开源工具之kafka
是什么?
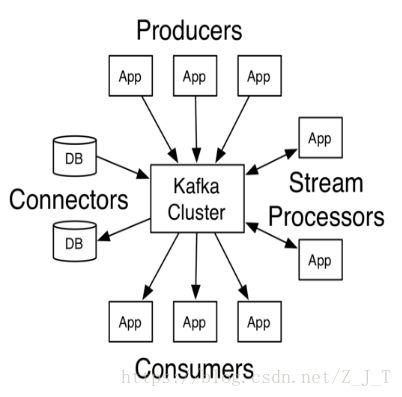
一个分布式的消息系统(消息队列),在流式计算中,一般用来缓存数据。kafka作为一个集群运行中在一个或多个服务器上。
主要核心组件
- Topic:消息根据Topic进行归类
- Producer:消息生产者,就是向kafka broker发消息的客户端。
- Consumer:消息消费者,向kafka broker取消息的客户端。
- broker:每个kafka实例(server),一台kafka服务器就是一个broker,一个集群由多个broker组成,一个broker可以容纳多个topic。
- Zookeeper:依赖集群保存meta信息。
kafka集群存储的消息以topic区分,每一个消息由一个key,一个value和时间戳构成。
kafka有四个核心API:
- 使用 Producer API 发布消息到1个或多个topic(主题)。
- 使用 Consumer API 来订阅一个或多个topic,并处理产生的消息。
- 使用 Streams API 充当一个流处理器,从1个或多个topic消费输入流,并生产一个输出流到1个或多个输出topic,有效地将输入流转换到输出流。
- Connector API允许构建或运行可重复使用的生产者或消费者,将topic连接到现有的应用程序或数据系统。例如,一个关系数据库的连接器可捕获每一个变化。
主要功能
作为一个分布式流平台
一个流处理平台具有三个关键能力:
- 发布和订阅消息(流),在这方面,它类似于一个消息队列或企业消息系统。
- 以容错的方式存储消息(流)。
- 在消息流发生时处理它们。
作用:
- 构建实时的流数据管道,可靠地获取系统和应用程序之间的数据。
- 构建实时流的应用程序,对数据流进行转换或反应。
作为一个消息系统
Kafka的流与传统企业消息系统相比的概念如何?
传统的消息有两种模式:队列和发布订阅。
- 队列模式:消费者池从服务器读取消息(每个消息只被其中一个读取);
- 发布订阅模式:消息广播给所有的消费者。接收到消息的消费者都可以处理此消息。
队列
优点:允许多个消费者瓜分处理数据,可以扩展处理。
缺点:队列不像多个订阅者,一旦消息者进程读取后故障了,那么消息就丢了。
发布和订阅
优点:允许广播数据到多个消费者
缺点:由于每个订阅者都订阅了消息,所以没办法缩放处理。
Kafka为这两种模型提供了单一的消费者抽象模型: 消费者组 (consumer group)。
kafka中消费者组有两个概念:
队列:消费者组允许同名的消费者组成员瓜分处理。
发布订阅:允许你广播消息给多个消费者组(不同名)
优势:
kafka的每个topic都具有这两种模式。
kafka有比传统的消息系统更强的顺序保证。
怎么使用单一的消费者模型抽象出队列和发布订阅模型?
消费者用一个消费者组名标记自己。 一个发布在Topic上消息被分发给此消费者组中的一个消费者。
- 假如所有的消费者都在一个组中,那么这就变成了queue模型。
- 假如所有的消费者都在不同的组中,那么就完全变成了发布-订阅模型。
- 更通用的, 我们可以创建一些消费者组作为逻辑上的订阅者。每个组包含数目不等的消费者, 一个组内多个消费者可以用来扩展性能和容错。
传统的消息系统缺陷
传统的消息系统按顺序保存数据,如果多个消费者队列消费,则服务器按存储的顺序发送消息,但是,尽管服务器按顺序发送,消息异步传递到消费者,因此消息可能乱序到达消费者。这意味着消息存在并行消费的情况,顺序就无法保证。消息系统常常通过仅设1个消费者来解决这个问题,但是这意味着没用到并行处理。
kafka的优势
通过并行topic的partition ,kafka提供了顺序保证和负载均衡。
每个partition仅由同一个消费者组中的一个消费者消费到。并确保消费者是该partition的唯一消费者,并按顺序消费数据。每个topic有多个分区,则需要对多个消费者做负载均衡,但请注意,相同的消费者组中不能有比分区更多的消费者,否则多出的消费者一直处于空等待,不会收到消息。
作为一个存储系统
所有发布消息到消息队列和消费分离的系统,实际上都充当了一个存储系统(发布的消息先存储起来)。
Kafka比别的系统的优势是它是一个非常高性能的存储系统。
优点:
- 写入到kafka的数据将写到磁盘并复制到集群中保证容错性。
- 允许生产者等待消息应答,直到消息完全写入。
- kafka的磁盘结构,无论你服务器上有50KB或50TB,执行是相同的。
- client来控制读取数据的位置。
也可以认为kafka是一种专用于高性能,低延迟,提交日志存储,复制,和传播特殊用途的分布式文件系统。
流处理
仅仅读,写和存储是不够的,kafka的目标是实时的流处理。
在kafka中,流处理持续获取输入topic的数据,进行处理加工,然后写入输出topic。
例如,一个零售APP,接收销售和出货的输入流,统计数量或调整价格后输出。
可以直接使用producer和consumer API进行简单的处理。对于复杂的转换,Kafka提供了更强大的Streams API。可构建聚合计算或连接流到一起的复杂应用程序,解决此类应用面临的硬性问题:处理无序的数据,代码更改的再处理,执行状态计算等。
Sterams API在Kafka中的核心:
使用producer和consumer API作为输入,利用Kafka做状态存储,使用相同的组机制在stream处理器实例之间进行容错保障。
功能总结
消息传递,存储和流处理的组合看似反常,但对于Kafka作为流式处理平台的作用至关重要。
比较一下HDFS(分布式文件系统)
像HDFS这样的分布式文件系统允许存储静态文件来进行批处理。
这样系统可以有效地存储和处理来自过去的历史数据。
传统企业的消息系统
允许在你订阅之后处理未来的消息:在未来数据到达时处理它。
kafka
kafka结合了这两种能力,这种组合对于kafka作为流处理应用和流数据管道平台是至关重要的。
批处理以及消息驱动应用程序的流处理的概念:
通过组合存储和低延迟订阅,流处理应用可以用相同的方式对待过去和未来的数据。它是一个单一的应用程序,它可以处理历史的存储数据,当它处理到最后一个消息时,它进入等待未来的数据到达,而不是结束。
对于流数据管道(pipeline)
订阅实时事件的组合使得可以将Kafka用于非常低延迟的管道;但是,可靠地存储数据的能力使得它可以将其用于必须保证传递的关键数据,或与仅定期加载数据或长时间维护的离线系统集成在一起。流处理可以在数据到达时转换它。
关于Apache kafka 流行的使用场景
消息
kafka更好的替换传统的消息系统,消息系统被用于各种场景(解耦数据生产者,缓存未处理的消息等),与大多数消息系统比较,kafka有更好的吞吐量,内置分区,副本和故障转移,这有利于处理大规模的消息。根据我们的经验,消息往往用于较低的吞吐量,但需要低的端到端延迟,并需要提供强大的耐用性的保证。在这一领域的kafka比得上传统的消息系统,如的ActiveMQ或RabbitMQ的。
网站活动追踪
kafka原本的使用场景:用户的活动追踪,网站的活动(网页游览,搜索或其他用户的操作信息)发布到不同的话题中心,这些消息可实时处理,实时监测,也可加载到Hadoop或离线处理数据仓库。每个用户页面视图都会产生非常高的量。
指标
kafka也常常用于监测数据。分布式应用程序生成的统计数据集中聚合。
日志聚合
使用kafka代替一个日志聚合的解决方案。
流处理
kafka消息处理包含多个阶段。其中原始输入数据是从kafka主题消费的,然后汇总,丰富,或者以其他的方式处理转化为新主题,例如,一个推荐新闻文章,文章内容可能从“articles”主题获取;然后进一步处理内容,得到一个处理后的新内容,最后推荐给用户。这种处理是基于单个主题的实时数据流。从0.10.0.0开始,轻量,但功能强大的流处理,就进行这样的数据处理了。除了Kafka Streams,还有Apache Storm和Apache Samza可选择。
事件采集
事件采集是一种应用程序的设计风格,其中状态的变化根据时间的顺序记录下来,kafka支持这种非常大的存储日志数据的场景。
提交日志
kafka可以作为一种分布式的外部提交日志,日志帮助节点之间复制数据,并作为失败的节点来恢复数据重新同步,kafka的日志压缩功能很好的支持这种用法,这种用法类似于Apacha BookKeeper项目。