library(tm)
library(ggplot2)
library(dplyr)
library(reshape2)
library(tidyr)
library(lubridate)
data.path<-'D:\\ML_for_Hackers-master\\03-Classification\\data\\'
easyham.path<-paste0(data.path,'easy_ham\\')
easyham.path
‘D:\ML_for_Hackers-master\03-Classification\data\easy_ham\’
提取邮件有用信息(发送者、主题、日期、内容等)
parse.email<-function(path){
full.msg<-msg.full(path)
date<-get.date(full.msg)
from<-get.from(full.msg)
subj<-get.subject(full.msg)
msg<-get.msg(full.msg)
return(c(date,from,subj,msg,path))
}
读取一封邮件
msg.full<-function(path){
con<-file(path,'r')
msg<-readLines(con,encoding='latin1')
close(con)
return(msg)
}
提取邮件地址
get.from<-function(msg.vec){
from<-msg.vec[grepl('From: ',msg.vec)]
from<-strsplit(from,'[":<> ]')[[1]]
from<-from[which(from != "" & from != " ")]
return(from[grepl('@',from)][1])
}
提取邮件正文
get.msg<-function(msg.vec){
msg <- msg.vec[seq(which(msg.vec == "")[1]+1,length(msg.vec))]
return(paste(msg,collapse='\n'))
}
提取邮件主题
get.subject<-function(msg.vec){
subj<-msg.vec[grepl('Subject: ',msg.vec)]
if(length(subj)>0){
return(strsplit(subj,'Subject: ')[[1]][2])
}
else{
return('')
}
}
邮件接收日期
get.date<-function(msg.vec){
date.grep<-grepl('^Date: ',msg.vec)
date.grep<-which(date.grep == TRUE)
date<-msg.vec[date.grep[1]]
date<-strsplit(date,'\\+|\\-|: ')[[1]][2]
date<-gsub('^\\s+|\\s+$','',date)
return(strtrim(date,25))
}
easyham.docs<-dir(easyham.path)
easyham.docs<-easyham.docs[which(easyham.docs!='cmds')]
easyham.parse<-lapply(easyham.docs,function(p) parse.email(paste0(easyham.path,p))) ## lapply函数分别对各个邮件进行处理
ehparse.matrix<-do.call(rbind,easyham.parse)
allparse.df<-data.frame(ehparse.matrix,stringsAsFactors=F)
names(allparse.df)<-c('Date','From.Email','Subject','Message','Path')
head(allparse.df[,1:3])
日期格式转化
date.converter<-function(dates,pattern1,pattern2){
pattern1.convert<-strptime(dates,pattern1)
pattern2.convert<-strptime(dates,pattern2)
pattern1.convert[is.na(pattern1.convert)]<-pattern2.convert[is.na(pattern1.convert)]
return(pattern1.convert)
}
Sys.setlocale("LC_TIME", "C")
pattern1 <- "%a,%d %b %Y %H:%M:%S"
pattern2 <- "%d %b %Y %H:%M:%S"
‘C’
head(priority.df[,c(1,2,3,5)])
|
Date |
From.Email |
Subject |
Path |
| 1061 |
2002-01-31 22:44:14 |
[email protected] |
please help a newbie compile mplayer :-) |
D:\ML_for_Hackers-master\03-Classification\data\easy_ham\01061.6610124afa2a5844d41951439d1c1068 |
| 1062 |
2002-02-01 00:53:41 |
[email protected] |
re: please help a newbie compile mplayer :-) |
D:\ML_for_Hackers-master\03-Classification\data\easy_ham\01062.ef7955b391f9b161f3f2106c8cda5edb |
| 1063 |
2002-02-01 02:01:44 |
[email protected] |
re: please help a newbie compile mplayer :-) |
D:\ML_for_Hackers-master\03-Classification\data\easy_ham\01063.ad3449bd2890a29828ac3978ca8c02ab |
| 1064 |
2002-02-01 10:29:23 |
[email protected] |
re: please help a newbie compile mplayer :-) |
D:\ML_for_Hackers-master\03-Classification\data\easy_ham\01064.9f4fc60b4e27bba3561e322c82d5f7ff |
| 1070 |
2002-02-01 12:42:02 |
[email protected] |
prob. w/ install/uninstall |
D:\ML_for_Hackers-master\03-Classification\data\easy_ham\01070.6e34c1053a1840779780a315fb083057 |
| 1072 |
2002-02-01 13:39:31 |
[email protected] |
re: prob. w/ install/uninstall |
D:\ML_for_Hackers-master\03-Classification\data\easy_ham\01072.81ed44b31e111f9c1e47e53f4dfbefe3 |
allparse.df$Date<-date.converter(allparse.df$Date,pattern1,pattern2)
allparse.df$Subject<-tolower(allparse.df$Subject)
allparse.df$From.Email<-tolower(allparse.df$From.Email)
选取前一半时间的数据(训练数据)进行测试
priority.df<-allparse.df[with(allparse.df,order(Date)),]
priority.train<-priority.df[1:(round(nrow(priority.df)/2)),]
计算各个发送者发送邮件的数量
from.weight<-select(priority.train,-Date) %>% group_by(From.Email) %>% summarise(Freq=length(Subject))
head(from.weight)
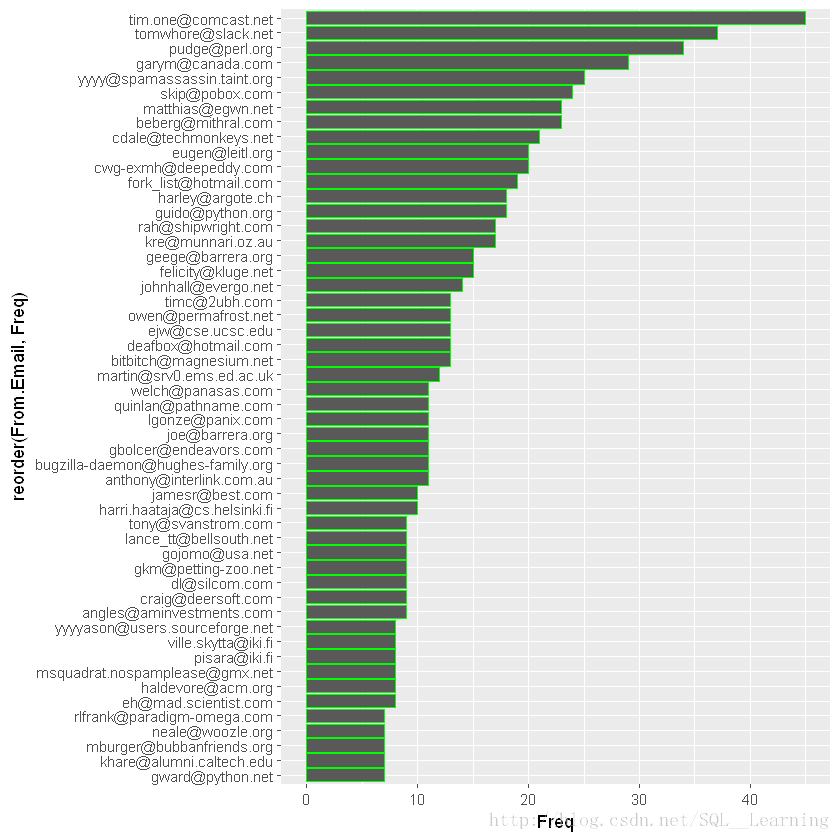
from.weight_map <-subset(from.weight,Freq>6)
from.weight_map<-from.weight_map[order(from.weight_map$Freq),]
tail(from.weight_map)
取次数大于6的数据画图
ggplot(from.weight_map,aes(x=reorder(From.Email,Freq),y=Freq))+geom_bar(stat="identity",color='green')+coord_flip()
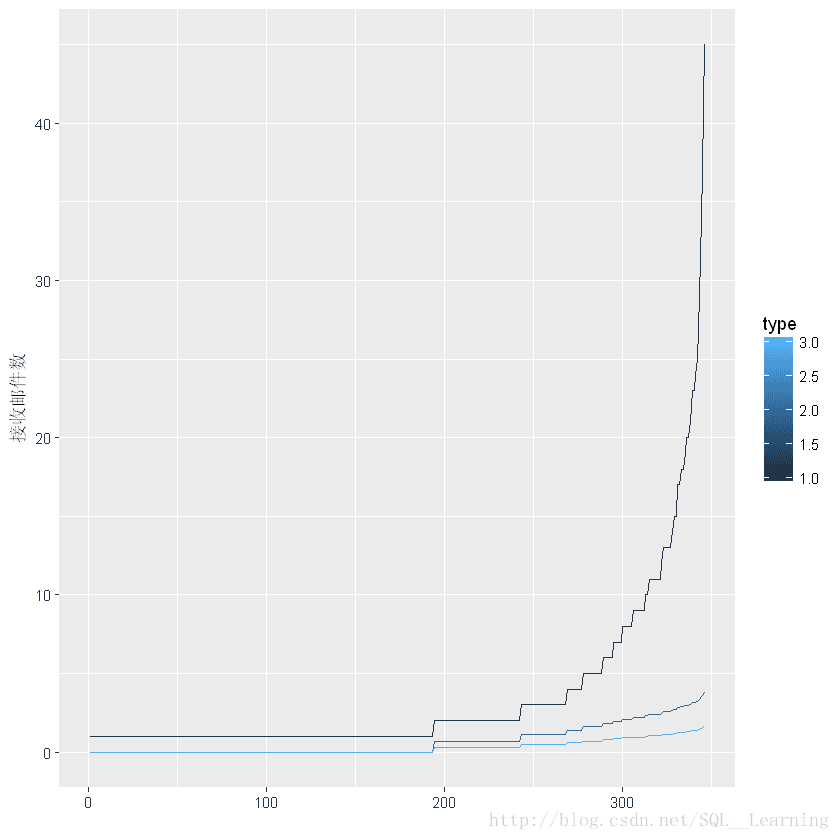
取不同对数类型的差异
test1<-data.frame(y=from.weight[order(from.weight$Freq),]$Freq,x=1:nrow(from.weight),type=rep(1,nrow(from.weight)))
test2<-data.frame(y=log(from.weight[order(from.weight$Freq),]$Freq),x=1:nrow(from.weight),type=rep(2,nrow(from.weight)))
test3<-data.frame(y=log10(from.weight[order(from.weight$Freq),]$Freq),x=1:nrow(from.weight),type=rep(3,nrow(from.weight)))
test<-rbind(test1,test2,test3)
ggplot(test,aes(x,y,color=type,group = type))+geom_line()+ylab('接收邮件数')+xlab('')
from.weight<-transform(from.weight,Weight=log(Freq+1))
找出回复他人的邮件
find.threads<-function(email.df){
response.threads<-strsplit(email.df$Subject,'re: ')
is.thread<-sapply(response.threads,function(subj) ifelse(subj[1]=='',TRUE,FALSE))
threads<-response.threads[is.thread]
senders<-email.df$From.Email[is.thread]
threads<-sapply(threads,function(t) paste(t[2:length(t)],collapse='re: '))
return(cbind(senders,threads))
}
threads.matrix<-find.threads(priority.train)
head(threads.matrix)
计算每个邮件回复他人的数量及构建权重
email.thread<-function(thread.matrix){
sender<-threads.matrix[,1]
senders.freq<-table(sender)
senders.matrix<-cbind(names(senders.freq),senders.freq,log(senders.freq+1))
senders.df<-data.frame(senders.matrix,stringsAsFactors=FALSE)
row.names(senders.df)<-1:nrow(senders.df)
names(senders.df)<-c('From.Email','Freq','Weight')
senders.df$Freq<-as.numeric(senders.df$Freq)
senders.df$Weight<-as.numeric(senders.df$Weight)
return(senders.df)
}
senders.df<-email.thread(threads.matrix)
head(senders.df)
计算同一主题的线程时间差,并赋值
get.threads<-function(threads.matrix,email.df){
threads<-unique(threads.matrix[,2])
thread.counts<-lapply(threads,function(t) thread.counts(t,email.df))
thread.matrix<-do.call(rbind,thread.counts)
return(cbind(threads,thread.matrix))
}
thread.counts<-function(thread,email.df){
thread.times<-email.df$Date[which(email.df$Subject==thread|email.df$Subject==paste('re:',thread))]
freq<-length(thread.times)
min.times<-min(thread.times)
max.times<-max(thread.times)
time.span<-as.numeric(difftime(max.times,min.times,units='secs'))
if(freq<2){
return(c(NA,NA,NA))
}
else{
trans.weight<-freq/time.span
log.trans.weight<-10+log(trans.weight,base=10)
return(c(freq,time.span,log.trans.weight))
}
}
thread.weights<-get.threads(threads.matrix,priority.train)
thread.weights<-data.frame(thread.weights,stringsAsFactors=FALSE)
names(thread.weights)<-c('Thread','Freq','Response','Weight')
thread.weights$Freq<-as.numeric(thread.weights$Freq)
thread.weights$Response<-as.numeric(thread.weights$Response)
thread.weights$Weight<-as.numeric(thread.weights$Weight)
thread.weights<-subset(thread.weights,is.na(thread.weights$Freq)==FALSE)
head(thread.weights)
| Thread |
Freq |
Response |
Weight |
| please help a newbie compile mplayer :-) |
4 |
42309 |
5.975627 |
| prob. w/ install/uninstall |
4 |
23745 |
6.226488 |
| http://apt.nixia.no/ |
10 |
265303 |
5.576258 |
| problems with ‘apt-get -f install’ |
3 |
55960 |
5.729244 |
| problems with apt update |
2 |
6347 |
6.498461 |
| about apt, kernel updates and dist-upgrade |
5 |
240238 |
5.318328 |
计算主题的词频
term.counts<-function(term.vec,control){
vec.corpus<-Corpus(VectorSource(term.vec))
vec.tdm<-TermDocumentMatrix(vec.corpus,control=control)
return(rowSums(as.matrix(vec.tdm)))
}
thread.terms<-term.counts(thread.weights$Thread,control=list(strpwords=stopwords()))
head(thread.terms)
-
compile
-
2
-
help
-
2
-
mplayer
-
2
-
newbie
-
2
-
please
-
2
-
install
-
2
thread.terms<-names(thread.terms)
term.weights<-sapply(thread.terms,function(t) mean(thread.weights$Weight[grepl(t,thread.weights$Thread,fixed=TRUE)])) ##计算存在关键词的主题的权重的均值
term.weights<-data.frame(list(Term=names(term.weights),Weight=term.weights),stringsAsFactors=FALSE,row.names=1:length(term.weights))
head(term.weights)
| Term |
Weight |
| compile |
5.803255 |
| help |
5.427126 |
| mplayer |
6.724644 |
| newbie |
5.444172 |
| please |
6.309005 |
| install |
5.977866 |
计算邮件内容的词频,并据此赋权重
msg.terms<-term.counts(priority.train$Message,control=list(stopwords=stopwords(),removePunctuation=TRUE,removeNumbers=TRUE))
msg.weights<-data.frame(list(Term=names(msg.terms),Weight=log(msg.terms,base=10)),stringsAsFactors=FALSE,row.names=1:length(msg.terms))
msg.weights<-subset(msg.weights,Weight>0)
head(msg.weights)
| Term |
Weight |
| anyway |
1.875061 |
| appreciated |
1.176091 |
| apt |
2.255273 |
| can |
3.077004 |
| directory |
2.056905 |
| document |
1.278754 |
最终的训练数据
head(from.weight) ##社交特征
head(senders.df) ##发件人在线程内的活跃度(re:)
head(thread.weights) ##线程(一个主题存在多个邮件)的活跃度
head(term.weights) ##活跃线程的词项
head(msg.weights) ##所有邮件共有词项
| Thread |
Freq |
Response |
Weight |
| please help a newbie compile mplayer :-) |
4 |
42309 |
5.975627 |
| prob. w/ install/uninstall |
4 |
23745 |
6.226488 |
| http://apt.nixia.no/ |
10 |
265303 |
5.576258 |
| problems with ‘apt-get -f install’ |
3 |
55960 |
5.729244 |
| problems with apt update |
2 |
6347 |
6.498461 |
| about apt, kernel updates and dist-upgrade |
5 |
240238 |
5.318328 |
| Term |
Weight |
| compile |
5.803255 |
| help |
5.427126 |
| mplayer |
6.724644 |
| newbie |
5.444172 |
| please |
6.309005 |
| install |
5.977866 |
| Term |
Weight |
| anyway |
1.875061 |
| appreciated |
1.176091 |
| apt |
2.255273 |
| can |
3.077004 |
| directory |
2.056905 |
| document |
1.278754 |
训练和测试排序算法
get.weights<- function(search.term,weight.df,term=TRUE){
if(length(search.term)>0){
if(term){
term.match<-match(names(search.term),weight.df$Term)
}
else{
term.match<-match(search.term,weight.df$Thread)
}
match.weights<-weight.df$Weight[which(!is.na(term.match))]
if(length(match.weights)<1){
return(1)
}
else{
return(mean(match.weights))
}
}
else{
return(1)
}
}
计算每封邮件的的权重(相乘)
rank.message<-function(path){
msg<-parse.email(path)
#Weighting based on message author return(c(date,from,subj,msg,path))
#First is just on the total frequency
from <- ifelse(length(which(from.weight$From.Email==msg[2]))>0,from.weight$Weight[which(from.weight$From.Email==msg[2])],1)
#Second is based on senders in threads ,and threads themselves
thread.from<-ifelse(length(which(senders.df$From.Email==msg[2]))>0,senders.df$Weight[which(senders.df$From.Email==msg[2])],1)
subj<-strsplit(tolower(msg[3]),'re: ')
is.thread<-ifelse(subj[[1]][1]=='',TRUE,FALSE)
if(is.thread){
activity<-get.weights(subj[[1]][2],thread.weights,term=FALSE)
}
else{
activity=1
}
#Next,weight based on terms
#Weight based on terms in threads
thread.terms <- term.counts(msg[3],control=list(stopwords=stopwords()))
thread.terms.weights<-get.weights(thread.terms,term.weights)
#Weight baesd term in all messages
msg.terms<-term.counts(msg[4],control=list(stopwords=stopwords(),removePunctuation=TRUE,removeNumbers=TRUE))
msg.weights<-get.weights(msg.terms,msg.weights)
#Calcuate rank by interacting all weights
rank <- prod(from,thread.from,activity,thread.terms.weights,msg.weights)##连乘
return(c(msg[1],msg[2],msg[3],rank))
}
训练集和测试集
##拆分训练集和测试集
train.paths<-priority.df$Path[1:(round(nrow(priority.df)/2))]
test.paths<-priority.df$Path[((round(nrow(priority.df)/2))+1):nrow(priority.df)]
训练数据集结果
train.ranks<-lapply(train.paths,rank.message)##计算评分
train.ranks.matrix<-do.call(rbind,train.ranks)
train.ranks.matrix<-cbind(train.paths,train.ranks.matrix,'TRAINING')
train.ranks.df<-data.frame(train.ranks.matrix,stringsAsFactors=FALSE)
names(train.ranks.df)<-c('Message','Date','From','Subj','Rank','Type')
train.ranks.df$Rank<-as.numeric(train.ranks.df$Rank)
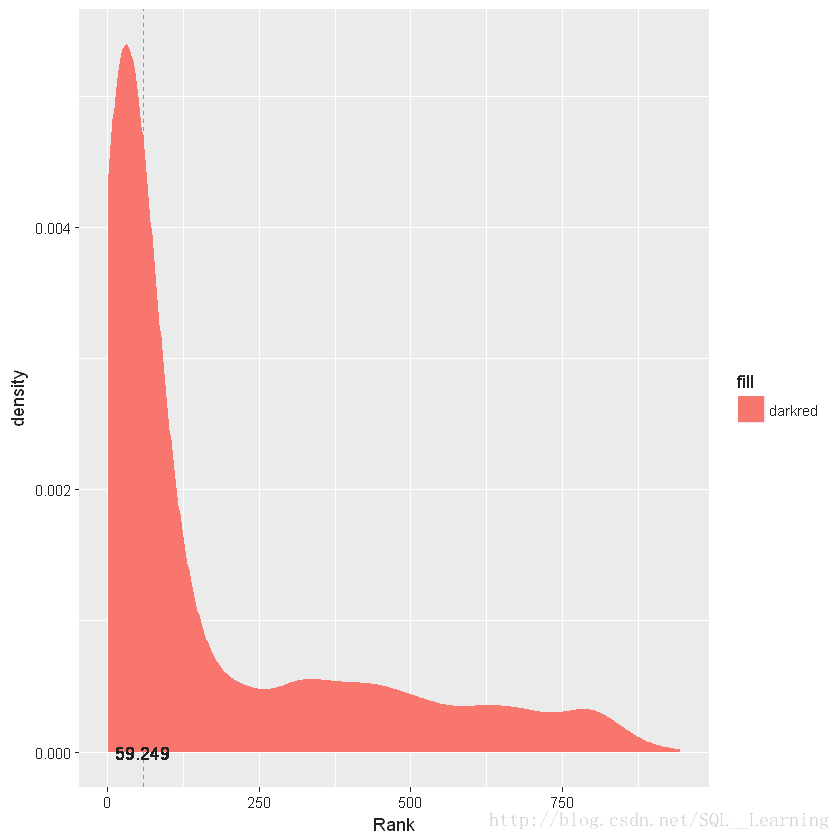
priority.threshold<-median(train.ranks.df$Rank)##评分的中位数
train.ranks.df$Priority<-ifelse(train.ranks.df$Rank>=priority.threshold,1,0)
train.ranks.df$Date<-date.converter(train.ranks.df$Date,pattern1,pattern2)
nrow(priority.df)
2500
train.ranks.df[15,]
|
Message |
Date |
From |
Subj |
Rank |
Type |
Priority |
| 15 |
D:\ML_for_Hackers-master\03-Classification\data\easy_ham\01078.e83af8e93466283be2ba03e34854682e |
2002-02-02 08:11:08 |
[email protected] |
Re: problems with ‘apt-get -f install’ |
371.1476 |
TRAINING |
1 |
priority.threshold
59.2488866334203
ggplot(train.ranks.df,aes(x=Rank))+stat_density(aes(fill="darkred"))+geom_vline(aes(xintercept=priority.threshold),color="green",linetype="dashed")+geom_text(aes(x=priority.threshold,y=0,label=round(priority.threshold,3)))
sd(train.ranks.df$Rank)
227.684723068453
测试数据集
test.ranks<-lapply(test.paths,rank.message)##计算评分
test.ranks.matrix<-do.call(rbind,test.ranks)
test.ranks.matrix<-cbind(test.paths,test.ranks.matrix,'TEST')
test.ranks.df<-data.frame(test.ranks.matrix,stringsAsFactors=FALSE)
names(test.ranks.df)<-c('Message','Date','From','Subj','Rank','Type')
test.ranks.df$Rank<-as.numeric(test.ranks.df$Rank)
test.ranks.df$Date<-date.converter(test.ranks.df$Date,pattern1,pattern2)
head(test.ranks.df)
| Message |
Date |
From |
Subj |
Rank |
Type |
| D:\ML_for_Hackers-master\03-Classification\data\easy_ham\00696.767a9ee8575785978ea5174d3ad3ee26 |
2002-09-21 19:13:52 |
[email protected] |
Re: sed /s/United States/Roman Empire/g |
573.38792 |
TEST |
| D:\ML_for_Hackers-master\03-Classification\data\easy_ham\00697.edd28212eb2b368046311fd1918aae7d |
2002-09-21 20:37:43 |
[email protected] |
E-Textiles Come into Style |
16.69912 |
TEST |
| D:\ML_for_Hackers-master\03-Classification\data\easy_ham\00698.09cdefd75c1242540db1183f9fc54461 |
2002-09-21 22:59:23 |
[email protected] |
flavor cystals |
13.14839 |
TEST |
| D:\ML_for_Hackers-master\03-Classification\data\easy_ham\00702.bf064c61d1ba308535d0d8af3bcb1789 |
2002-09-22 03:00:48 |
[email protected] |
Re: Oh my… |
97.93984 |
TEST |
| D:\ML_for_Hackers-master\03-Classification\data\easy_ham\00699.29e599983f044aee500f3a58c34acffc |
2002-09-22 03:13:08 |
[email protected] |
Re: sed /s/United States/Roman Empire/g |
453.67502 |
TEST |
| D:\ML_for_Hackers-master\03-Classification\data\easy_ham\00700.7eee792482a5a8cf20f1e4225f905f6b |
2002-09-22 03:20:22 |
[email protected] |
[vox] Anarchist ‘Scavenger Hunt’ Raises D.C. Police Ire (fwd) |
22.28577 |
TEST |
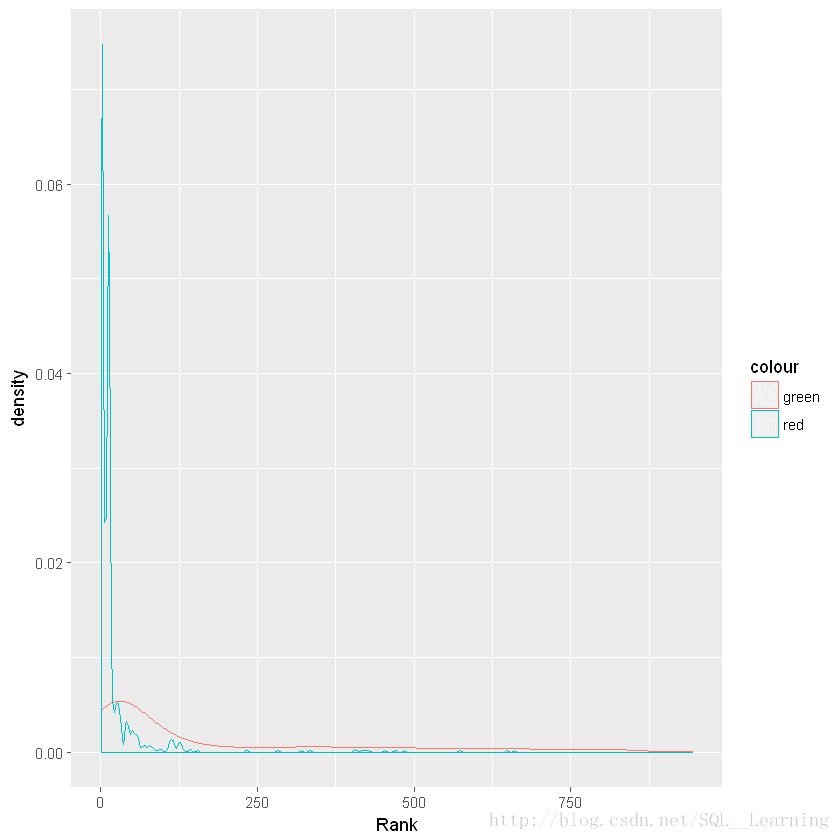
ggplot(train.ranks.df,aes(x=Rank))+geom_density(aes(color='green'))+geom_density(data=test.ranks.df,aes(x=Rank,color='red'))
列出排序靠前的40个
reslut <-test.ranks.df[order(test.ranks.df$Rank,decreasing=TRUE),][1:40,c(2,3,4,5)]
row.names(reslut)<-1:nrow(reslut)
reslut