基于RNN的语言模型与机器翻译NMT
- 语言模型
- 传统的语言模型
- 基于RNN的语言模型
- 机器翻译
- 基于统计的机器翻译架构
- 基于RNN的seq2seq架构
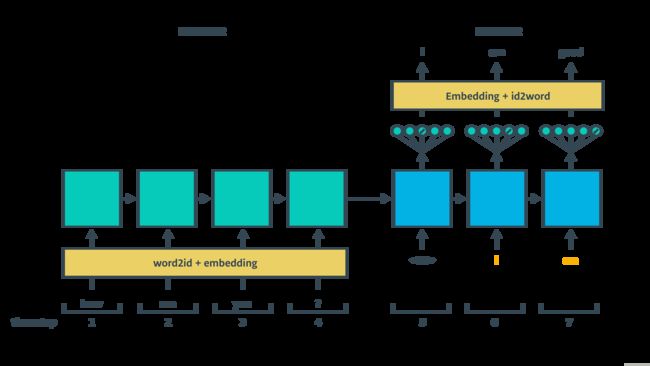
- seq2seq结构
- 优化seq2seq
- attention
- search in decoder
- Tensorflow实例
以RNN为代表的语言模型在机器翻译领域已经达到了State of Art的效果,本文将简要介绍语言模型、机器翻译,基于RNN的seq2seq架构及优化方法。
语言模型
语言模型就是计算一序列词出现的概率 P(w1,w2,...,wT) 。
语言模型在机器翻译领域的应用有:
- 词排序:p(the cat is small) > p(small the is cat)
- 词选择:p(walking home after school) > p(walking house after school)
传统的语言模型
传统的语言模型通过两点假设,将词序列的联合概率转化为每个词条件概率的连乘形式:
- 每个词只和它前面出现的词有关
- 每个词只和它前面出现的 k 个词有关
每个词条件概率的计算通过n-gram的形式,具体如下图。

然而,传统语言模型的一大缺点就是,精度的提升需要提高n-gram中的n。提高n的值带来需要内存的指数提高。
基于RNN的语言模型
基于RNN的语言模型利用RNN本身输入是序列的特点,在隐含层神经元之上加了全连接层、Softmax层,得到输出词的概率分布。
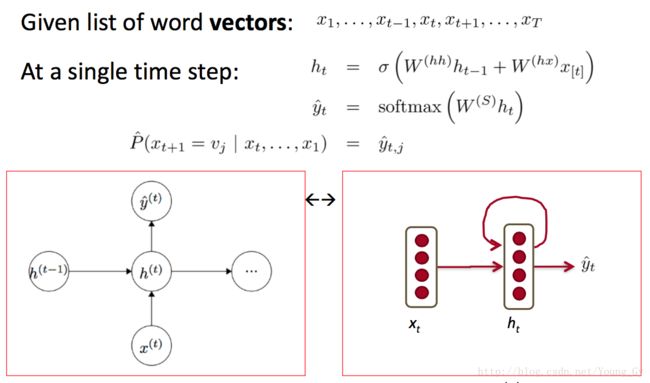
然而,RNN的训练比较困难,通常采用的trick如下:
- gradient clipping
- Initialization(identity matrix) + ReLus
- Class-based word prediction, p(wt|h)=p(ct|h)p(wt|ct)
- 采用rmsprop、adma等优化方法
- 采用gru、lstm等神经单元
机器翻译
基于统计的机器翻译架构
基于统计的机器翻译架构,简单来说包含两个步骤:
- 构建从source到target的alignment。
- 根据source到target的alignment获得各种组合,根据language model获得概率最大的组合。




基于RNN的seq2seq架构
seq2seq结构
基于RNN的seq2seq架构包含encoder和decoder,decoder部分又分train和inference两个过程,具体结构如下面两图所示:
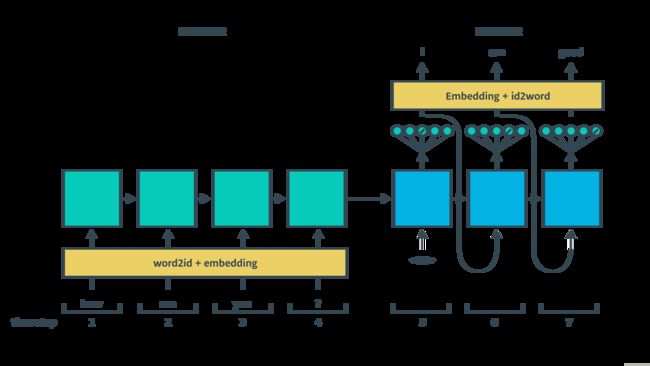
优化seq2seq
- seq2seq的decoder中,输入信息只有 ht−1,xt ,在这基础上,可以增加新的信息 yt−1,senc 。
- 加深网络结构
- 双向RNN,结合了上文和下文信息
- Train input sequence in reverse order for simple optimization problem
- 采用gru、lstm
attention
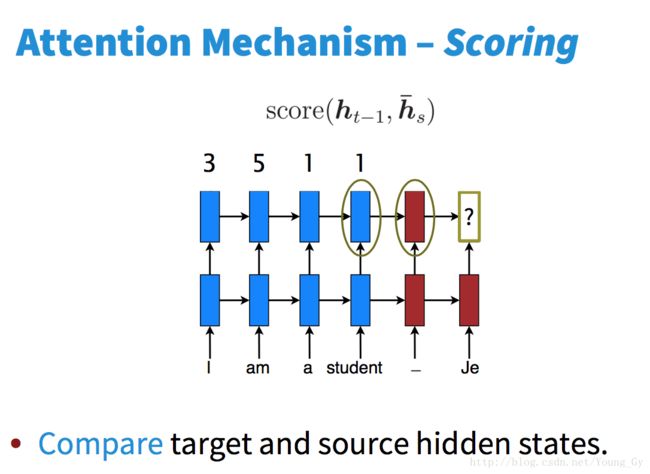
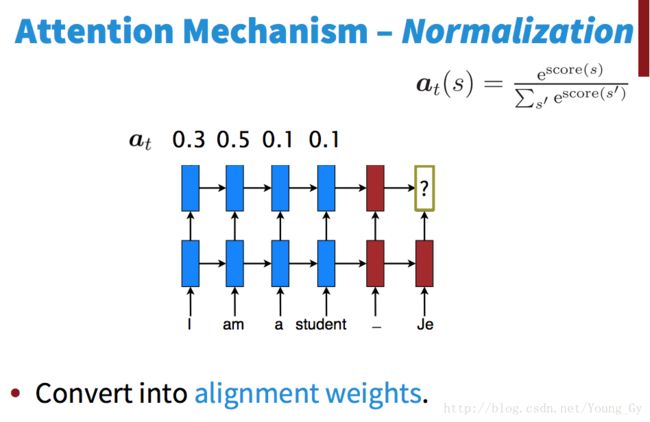
attention机制的核心是将encoder的状态储存起来并供decoder每个step有选择地调用。具体包括以下步骤:
- 计算decoder的当前step的state与encoder各个step state的分数。
- 将分数正则化。
- 依照正则化后的分数将encoder的各个step的state线性组合起来。
- 将组合后的state作为decoder当前step的输入,相当于给decoder提供了额外的信息。


search in decoder
decoder inference的时候对inference序列的选择有以下几种方法:
- Exhaustive Search:穷举每种可能的情况,不实用。
- Ancestral Sampling:按照概率分布抽样,优点是效率高无偏差,缺点是方差大。
- Greedy Search:选择概率最大的抽样,优点是效率高,缺点是不容易找到最佳值。
- Beam Search:常用的采样方法,设置采样为K,第一次迭代出现K个,第二次出现K^2个并在其中在挑选K个。优点是质量好,缺点是计算量大。


Tensorflow实例
下面,介绍基于Tensorflow 1.1的实例代码,代码参考了Udacity DeepLearning NanoDegree的部分示例代码。
输入部分:
- input: 秩为2的输入数据(翻译源)的Tensor,长度不同的增加PAD。是encoder的输入。
- targets: 秩为2的输出数据(翻译目标)的Tensor,每个序列的结尾增加EOS,长度不同的增加PAD。是decoder的输出。
构建网络部分代码函数如下:
- model_inputs: 构建网络输入。
- process_decoder_input:对target去除最后一列并在每个序列起始位加上GO,构建decoder的输入dec_input。
- encoding_layer:对input加embedding层,加RNN得到输出enc_output, enc_state。
- decoding_layer_train:得到decoder train过程的输出dec_outputs_train。
- decoding_layer_infer:得到decoder infer过程的输出dec_outputs_infer。
- decoding_layer:对dec_input加embedding层,加RNN得到train和infer的输出dec_outputs_train, dec_outputs_infer。
- seq2seq_model:将encoder和decoder封装到一起。
# prepare input
def model_inputs():
"""
Create TF Placeholders for input, targets, learning rate, and lengths of source and target sequences.
:return: Tuple (input, targets, learning rate, keep probability, target sequence length,
max target sequence length, source sequence length)
"""
# TODO: Implement Function
# input parameters
input = tf.placeholder(tf.int32, [None, None], name="input")
targets = tf.placeholder(tf.int32, [None, None], name="targets")
# training parameters
learning_rate = tf.placeholder(tf.float32, name="learning_rate")
keep_prob = tf.placeholder(tf.float32, name="keep_prob")
# sequence length parameters
target_sequence_length = tf.placeholder(tf.int32, [None], name="target_sequence_length")
max_target_sequence_length = tf.reduce_max(target_sequence_length)
source_sequence_length = tf.placeholder(tf.int32, [None], name="source_sequence_length")
return (input, targets, learning_rate, keep_prob, target_sequence_length, \
max_target_sequence_length, source_sequence_length)
def process_decoder_input(target_data, target_vocab_to_int, batch_size):
"""
Preprocess target data for encoding
:param target_data: Target Placehoder
:param target_vocab_to_int: Dictionary to go from the target words to an id
:param batch_size: Batch Size
:return: Preprocessed target data
"""
x = tf.strided_slice(target_data, [0,0], [batch_size, -1], [1,1])
y = tf.concat([tf.fill([batch_size, 1], target_vocab_to_int['' ]), x], 1)
return y
# Encoding
def encoding_layer(rnn_inputs, rnn_size, num_layers, keep_prob,
source_sequence_length, source_vocab_size,
encoding_embedding_size):
"""
Create encoding layer
:param rnn_inputs: Inputs for the RNN
:param rnn_size: RNN Size
:param num_layers: Number of layers
:param keep_prob: Dropout keep probability
:param source_sequence_length: a list of the lengths of each sequence in the batch
:param source_vocab_size: vocabulary size of source data
:param encoding_embedding_size: embedding size of source data
:return: tuple (RNN output, RNN state)
"""
# TODO: Implement Function
# embedding input
enc_inputs = tf.contrib.layers.embed_sequence(rnn_inputs, source_vocab_size, encoding_embedding_size)
# construcll rnn cell
cell = tf.contrib.rnn.MultiRNNCell([
tf.contrib.rnn.LSTMCell(rnn_size) \
for _ in range(num_layers) ])
# rnn forward
enc_output, enc_state = tf.nn.dynamic_rnn(cell, enc_inputs, sequence_length=source_sequence_length, dtype=tf.float32)
return enc_output, enc_state
# Decoding
## Decoding Training
def decoding_layer_train(encoder_state, dec_cell, dec_embed_input,
target_sequence_length, max_summary_length,
output_layer, keep_prob):
"""
Create a decoding layer for training
:param encoder_state: Encoder State
:param dec_cell: Decoder RNN Cell
:param dec_embed_input: Decoder embedded input
:param target_sequence_length: The lengths of each sequence in the target batch
:param max_summary_length: The length of the longest sequence in the batch
:param output_layer: Function to apply the output layer
:param keep_prob: Dropout keep probability
:return: BasicDecoderOutput containing training logits and sample_id
"""
helper = tf.contrib.seq2seq.TrainingHelper(dec_embed_input, target_sequence_length)
decoder = tf.contrib.seq2seq.BasicDecoder(dec_cell, helper, encoder_state, output_layer=output_layer)
dec_outputs, dec_state = tf.contrib.seq2seq.dynamic_decode(decoder, impute_finished=True, maximum_iterations=max_summary_length)
return dec_outputs
## Decoding Inference
def decoding_layer_infer(encoder_state, dec_cell, dec_embeddings, start_of_sequence_id,
end_of_sequence_id, max_target_sequence_length,
vocab_size, output_layer, batch_size, keep_prob):
"""
Create a decoding layer for inference
:param encoder_state: Encoder state
:param dec_cell: Decoder RNN Cell
:param dec_embeddings: Decoder embeddings
:param start_of_sequence_id: GO ID
:param end_of_sequence_id: EOS Id
:param max_target_sequence_length: Maximum length of target sequences
:param vocab_size: Size of decoder/target vocabulary
:param decoding_scope: TenorFlow Variable Scope for decoding
:param output_layer: Function to apply the output layer
:param batch_size: Batch size
:param keep_prob: Dropout keep probability
:return: BasicDecoderOutput containing inference logits and sample_id
"""
# TODO: Implement Function
start_tokens = tf.tile(tf.constant([start_of_sequence_id], dtype=tf.int32), [batch_size], name='start_tokens')
helper = tf.contrib.seq2seq.GreedyEmbeddingHelper(dec_embeddings,
start_tokens, end_of_sequence_id)
decoder = tf.contrib.seq2seq.BasicDecoder(dec_cell, helper, encoder_state, output_layer=output_layer)
dec_outputs, dec_state = tf.contrib.seq2seq.dynamic_decode(decoder,impute_finished=True,
maximum_iterations=max_target_sequence_length)
return dec_outputs
## Decoding Layer
from tensorflow.python.layers import core as layers_core
def decoding_layer(dec_input, encoder_state,
target_sequence_length, max_target_sequence_length,
rnn_size,
num_layers, target_vocab_to_int, target_vocab_size,
batch_size, keep_prob, decoding_embedding_size):
"""
Create decoding layer
:param dec_input: Decoder input
:param encoder_state: Encoder state
:param target_sequence_length: The lengths of each sequence in the target batch
:param max_target_sequence_length: Maximum length of target sequences
:param rnn_size: RNN Size
:param num_layers: Number of layers
:param target_vocab_to_int: Dictionary to go from the target words to an id
:param target_vocab_size: Size of target vocabulary
:param batch_size: The size of the batch
:param keep_prob: Dropout keep probability
:return: Tuple of (Training BasicDecoderOutput, Inference BasicDecoderOutput)
"""
# embedding target sequence
dec_embeddings = tf.Variable(tf.random_uniform([target_vocab_size, decoding_embedding_size]))
dec_embed_input = tf.nn.embedding_lookup(dec_embeddings, dec_input)
# construct decoder lstm cell
dec_cell = tf.contrib.rnn.MultiRNNCell([
tf.contrib.rnn.LSTMCell(rnn_size) \
for _ in range(num_layers) ])
# create output layer to map the outputs of the decoder to the elements of our vocabulary
output_layer = layers_core.Dense(target_vocab_size,
kernel_initializer = tf.truncated_normal_initializer(mean = 0.0, stddev=0.1))
# decoder train
with tf.variable_scope("decoding") as decoding_scope:
dec_outputs_train = decoding_layer_train(encoder_state, dec_cell, dec_embed_input,
target_sequence_length, max_target_sequence_length,
output_layer, keep_prob)
# decoder inference
start_of_sequence_id = target_vocab_to_int["" ]
end_of_sequence_id = target_vocab_to_int["" ]
with tf.variable_scope("decoding", reuse=True) as decoding_scope:
dec_outputs_infer = decoding_layer_infer(encoder_state, dec_cell, dec_embeddings, start_of_sequence_id,
end_of_sequence_id, max_target_sequence_length,
target_vocab_size, output_layer, batch_size, keep_prob)
# rerturn
return dec_outputs_train, dec_outputs_infer
# Seq2seq
def seq2seq_model(input_data, target_data, keep_prob, batch_size,
source_sequence_length, target_sequence_length,
max_target_sentence_length,
source_vocab_size, target_vocab_size,
enc_embedding_size, dec_embedding_size,
rnn_size, num_layers, target_vocab_to_int):
"""
Build the Sequence-to-Sequence part of the neural network
:param input_data: Input placeholder
:param target_data: Target placeholder
:param keep_prob: Dropout keep probability placeholder
:param batch_size: Batch Size
:param source_sequence_length: Sequence Lengths of source sequences in the batch
:param target_sequence_length: Sequence Lengths of target sequences in the batch
:param source_vocab_size: Source vocabulary size
:param target_vocab_size: Target vocabulary size
:param enc_embedding_size: Decoder embedding size
:param dec_embedding_size: Encoder embedding size
:param rnn_size: RNN Size
:param num_layers: Number of layers
:param target_vocab_to_int: Dictionary to go from the target words to an id
:return: Tuple of (Training BasicDecoderOutput, Inference BasicDecoderOutput)
"""
# TODO: Implement Function
# embedding and encoding
enc_output, enc_state = encoding_layer(input_data, rnn_size, num_layers, keep_prob,
source_sequence_length, source_vocab_size,
enc_embedding_size)
# process target data
dec_input = process_decoder_input(target_data, target_vocab_to_int, batch_size)
# embedding and decoding
dec_outputs_train, dec_outputs_infer = decoding_layer(dec_input, enc_state,
target_sequence_length, tf.reduce_max(target_sequence_length),
rnn_size,
num_layers, target_vocab_to_int, target_vocab_size,
batch_size, keep_prob, dec_embedding_size)
return dec_outputs_train, dec_outputs_infer
# Build Graph
"""
DON'T MODIFY ANYTHING IN THIS CELL
"""
save_path = 'checkpoints/dev'
(source_int_text, target_int_text), (source_vocab_to_int, target_vocab_to_int), _ = helper.load_preprocess()
max_target_sentence_length = max([len(sentence) for sentence in source_int_text])
train_graph = tf.Graph()
with train_graph.as_default():
input_data, targets, lr, keep_prob, target_sequence_length, max_target_sequence_length, source_sequence_length = model_inputs()
#sequence_length = tf.placeholder_with_default(max_target_sentence_length, None, name='sequence_length')
input_shape = tf.shape(input_data)
train_logits, inference_logits = seq2seq_model(tf.reverse(input_data, [-1]),
targets,
keep_prob,
batch_size,
source_sequence_length,
target_sequence_length,
max_target_sequence_length,
len(source_vocab_to_int),
len(target_vocab_to_int),
encoding_embedding_size,
decoding_embedding_size,
rnn_size,
num_layers,
target_vocab_to_int)
training_logits = tf.identity(train_logits.rnn_output, name='logits')
inference_logits = tf.identity(inference_logits.sample_id, name='predictions')
masks = tf.sequence_mask(target_sequence_length, max_target_sequence_length, dtype=tf.float32, name='masks')
with tf.name_scope("optimization"):
# Loss function
cost = tf.contrib.seq2seq.sequence_loss(
training_logits,
targets,
masks)
# Optimizer
optimizer = tf.train.AdamOptimizer(lr)
# Gradient Clipping
gradients = optimizer.compute_gradients(cost)
capped_gradients = [(tf.clip_by_value(grad, -1., 1.), var) for grad, var in gradients if grad is not None]
train_op = optimizer.apply_gradients(capped_gradients)
# Training
"""
DON'T MODIFY ANYTHING IN THIS CELL
"""
def get_accuracy(target, logits):
"""
Calculate accuracy
"""
max_seq = max(target.shape[1], logits.shape[1])
if max_seq - target.shape[1]:
target = np.pad(
target,
[(0,0),(0,max_seq - target.shape[1])],
'constant')
if max_seq - logits.shape[1]:
logits = np.pad(
logits,
[(0,0),(0,max_seq - logits.shape[1])],
'constant')
return np.mean(np.equal(target, logits))
# Split data to training and validation sets
train_source = source_int_text[batch_size:]
train_target = target_int_text[batch_size:]
valid_source = source_int_text[:batch_size]
valid_target = target_int_text[:batch_size]
(valid_sources_batch, valid_targets_batch, valid_sources_lengths, valid_targets_lengths ) = next(get_batches(valid_source,
valid_target,
batch_size,
source_vocab_to_int['' ],
target_vocab_to_int['' ]))
with tf.Session(graph=train_graph) as sess:
sess.run(tf.global_variables_initializer())
for epoch_i in range(epochs):
for batch_i, (source_batch, target_batch, sources_lengths, targets_lengths) in enumerate(
get_batches(train_source, train_target, batch_size,
source_vocab_to_int['' ],
target_vocab_to_int['' ])):
_, loss = sess.run(
[train_op, cost],
{input_data: source_batch,
targets: target_batch,
lr: learning_rate,
target_sequence_length: targets_lengths,
source_sequence_length: sources_lengths,
keep_prob: keep_probability})
if batch_i % display_step == 0 and batch_i > 0:
batch_train_logits = sess.run(
inference_logits,
{input_data: source_batch,
source_sequence_length: sources_lengths,
target_sequence_length: targets_lengths,
keep_prob: 1.0})
batch_valid_logits = sess.run(
inference_logits,
{input_data: valid_sources_batch,
source_sequence_length: valid_sources_lengths,
target_sequence_length: valid_targets_lengths,
keep_prob: 1.0})
train_acc = get_accuracy(target_batch, batch_train_logits)
valid_acc = get_accuracy(valid_targets_batch, batch_valid_logits)
print('Epoch {:>3} Batch {:>4}/{} - Train Accuracy: {:>6.4f}, Validation Accuracy: {:>6.4f}, Loss: {:>6.4f}'
.format(epoch_i, batch_i, len(source_int_text) // batch_size, train_acc, valid_acc, loss))
# Save Model
saver = tf.train.Saver()
saver.save(sess, save_path)
print('Model Trained and Saved')