论文浅尝 | 推荐系统的可解释性浅谈


References:
Explainable Recommendation via Multi-Task Learning in Opinionated Text Data
Published at: The 41st International ACM SIGIR Conference on Research andDevelopment in Information Retrieval (SIGIR 2018)
URL:https://dl.acm.org/citation.cfm?id=3210010
Improving Sequential Recommendation with Knowledge-Enhanced Memory Networks
Published at: The 41st International ACM SIGIR Conference on Research andDevelopment in Information Retrieval (SIGIR 2018)
URL:https://dl.acm.org/citation.cfm?id=3210017
Motivation
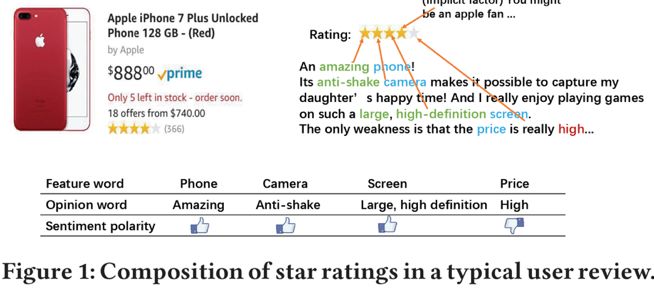
推荐系统可以为用户(user)推荐其感兴趣的内容并给出个性化的建议。而现在的推荐大都着眼于被推荐对象(item)的序列建模,而忽略了它们细粒度的特征(feature)。通过对推荐结果的解释,分析被推荐对象的特征,可以让用户可以对使用哪些推荐结果做出更明智,更准确的决策,从而提高他们的满意度。本文将以两篇介绍可解释的推荐系统论文为基础,分别从两个方面阐述在推荐系统中引入item的特征并提供可解释性。
MTER Model:Multi-Task Explainable Recommendation
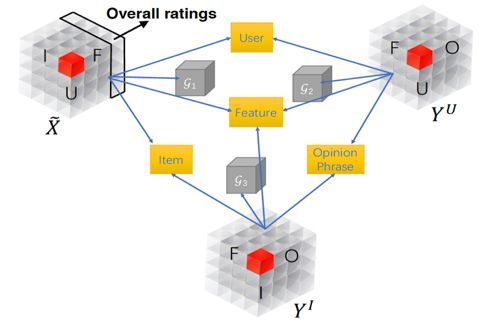
MTER模型从用户评论(opinionated content)中提取item细粒度的个性化特征,如下图所示。论文提出了一个用于可解释推荐任务的多任务学习方法,通过联合张量分解将用户(user)、产品(item)、特征(feature)和观点短语(opinionated phrase)映射到同一向量空间。
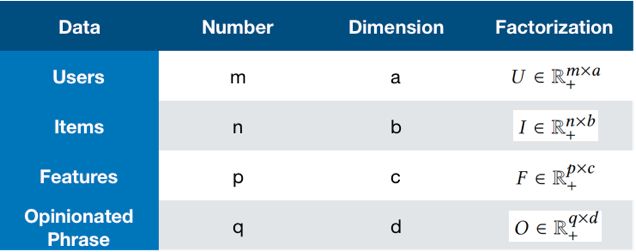
模型中用到的主要变量如下表所示。
用户i的评论、对产品j的评论,分别被表示成 R_i^U , R_j^I。
领域特定的情感词汇表示成, 即(特征,观点短语,情感极性),不过因为这里不是本文的重点,所以这里的具体处理方法作者没有赘述。
MTER模型主要分成3部分:item推荐的用户偏好建模、用于解释的用户评论建模以及通过联合张量分解的多任务学习。
1. item推荐的用户偏好建模
本文用三维张量建模![]() 建模,
建模,![]() 表示用户i对item j的特征k的欣赏程度。假设itemj的特征k被用户i提及了 t_ijk 次,而且每次的情感极性标签为
表示用户i对item j的特征k的欣赏程度。假设itemj的特征k被用户i提及了 t_ijk 次,而且每次的情感极性标签为![]() ,那么可以计算出特征值
,那么可以计算出特征值![]() 。此外,为了在每个用户的偏好建模张量中加入总体的评级矩阵
。此外,为了在每个用户的偏好建模张量中加入总体的评级矩阵![]() ,将原始的三维张量修改成
,将原始的三维张量修改成![]() 。这样张量
。这样张量![]() 就可以刻画用户、item、特征之间的关联度。计算方式为:
就可以刻画用户、item、特征之间的关联度。计算方式为:
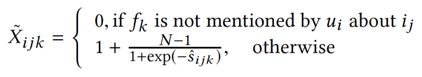
然后对其进行Tucker分解,加上非负性约束。这里的非负性约束刚好可以对应评级时的非负分数。Tucker分解就是将一个三维张量分解成三个因子矩阵和一个核张量,这个核张量![]() 可以刻画不同张量中的各个元素彼此交互的程度。
可以刻画不同张量中的各个元素彼此交互的程度。
这样用户、item、特征之间的关联度就可以被预测成
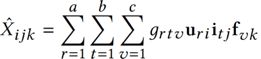
但是Tucker分解是按位进行优化,对于推荐来说,更需要解决的是评级的问题,所以引入基于贝叶斯后验优化的个性化排序算法(BPR)来进行按对优化。![]() 反映的是
反映的是![]() 的按对排列结果,BPR优化的原则就是
的按对排列结果,BPR优化的原则就是

这样![]() 就可以被优化成
就可以被优化成![]() 。
。
2. 用于解释的用户评论建模
用户评论建模涉及到4类对象:用户、item、特征、评价短语。本来应该建模成4维张量,但是由于数据稀疏的原因,这里建模成2个3维张量:基于用户的评价张量![]() 、基于item的评价张量
、基于item的评价张量![]() 。这里选出的评价都是情感极性为正的。计算方式为:
。这里选出的评价都是情感极性为正的。计算方式为:
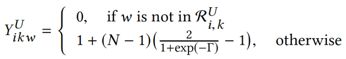
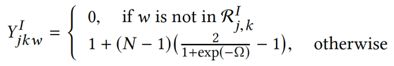
这样评论观点短语的评分向量就可以表示为![]() 。
。
3. 通过联合张量分解的多任务学习
形象化地展示多任务学习的联合张量分解:
这里的联合张量就利用到Tucker分解中核张量的特性:可以捕获潜在因素之间的多变量相互作用; 并且可以将主成分矩阵视为所得潜在空间的基础。所以通过(1)共享主成分矩阵![]() ,来学习两个任务中用户,item,特征和意见短语的潜在表示,(2)为每个任务的张量保持独立的核心张量,以捕获任务的内在差异和共享潜在因素的规模。
,来学习两个任务中用户,item,特征和意见短语的潜在表示,(2)为每个任务的张量保持独立的核心张量,以捕获任务的内在差异和共享潜在因素的规模。
优化函数为:
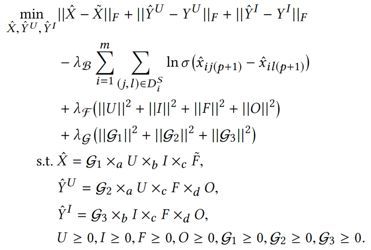
4. Experiments
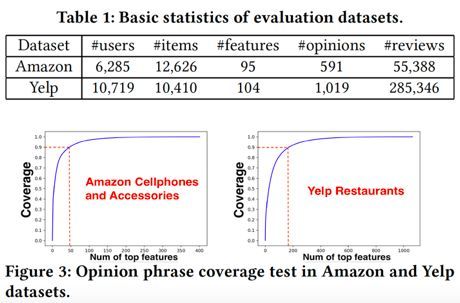
数据集
这篇文章的数据来自Amazon和Yelp,作者还分析了数据集的收敛性。
实验结果
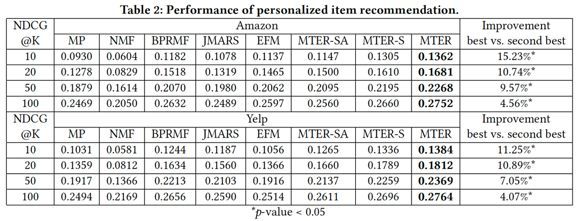
实验用的评价指标是NDCG。
对比实验结果如下表所示。
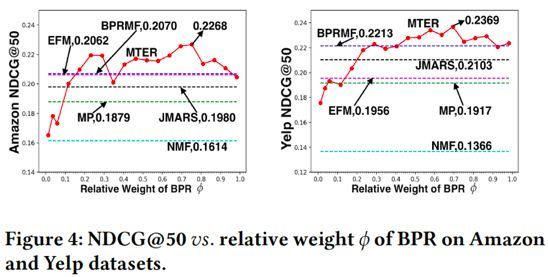
调整联合张量分解的权重系数对实验结果的影响:
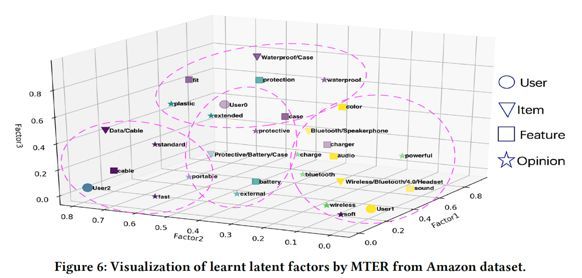
可解释性的实验(基于用户评价的解释)
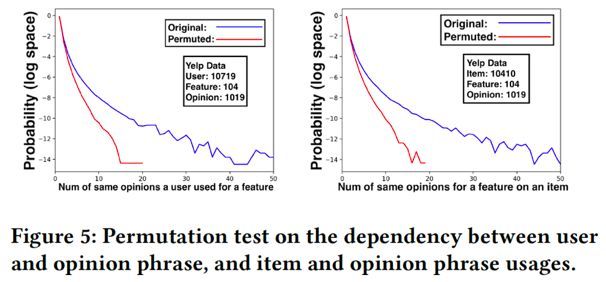
下图反映了即使在随机打乱的数据集下,MTER模型依然可以准确地捕获用户、item、特征、评价短语之间的联系。从而说明MTER模型可以有效建模用户、item、特征、评价短语四者之间的关联并给出合理的推荐结果。
用户评价数据集的大小对用户与item、特征、评价短语之间相关测试实验的影响如下图所示:
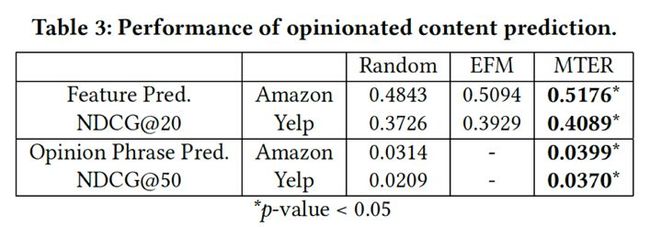
下表反映了基于特征预测和基于评价观点短语预测的推荐的性能差异,可以看出基于于评价观点短语预测的推荐还是有很大优势的。
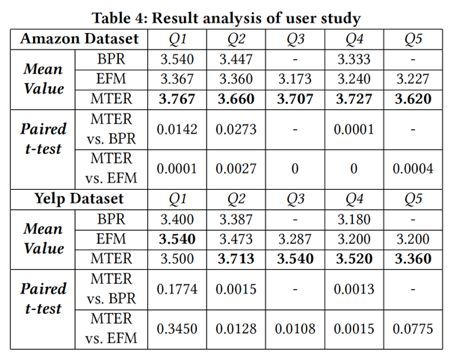
本文还做了一个用户测试,提出5个问题,对几个推荐系统的性能进行打分。问题1:一般来说,您对此推荐感到满意吗?问题2:你认为你对推荐的产品有所了解吗?问题3:解释是否有助于您了解推荐项目的更多信息?问题4:根据推荐的项目,您认为您对我们推荐此项目的原因有所了解吗?问题5:您认为解释有助于您更好地理解我们的系统,例如,根据我们提出的建议吗?
KSR Model:Knowledge-enhancedSequential Recommender
KSR模型提出了利用结合知识库的记忆网络来增强推荐系统的特征捕获能力与解释性,解决序列化推荐系统不具有解释性,且无法获取用户细粒度特征的不足。
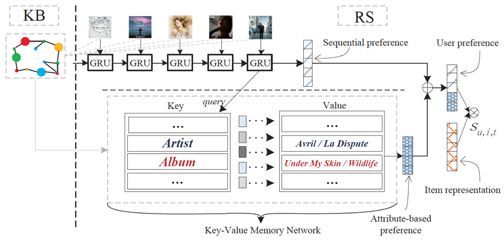
上图刻画了KSR模型的基础架构,GRU部分用来捕获用户序列偏好,KV-MN(键值记忆网络)用来捕获属性为基础的偏好特征。
以下将分三步介绍KSR模型:基于GRU的序列推荐模型、利用知识增强的记忆网络增强序列推荐模型、完整的知识增强的序列推荐模型。
1. 基于GRU的序列推荐模型
给定一组用户u的交互序列![]() ,GRU模型的隐藏层表示成
,GRU模型的隐藏层表示成![]() ,用户u的序列偏好向量可以表示成:
,用户u的序列偏好向量可以表示成:![]() 。
。
然后对每个item的表示进行预训练,这里用的也是基于贝叶斯后验优化的个性化排序算法(BPR)。
![]()
通过计算推荐得分对候选项i进行排名
![]()
2. 知识增强的记忆网络
键值记忆网络(KV-MN)中的键K就对应KG中的关系,值V就对应KG中的实体。在用户特定的键值记忆网络中,![]() ,
,![]() ,
,![]() 。键记忆矩阵
。键记忆矩阵![]() 是共享的,值记忆矩阵
是共享的,值记忆矩阵![]() 是用户特有的。
是用户特有的。
记忆网络的读操作可以表示成
![]()
就是对查询到的值进行加权输出。权重计算公式为:
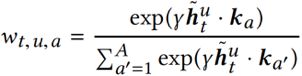
最终的查询结果为:
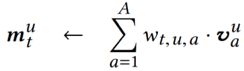
对值的写(更新)操作也类似:
![]()
这里利用TransE对KG进行预训练,得到实体和关系的表示:
![]()
然后利用这些表示计算更新门的系数:
![]()
最后得到更新后的V值:
![]()
3. 知识增强的序列推荐模型
KSR模型的整体工作机制如下图所示。
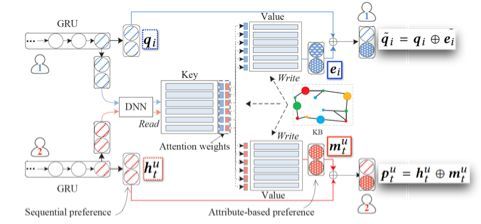
![]() 和
和![]() 有相同的维度
有相同的维度![]() 。
。
评分函数为:
![]()
基于BPR的损失函数为:
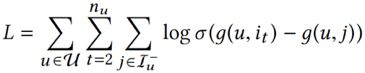
4. Experiments
实验的数据集如下表所示:
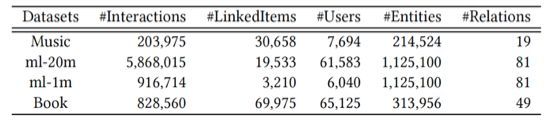
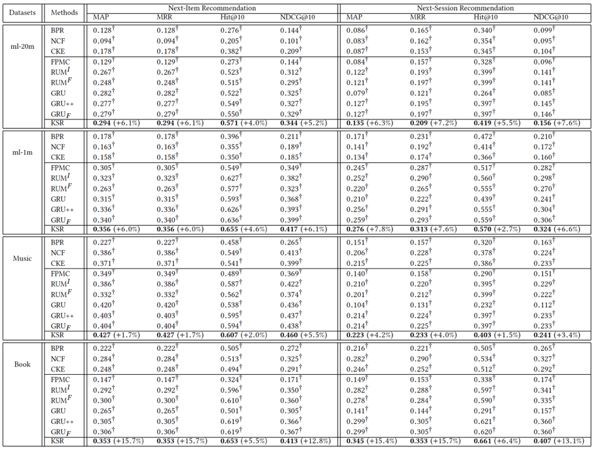
性能评价指标用的是:MAP, MRR, HR, NDCG。
Baseline的信息如下:

整体的实验结果是在每个数据集上都取得了不错的提升:
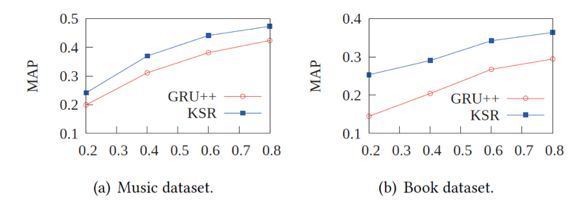
此外,本文还做了一系列对比分析实验:
(1)数据集大小对实验结果的影响
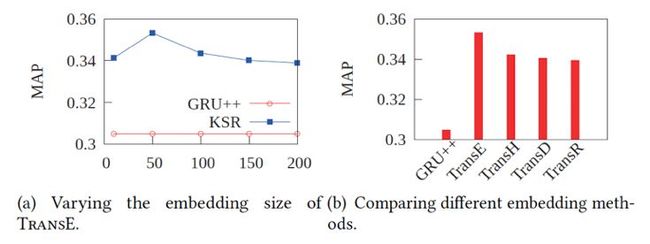
(2)是否共享键值记忆网络的值矩阵对实验结果的影响

(3)不同的KG embedding方式和选择的向量维度对实验结果的影响
可解释性的实验
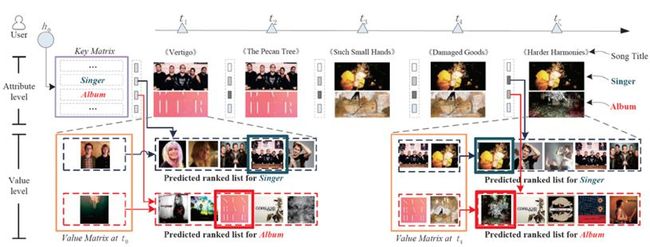
图中最上方的代表时间轴;第二行代表每个商品所具有的属性,也就是记忆网络中的键,此处以歌手和专辑为例;第三行为每个属性所产生的推荐列表。从图中第二行可以发现,一开始初始化时,推荐系统觉得用户更喜欢歌曲的专辑(一开始歌手权重较小,方框颜色较浅,专辑权重较大,颜色较深);后来随着时间的推移,推荐系统渐渐发现用户更喜欢歌曲的歌手而不是专辑(歌手方框颜色变深,专辑变浅)。从第三行可以发现,一开始推荐系统的判断是错误的,产生的推荐列表也不那么准确,但是时间越长,判断也趋向于准确,并且也给出了推荐理由,用户想听这个歌手的歌而不是这个专辑的歌。
本文作者邓淑敏,浙江大学计算机学院2017级直博生,研究方向为知识图谱与文本联合表示学习,可解释性和时序预测。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。