL=1 ,即 K=1 。
②对于多类分类问题
y 是一个向量, y∈RK,hΘ(x)∈RK,SL=K(K⩾3) 。
二.神经网络的代价函数
1.正则化逻辑回归的代价函数
2.正则化神经网络的代价函数(以多类别分类为例)
定义 hθ(x)i 为 hθ(x) 的第 i ( 1⩽i⩽K )个输出,
逻辑回归中正则化的目的是让 θ 向量里的所有参数维持为较小的数;
神经网络中正则化则是让从输入层到输出层之间每两层的映射权重矩阵 Θ(l) 里的每一个元素都维持为较小的数,其中 Θ(l) 是一个 Sl+1∗(Sl+1) 维的矩阵;
对于上面的 λ2m∑L−1l=1∑Slj=1∑Sl+1i=1(Θ(l)ij)2 , l 用于控制层数,即 Θ(l) 是第 l 层到第 l+1 层的权重矩阵; i 用于控制 Θ(l) 当前所在的行; j 用于控制 Θ(l) 当前所在的列。注意这里 j 从 1 开始取,因为 Θ(l) 每一行的第一个元素( j=0 的列)都是偏差项,我们不正则化偏差项。
3.作业中代价函数求解代码
%为输入层添加偏置项
X = [ones(m,1) X];
%前向传播
z_2 = X*Theta1'; %m*25
a_2 = sigmoid(X*Theta1'); %m*25
a_2_new = [ones(m,1) a_2]; %为隐藏层添加偏置单元,m*26
h_x = sigmoid(a_2_new*Theta2');%m*10
%将y提供的1-10数字转化为神经网络输出的向量形式
Vec_y = zeros(m,num_labels);
for i = 1:m
Vec_y(i,y(i)) = 1;
end
%normal cost function(无正则化的代价函数)
J = -1/m*sum(sum(Vec_y.*log(h_x)+(1-Vec_y).*log(1-h_x)));
%regularized cost function(带有正则化的代价函数)
J = -1/m*sum(sum(Vec_y.*log(h_x)+(1-Vec_y).*log(1-h_x)))+lambda/2/m*(sum(sum(Theta1(:,2:end).^2))+sum(sum(Theta2(:,2:end).^2)));
作业中要实现的是数字识别,将20*20的图片展开成400个元素的向量,输入层带上偏置单元一共有401个单元,隐藏层带上偏置单元一共有26个单元,输出层10个单元。
计算代价函数之前,进行了一些处理,包括添加偏置单元,转换y的形式等等。为了计算代价函数需要使用的假设函数的输出,还进行了前向传播的计算。
三.神经网络中使用梯度下降
有了代价函数,接下来的目标就是 minΘJ(Θ) 。使用一些高级优化算法求解时,包括梯度下降,都需要我们自行给出 J(Θ) 和 ∂∂Θ(l)ijJ(Θ) 的代码。
为了计算 ∂∂Θ(l)ijJ(Θ) ,需要使用反向传播算法,在了解反向传播之前,首先要理解前向传播算法。
1.前向传播
给定一个输入,可以利用前向传播计算假设函数的输出。如下图:
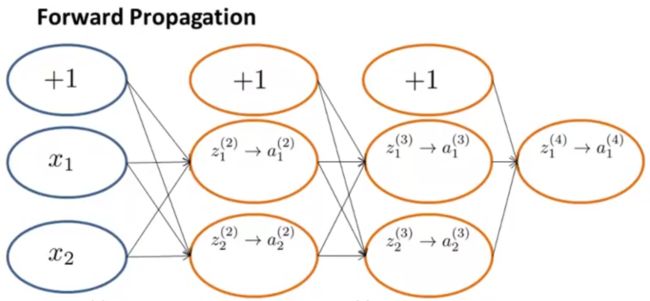
具体过程如下:
2.反向传播
对于每一个结点,需要计算 δ(l)j ,即第 l 层第 j 个结点的误差。如图:
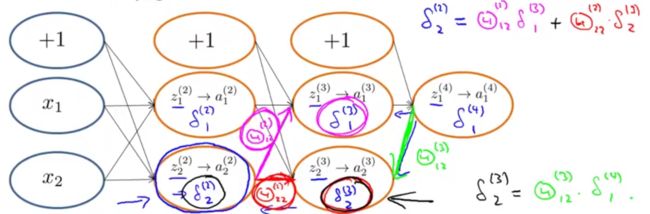
例如: δ(4)j=a(4)j−yj=hΘ(x)j−yj ,其中 a(4)j 是激励值, yj 是训练样本的真实值。
故
至于 g′(z(3)) 为什么等于 g(z(3)).∗(1−g(z(3))) ,可通过 g′() 是S型函数的导数自行推导。
这样由输出层的误差,反向传播,可以向前计算每一个隐藏层的误差。
最终我们可以得到代价函数偏导数项的表达(忽略正则化项,即 λ=0 ):
★ 整理一下利用前向传播和后向传播计算 ∂∂Θ(l)ijJ(Θ) 的过程:
①首先对于所有的 l,i,j ,令 Δ(l)ij=0 ( Δ是delta 的大写形式)
②for i = 1 to m
{
令 a(1)=x(i) ;
利用前向传播计算 a(l) ,其中 l=2,3,⋯,L ;
计算第 L 层(输出层)误差 δ(L)=a(L)−y(i) ;
利用反向传播计算 δ(L−1),δ(L−2),⋯,δ(2) (注意没有 δ(1) );
Δ(l)ij:=Δ(l)ij+a(l)jδ(l+1)i
}
③ D(l)ij:=⎧⎩⎨1mΔ(l)ij+λmΘ(l)ij1mΔ(l)ijj≠0j=0
④ ∂∂Θ(l)ijJ(Θ)=D(l)ij
其中for循环中的 Δ(l)ij:=Δ(l)ij+a(l)jδ(l+1)i 可以使用向量化实现,即 Δ(l):=Δ(l)+δ(l+1)(a(l))T 。
3.作业中利用前向传播和后向传播求解梯度的代码及注释
%初始化Delta
Delta2 = zeros(num_labels,size(a_2_new,2));
Delta1 = zeros(size(a_2_new,2)-1,size(X,2));
%利用前向传播和后向传播计算梯度
for i = 1:m
delta_3 = h_x(i,:)-Vec_y(i,:); %1*10
delta_3 = delta_3'; %10*1
delta_2 = Theta2'*delta_3.*sigmoidGradient([1;z_2(i,:)']); %26*1
delta_2 = delta_2(2:end); %25*1
Delta2 = Delta2+delta_3*a_2_new(i,:); %10*26
Delta1 = Delta1+delta_2*X(i,:); %25*401
end
D2 = 1/m*Delta2; %无正则化的梯度
D2(:,2:end) = D2(:,2:end)+lambda/m*Theta2(:,2:end); %带有正则化的梯度,10*26
D1 = 1/m*Delta1;%无正则化的梯度
D1(:,2:end) = D1(:,2:end)+lambda/m*Theta1(:,2:end); %带有正则化的梯度,25*401
Theta1_grad = D1;
Theta2_grad = D2;四.反向传播
反向传播到底在做什么呢?
考虑只有一个输出单元的情况,忽略正则化( λ=0 ),只关注单个训练样本 (x(i),y(i)) ,则
更正式一些说,对于 j⩾0 ,

如上图,反向传播也可解释为,由更深一层的误差和相关的权值可以计算出前一层的误差。
若已知输出层的误差为 δ(4)1 ,则
五.梯度检验
利用前面所说的前向传播和后向传播计算梯度时容易出现一些小错误而不被发现,这时候就需要进行梯度检验来检验我们计算的梯度是否是我们所需要的。
这里需要提出梯度的数值估计这个概念。
① θ∈R ,即为一个数而不是向量时,
② θ∈Rn ,即 θ 为向量参数时(例如 θ 是 Θ(1),Θ(2) 等的展开)
梯度数值估计实现代码如下:
numgrad = zeros(size(theta));
perturb = zeros(size(theta));
e = 1e-4;
for p = 1:numel(theta)
% Set perturbation vector
perturb(p) = e;
loss1 = J(theta - perturb);
loss2 = J(theta + perturb);
% Compute Numerical Gradient
numgrad(p) = (loss2 - loss1) / (2*e);
perturb(p) = 0;
end梯度检验代码如下:
% Evaluate the norm of the difference between two solutions.
% If you have a correct implementation, and assuming you used EPSILON = 0.0001
% in computeNumericalGradient.m, then diff below should be less than 1e-9
diff = norm(numgrad-grad)/norm(numgrad+grad);
fprintf(['If your backpropagation implementation is correct, then \n' ...
'the relative difference will be small (less than 1e-9). \n' ...
'\nRelative Difference: %g\n'], diff);梯度检验的实现要点(步骤):
1.使用后向传播计算DVec(偏导数向量)
2.计算数值梯度的估计值gradApprox
3.确保DVec和gradApprox值相近
4.关闭梯度检验,再使用后向传播进行学习
注意:在训练分类器之前一定要关闭梯度检验,如果没有关闭,则在梯度下降的每次迭代中都进行数值梯度的计算,代码运行将十分缓慢。梯度的数值估计相对于后向传播计算梯度来说是较大的工作量,我们使用数值估计的初衷仅仅是为了检验后向传播的实现是否正确。
六.随机初始化
运用梯度下降或者其他高级优化算法来求解 minΘJ(Θ) 时,需要对 Θ 进行初始化。
在逻辑回归中,我们可以将所有的 θ 初始化为一个全 0 的向量,但是在神经网络中我们不能这么做。
如果对于所有的 i,j,l,我们初始化Θ(l)ij=0 ,则
即,每次更新之后,从每个输入分别指向两个隐藏单元的权重是相同的,而且 a(2)1仍然等于a(2)2 。
当有多个隐藏单元时,这种情况相当于所有的隐藏单元只表示同一种特征,其他完全是多余的(实际上,只要初始的 θ 值都相同,就无法破坏这种可怕的对称性)。
故神经网络对权重采用随机初始化,来破坏这种对称性。让每一个 Θ(l)ij 为 [−ε,ε]中随机一个值 。(这里的 ε 和梯度检验里的 ε 不是同一个东西)
具体实现:
若 Θ∈Rm∗n ,则 Θ1=rand(m,n)∗(2∗INITEPSILON)−INITEPSILON
作业中有关随机初始化的代码:
W = zeros(L_out, 1 + L_in); %权重矩阵的维数
% ====================== YOUR CODE HERE ======================
% Instructions: Initialize W randomly so that we break the symmetry while
% training the neural network.
%
% Note: The first row of W corresponds to the parameters for the bias units
%
epsilon_init = 0.12;
W = rand(L_out, 1 + L_in) * 2 * epsilon_init - epsilon_init;七.神经网络总结
1.选择一个网络结构
输入层单元数:特征 x(i) 的维数
输出层单元数:分类的类别数。
(多类别分类问题输出层有多个单元,输出的 y 不是一个数了,而是由一些 0 和一个 1 组成的向量)
隐藏层数目:默认使用1个隐藏层,如果隐藏层数目多于1个,则每个隐藏层应该有相同的单元个数。
(隐藏层单元数越多,效果越好,通常取稍大于输入特征的数目)
2.训练神经网络
①构建以恶搞神经网络,对权重随机初始化
②对训练数据中任意 x(i) ,利用前向传播计算得到 hΘ(x(i))
③计算代价函数 J(Θ)
④利用反向传播计算偏导项 ∂∂Θ(l)ijJ(Θ)
可以使用for循环遍历每一个训练数据
{
利用前向传播得到激励 a(l) ,其中 l=2,3,⋯,L
利用反向传播得到误差项 δ(l) ,其中 l=2,3,⋯,L
Δ(l):=Δ(l)+δ(l+1)(a(l))T
}
D(l)ij:=⎧⎩⎨1mΔ(l)ij+λmΘ(l)ij1mΔ(l)ijj≠0j=0
∂∂Θ(l)ijJ(Θ)=D(l)ij
⑤使用梯度检验比较后向传播计算得到的 ∂∂Θ(l)ijJ(Θ) 和数值估计得到的 J(Θ) 的梯度是否接近,然后关闭梯度检验
⑥使用梯度下降或其他高级优化算法和反向传播相结合去求解 minΘJ(Θ) ,得到最优的参数 Θ
对于神经网络来说, J(Θ) 是非凸函数,使用梯度下降可能得到的不是全局最小值,但这影响不大,一般来说得到的会是很小的局部最小值。
3.神经网络对新的输入分类
对于新的输入 x ,结合训练出的权重 Θ ,利用前向传播得到输出层的 hΘ(x) ,给出分类结果。