ElasticSearch的安装与简单使用
一、ElasticSearch
1.作用
是零配置和完全免费的搜索模式,使用JSON/XML通过HTTP的索引数据,搜索服务器始终可用,能够从一台开始并在需要扩容时方便地扩展到数百,需要实时搜索,可以简单的多租户,能建立一个云的解决方案。
2.简介(简称ES)
(1)ES的索引库管理支持依然是基于Apache Lucene™的开源搜索引擎。
(2)ES也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
(3)ES的核心不在于Lucene,其特点更多的体现为:
分布式的实时文件存储,每个字段都被索引并可被搜索
分布式的实时分析搜索引擎
可以扩展到上百台服务器,处理PB级结构化或非结构化数据
高度集成化的服务,你的应用可以通过简单的 RESTful API、各种语言的客户端甚至命令行与之交互。
二、ES安装
ES服务只依赖于JDK,推荐使用JDK1.7+。
1.下载ES安装包
官方下载地址:https://www.elastic.co/downloads/elasticsearch
2.运行ES

3. 验证
访问:http://localhost:5601
看到上图信息,恭喜你,你的ES集群已经启动并且正常运行.
4.辅助管理工具Kibana5
① Kibana5.2.2下载地址:https://www.elastic.co/downloads/kibana
② 解压并编辑config/kibana.yml,设置elasticsearch.url的值为已启动的ES
③ 启动Kibana5 : bin\kibana.bat

④ 默认访问地址:http://localhost:5601
Discover:可视化查询分析器
Visualize:统计分析图表
Dashboard:自定义主面板(添加图表)
Timelion:Timelion是一个kibana时间序列展示组件(暂时不用)
Dev Tools :Console(同CURL/POSTER,操作ES代码工具,代码提示,很方便)
Management:管理索引库(index)、已保存的搜索和可视化结果(save objects)、设置 kibana 服务器属性。
三.ES数据管理
1.ES中的文档
一个文档不只有数据。它还包含元数据(metadata)—关于文档的信息。三个必须的元数据节点是:

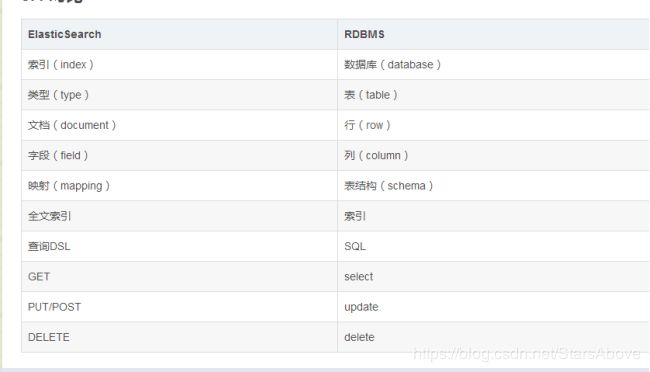
_index:索引库,类似于关系型数据库里的“数据库”—它是我们存储和索引关联数据的地方。
_type:在应用中,我们使用对象表示一些“事物”,例如一个用户、一篇博客、一个评论,或者一封邮件。可以是大写或小写,不能包含下划线或逗号。我们将使用 employee 做为类型名。
_id:与 _index 和 _type 组合时,就可以在ELasticsearch中唯一标识一个文档。当创建一个文档,你可以自定义 _id ,也可以让Elasticsearch帮你自动生成。
另外还包括:_uid文档唯一标识(_type#_id)
_source:文档原始数据
_all:所有字段的连接字符串
2.文档的增删改
#创建库
PUT crm
#创建表(user:表名,1:Id)
POST crm/user/1
{
"id":1,
"name":"kd",
"age":12
}
#不设置Id,系统或默认给一个("_id": "AWbkfwMyBAt03SeUh9o5",)
POST crm/user
{
"id":1,
"name":"kd",
"age":18
}
#查询所有属性
GET crm/user/1
#删除
DELETE crm/user/1
#修改
PUT crm/user/1
{
"id":1,
"name":"kd",
"age":18
}
#查询详情
GET crm/user/1/_source
GET crm/user/1?_source=name,age
#局部更新文档
POST crm/user/1/_update
{
"doc":{
"id":1,
"name":"kd",
"age":20,
"bothday":"2018-01-01"
}
}
#脚本更新文档
POST crm/user/1/_update
{
"script":"ctx._source.age+=1"
}
#查询所有
GET _search
#查询指定表中的所有数据
GET crm/user/_search
3批量获取
#批量操作
POST _bulk
{ "delete": { "_index": "itsource", "_type": "employee", "_id": "123" }}
{ "create": { "_index": "itsource", "_type": "blog", "_id": "123" }}
{ "title": "我发布的博客" }
{ "index": { "_index": "itsource", "_type": "blog" }}
{ "title": "我的第二博客" }
#查询测试
GET itsource/user/123
#批量获取
#方式1
GET _mget
{
"docs" : [
{
"_index" : "itsource",
"_type" : "blog",
"_id" : 123
},
{
"_index" : "itsource",
"_type" : "employee",
"_id" : 123,
"_source": ["title"]
}
]
}
#方式2
GET itsource/blog/_mget
{
"ids" : [ "123", "123" ]
}
3.空搜索
没有指定任何的查询条件,只返回集群索引中的所有文档: GET _search
4.分页搜索
GET crm/user/_search?size=5
5.查询字符串搜索
GET crm/user/_search?q=age:12
4.DSL查询与过滤
#准备数据:crm/user/1-7(相应id改为1-7),年龄在随便写,gj:国家(cm假设为中国)
POST crm/user/7
{
"id":7,
"name":"kd",
"age":46,
"gj":"cm"
}
#查询名字kd 中国的 年龄[18-50] 分页 0-2 排序 最大前面 age降序
GET crm/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "kd"
}
}
],
"filter":[
{
"term":{"gj":"cm"}
},{
"range":{
"age":{
"gte":"18",
"lte":"50"
}
}
}
]
}
},
"size": 2,
"from": 0,
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
5.分词与映射
(1)分词器
#ik分词器
POST _analyze
{
"analyzer": "ik_max_word",
"text": "网络小说热门搜索在这里哦"
}
(2)简单类型映射
字段映射的常用属性配置列表
type 类型:基本数据类型,integer,long,date,boolean,keyword,text...
enable 是否启用:默认为true。 false:不能索引、不能搜索过滤,仅在_source中存储
boost 权重提升倍数:用于查询时加权计算最终的得分。
format 格式:一般用于指定日期格式,如 yyyy-MM-dd HH:mm:ss.SSS
ignore_above 长度限制:长度大于该值的字符串将不会被索引和存储。
ignore_malformed 转换错误忽略:true代表当格式转换错误时,忽略该值,被忽略后不会被存储和索引。
include_in_all 是否将该字段值组合到_all中。
_all : 虚拟字段,每个文档都有该字段,代表所有字段的组合信息,作用方便直接对整个文档的所有信息进行搜索。
{id:1,name:zs,age:20,_all:1,zs,20}
null_value 默认控制替换值。如空字符串替换为”NULL”,空数字替换为-1
store 是否存储:默认为false。true意义不大,因为_source中已有数据
index 索引模式:analyzed (索引并分词,text默认模式), not_analyzed (索引不分词,keyword默认模式),no(不索引)
analyzer 索引分词器:索引创建时使用的分词器,如ik_smart,ik_max_word,standard
search_analyzer 搜索分词器:搜索该字段的值时,传入的查询内容的分词器。
fields 多字段索引:当对该字段需要使用多种索引模式时使用。
如:城市搜索New York
"city": {
"type": "text",
"analyzer": "ik_smart",
"fields": {
"raw": {
"type": "keyword"
}
}
}
那么以后搜索过滤和排序就可以使用city.raw字段名
POST crm/user/_mapping
{
"user": {
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
}
}
}
}
2.全局映射
#全局映射
PUT _template/global_template
{
"template": "*",
"settings": { "number_of_shards": 1 },
"mappings": {
"_default_": {
"_all": {
"enabled": false
},
"dynamic_templates": [
{
"string_as_text": {
"match_mapping_type": "string",
"match": "*_txt",
"mapping": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
{
"string_as_keyword": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}}
四.Java API
1.什么是Java API
ES对Java提供一套操作索引库的工具包,即Java API。所有的ES操作都使用Client对象执行。
(1)创建maven项目
(2)ES的Maven引入

org.elasticsearch.client
transport
5.2.2
org.apache.logging.log4j
log4j-api
2.7
org.apache.logging.log4j
log4j-core
2.7
junit
junit
4.12
test
2.连接ES获取Client对象

/*获取客户端
*/
public static TransportClient getClient() throws Exception {
TransportClient client = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("localhost"), 9300));
return client;
}
3.索引API
(1)创建文档索引
/* 获取索引数据
*/
@Test
public void getIndex() throws Exception {
// 获取客户端的es对象
TransportClient client = getClient();
// get 获取索引库的数据 id
GetResponse getResponse = client.prepareGet("crm", "user", "5").get();
// 响应的对象
System.out.println(getResponse.getSource());
// 关闭资源
client.close();
}
(2)添加文档
//增加
@Test
public void getCreate() throws Exception {
// 获取客户端的es对象
TransportClient client = getClient();
IndexRequestBuilder indexRequestBuilder = client.prepareIndex("crm", "user", "1");
Map map=new HashMap();
map.put("id",1);
map.put("name","zhangsan");
map.put("age",20);
IndexResponse indexResponse = indexRequestBuilder.setSource(map).get();
System.out.println(indexResponse);
// 关闭资源
client.close();
}
(3)删除文档
//删除
@Test
public void getDELETE() throws Exception {
//获取客户端的es对象
TransportClient client = getClient();
DeleteResponse deleteResponse = client.prepareDelete("crm", "user", "1").get();
System.out.println(deleteResponse);
//关闭资源
client.close();
}
(4)修改文档
//修改(在没对用id的时候后报错)
@Test
public void getUpdate() throws Exception {
//获取客户端的es对象
TransportClient client = getClient();
Map map=new HashMap();
map.put("id",3);
map.put("name","lisi");
map.put("age",28);
UpdateResponse updateResponse = client.prepareUpdate("crm", "user", "1").setDoc(map).get();
System.out.println(updateResponse);
//关闭资源
client.close();
}
//修改(如果没有对应修改的id,先创建再修改)
@Test
public void getsaveUpdate() throws Exception {
// 获取客户端的es对象
TransportClient client = getClient();
Map map=new HashMap();
map.put("id",3);
map.put("name","wangwu");
map.put("age",66);
IndexRequest indexRequest = new IndexRequest("crm", "user", "6")
.source(map);
UpdateRequest updateRequest = new UpdateRequest("crm", "user", "6")
.doc(map).upsert(indexRequest);
client.update(updateRequest).get();
// 关闭资源
client.close();
}
(5)批量操作
//批量操作
@Test
public void getbulk() throws Exception {
//获取客户端的es对象
TransportClient client = getClient();
//批量请求的对象
BulkRequestBuilder bulkRequest = client.prepareBulk();
for (int i = 0; i <10 ; i++) {
Map map=new HashMap();
map.put("id",i);
map.put("name","kd"+i);
map.put("age",18+i);
map.put("class",1);
bulkRequest.add(client.prepareIndex("crm", "user", i+"")
.setSource(map));
}
// 提交请求
BulkResponse bulkResponse = bulkRequest.get();
if (bulkResponse.hasFailures()) {
//处理错误
System.out.println("error");
}
// 关闭资源
client.close();
}
(6)搜索
//搜索
@Test
public void getsearch() throws Exception {
//获取客户端的es对象
TransportClient client = getClient();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//匹配
List must = boolQueryBuilder.must();
must.add(QueryBuilders.termQuery("class","1"));
//搜索:过滤 age 22-30/分页 0,2/sort id desc
//过滤
List filter = boolQueryBuilder.filter();
filter.add(QueryBuilders.rangeQuery("age").gte(22).lte(30));
// 设置分页 排序
SearchResponse searchResponse = client.prepareSearch("crm").setFrom(0).setSize(2).setQuery(boolQueryBuilder).addSort("id", SortOrder.DESC).get();
System.out.println("总条数:"+searchResponse.getHits().getTotalHits());
SearchHit[] hits = searchResponse.getHits().getHits();
// 循环数据结构
for (SearchHit hit : hits) {
System.out.println(hit.getSource());
}
// 关闭资源
client.close();
}