神经网络优化算法综述
- 算法检查
- gradient check
- sanity check
- other check
- 一阶算法
- Adagrad
- momentum
- nag
- rmsprop
- 总结
- 二阶算法
- 牛顿法
- 拟牛顿法
- 参考
神经网络的训练有不同算法,本文将简要介绍常见的训练算法:adagrad、momentum、nag、rmsprop。同时简要介绍如何进行算法检查。
算法检查
当我们实施了神经网络的梯度算法后,怎么知道我们的算法是否正确。在用于大规模数据之前,需要做两件事:
- gradient check
- sanity check
gradient check
梯度检查,就是检查我们的梯度更新是否正确。具体地,检查分析计算出的梯度与数值梯度是否足够接近。
上面显示了两种数值梯度的计算方法,一般采用下面那一种。因为进行泰勒展开后,上面项的误差是 O(h) ,下面项的误差是 O(h2) 。
计算出分析梯度与数值梯度后,需要对两者比较,比较采用相对值如下:
通常来说,1e-4的相对误差对于包含kinks的网络(例如relu)是可以接受的,对大多数网络1e-7的误差是相对较好的。
梯度检查有几点建议:
- 使用双精度
- 观察浮点数的范围,不要太小或者太大,以免超出精度限制
- 注意目标函数中是否存在kinks(relu),如果存在可以减少测试点的数量
- step不是越小越好,过小会遇到数值问题
- 检查的网络状态应该是网络的特征状态,不要在网络初始状态进行检查
- 检查的时候不要让正则项过强,否则会影响盖住data loss
- 关掉dropout等随机机制,对dropout额外进行检测
- 高维数据检测部分维度即可
sanity check
- 随机化数据,看看loss的计算是否符合预期
- 增强正则项,看看loss有没有按照预期增加
- 看看算法是否可以在小的数据集上过拟合
other check
- 更新的大小与原数据大小的比例在1e-3较合适。
# assume parameter vector W and its gradient vector dW
param_scale = np.linalg.norm(W.ravel())
update = -learning_rate*dW # simple SGD update
update_scale = np.linalg.norm(update.ravel())
W += update # the actual update
print update_scale / param_scale # want ~1e-3- 监测每层激活函数以及梯度的分布
- 进行参数可视化
一阶算法
Adagrad
在神经网络的训练中,学习率一般随着迭代次数的增长而下降。通常采用学习率的变化公式为:
可是学习率不仅受时间(迭代次数)的影响,也受当前参数或者说当前参数所在状态的影响。Adagrad便用参数之前导数的rms考虑了参数的状态信息。
令:
只考虑时间变化的梯度下降与adagrad对比如下:
例子如下:

adagrad的解释如下:
adagrad考虑了梯度随时间以及参数状态的变化,进一步化简可得到:

也就是说,在固定的学习率 η 下,梯度更新的大小:
- 与当前的梯度 gt 成正比
- 与之前的梯度 ∑ti=0(gi)2 成反比
那么,问题来了:为什么要这么做呢?
答案是:gd是一次逼近,adagrad是用历史的导数信息做二次逼近。而 ∑ti=0(gi)2 便表征了二次导数信息。
二次逼近的效果好于一次逼近不需赘述,二次逼近的更新公式是 x←x−f′(x)f″(x) 。 f′(x) 较容易获得,可是 f″(x) 需要计算海森矩阵不易得到。adagrad的优势就在用一次导数去估计二次导数。
估计的方法是:二次导数越大,那么其对应的一次导数的变化也越大,直观的例子如下:

这样做的好处如下图所示,在蓝色箭头部分,一阶导数的值较小,可是按照图中的位置需要更新比较大的距离。这时候考虑二阶导数部分,二阶导数比较小,采用二阶更新办法得到的更新值比较大,满足了我们的要求:

总结来说,adagrad的理解有两种方式:
- 更新的大小不仅跟时间有关,也跟当前参数空间,参数周围的状态有关
- gd是一阶更新方式,adagrad是二阶更新方式,用历史的梯度信息去近似二阶导数。
momentum
momentum考虑参数更新时会遇到以下三个问题:
- 参数落在plateau,梯度计算值过小,更新过慢
- 参数落在鞍点(saddle point),更新值为0
- 参数落在局部最小值(local minima),更新值为0
这些问题,通过momentum都可以解决。momentum相当于给参数更新加了惯性,更新的方向与距离是通过当前的梯度与上一次更新的方向距离联合得到的。
也就是说:
Movement not just based on gradient, but previous movement.


nag
nag的全称是Nesterov’s Accelerated Gradient。其是对momentum的改进,区别如下:
- momentum将之前的移动与当前的梯度联合起来计算新的移动
- nag先按照之前的移动,然后在新的位置计算梯度,然后把之前的移动与新的梯度联合计算新的移动
nag相比momentum的优势在于:其按照原来的移动先移动了一下,并且计算移动后位置的梯度,相当于对周围的状况有了更多的了解,因此能够更准确的确定新的更新方向。
nag与momentum以及gd对比如下:
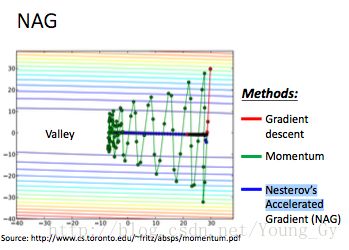
nag与momentum的原理示意图如下:
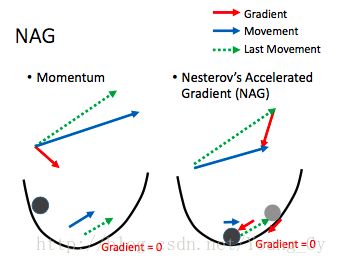
rmsprop
rmsprop是对adagrad的改进,adgrad利用历史的一阶导数信息去近似估计二阶导数,因此对参数周围的状态有了更多的了解,参数可以更新的更好。
可是,adgrad利用的历史一阶导数信息的权重是相同的。事实上,我们应该更关心当前的状态,也就是说:在估计二阶导数时应该给更近的一阶导数赋予更大的权重。

rmsprop引入衰减系数 α ,公式如下:

总结
对以上算法简单总结如下:
# Vanilla update
x += - learning_rate * dx
# Momentum update
v = mu * v - learning_rate * dx # integrate velocity
x += v # integrate position
# nag
x_ahead = x + mu * v
# evaluate dx_ahead (the gradient at x_ahead instead of at x)
v = mu * v - learning_rate * dx_ahead
x += v
# adagrad
cache += dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
# rmsprop
cache = decay_rate * cache + (1 - decay_rate) * dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
# adam, like RMSProp with momentum.
m = beta1*m + (1-beta1)*dx
v = beta2*v + (1-beta2)*(dx**2)
x += - learning_rate * m / (np.sqrt(v) + eps)二阶算法
牛顿法
首先先来回顾下牛顿法:牛顿法可以用来求 f(x) 的零点,求解方法是:
如果要求 f(x) 的极值,那么就是求 f′(x) 的零点,求解方法是:
当 x 的维度变高后,引入海森矩阵 H ,有:
拟牛顿法
牛顿法有个缺点,海森矩阵是非稀疏矩阵,参数太多,其计算量太大。因此拟牛顿法采用一些优化方法去近似计算海森矩阵的逆,大大减少了计算量。
常用的拟牛顿法有:
- BFGS
- L-BFGS(使用随着时间的梯度信息去近似海森矩阵的逆)
然而,拟牛顿法在神经网络的训练中用的较少,原因主要是拟牛顿法的训练需要使用全部的数据集。batch的拟牛顿法目前还不成熟。
参考
- CS231N
- MLDS