Learning to Track at 100 FPS with Deep Regression Networks 论文理解及应用笔记(一)
GOTURN算法论文翻译及理解云笔记
前言:本笔记仅限个人算法理解与记忆,
不涉及技术/论文相关商业用途。
第一部分:个人 根据原论文的
翻译及笔记
第二部分:个人根据论文及
原算法的具体实现及应用迁移笔记
摘要:机器学习技术经常由于他们通过大量训练数据提升性能的能力而被用于机器视觉方面。但不幸的是,大多数通用物体跟随算法都仍停留在在线训练并且没能从大量可用于离线训练的的可获取视频中获利。我们由此提出了一种离线训练神经网络,并且它能实现对测试物体实现每秒100fps的实时跟踪。我们的跟踪器在效果上显著优于以往运行十分缓慢,并且完全无法实现实时应用的神经网络跟踪器算法。我们的跟踪器使用了一种简单、无需在线训练的前向神经网络。这个跟踪器能学会物体运动和物体外表之间的某种关系,并能用于跟踪哪些没有在训练中出现的异常物体。我们通过标准的跟踪基准要求来对我们的网络进行测试以此来证明我们跟踪算法的在性能上处于先进地位。另外,我们的训练算法在我们添加更多视频用于离线训练时得到了显著提高。就我们所知,我们的
跟踪算法是首个能通过学习达到100fps处理速度的神经网络跟踪算法。
一、算法简介
对视频中的某一帧的某个事物进行标定,单目标跟踪的目的就是在后续出现的视频帧中对特定物体实现标定,并且不受物体运动,画面改变、光线变化或者其他干扰的影响,单一目标跟踪算法在很多领域都是非常重要的应用。对于行人跟踪应用,一个机器人能对经过自己附近时很好的实现跟踪,并预测出他们下一步的运动。
使用带有边界框标签(但无类别信息)的视频和图像集合作为训练集,我们训练了一个用于跟踪移动物体的神经网络,在测试阶段,这个神经网络能对移动物体实现无fine-tuning跟踪,通过避免fine-tuning,我们的神经网络能达到100fps.
目前通用的目标跟踪(不针对特定类进行跟踪)方法一般时整体从头开始在线训练的,而没有离线训练的算法得到应用。这些算法无法充分利用大量能易于获取的视频数据来提升它们性能。离线训练视频能被用于教会跟踪算法如何应对旋转、观测点变换、光线变换或其他复杂挑战。
在很对机器视觉领域中,如图像分类,目标检测、分割、或者是运动检测,机器学习算法已经让视觉算法通过大量的离线数据训练并且学会了解这个世界。在每个这种领域中,算法性能随着训练过程中对所有图片的遍历而提升。这些模型从神经网络对大量数据中学习复杂函数的能力中获益。
在我们的工作中,我们证明通过
离线视频训练能实现对移动物体的
实时跟踪。为了实现这个目标,我们将介绍GOTURN,一个使用
Regression Networks(回归网络)的移动目标跟踪算法。我们在完全的离线环境中训练了用于跟踪的神经网络。在测试阶段进行目标跟踪时,网络权值是固定的,并且不需要在线调整。尽管是离线训练,但跟踪器在目标跟踪过程中表现的非常快速、鲁棒性良好、精准度高。
尽管使用神经网络用于跟随算法的过程中会采取了一些初始化工作,但这些因素会造成神经网络跟随器运行过慢。相反的是,我们的神经网络跟随器则能实现100fps的目标跟踪。就目前而言,这是最快的神经网络跟随器。
我们实时速度由两部分因素实现.第一,大部分从前的神经网络跟踪器是在线训练的;然而,训练网络是一个很慢的过程,导致最终的跟随效果也很慢,因此不能进行在线训练。第二,大多数跟随器是在分类器的基础上实现的,对很对图像块进行分类来找到目标物体。而在我们的算法中,跟随器使用了基于回归的方式,只需要一个前馈传播经过网络来回归得到目标物体的位置。对于离线训练和基于回归的方法导致相对于以往方式的显著加速、这也使得在线木匾跟踪跟踪成为可能。
GOTURN 是首个能运行在100FPS的目标跟踪神经网络。我们通过标准跟踪基准对跟踪算法性能进行测试,但并不要求任何的分类标签信息或者跟踪目标的风格特点信息,GOTURN根据移动物体和外观间的关系离线学习和建立了一种新的跟踪算法。
二、相关工作
基于在线训练的跟踪算法
。传统用于目标检测的跟踪算法几乎都是在线训练得到的,从视频的第一帧到最后一帧图像,经典的跟踪算法法将对目标物体周围的像素块进行取样,将其认定为
“
foregrond
(感兴趣点)
”。一些离目标物体较远的区域也将被取样标注,并且认定为
“
background
(不感兴趣点)
”,这些取样块的作用是用于训练得到一个分类器,而这个分类器则在下一帧中建立和目标物体之间的联系。不幸的是,由于这些跟踪算法是完全在线训练的,这些算法无法充分利用潜在的离线数据对其性能进行提升。
一些研究者也已经尝试在传统的在线训练框架中引入神经网络的方法进行目标跟踪,但不幸的是,神经网络的训练是很缓慢的,并且如果要进行在线训练,这些训练得到的跟踪算法在测试时也将非常缓慢。这种跟踪算法的速度在0.8FPS到15FPS之间,在GPU上的神经网络运行效果能达到最好的1FPS.因此,这些跟踪算法对大多数的实际应用都是不适用的。而我们的跟踪算法基于离线训练这样一种更为通用的方式没有进行在线训练,因而能达到100FPS。
基于特定模型的跟踪算法
。一种单独的类跟踪器是用于进行特定目标跟踪而设计的。例如,如果一个只对跟踪行人感兴趣的,那门他可以训练一个行检测器。在测试阶段时,这些检测器将由暂时信息联系在一起。这些检测器是在线训练的,但它们的作用是受限的因为它们只能被用于跟踪特定的类。而我们的跟踪算法则由于使用更为通用且流行的离线训练算法而能被在测试阶段对更通用的目标进行检测。
其他神经网络跟踪算法框架
。相关的研究是区域匹配,在最近的测试中实现了4FPS跟踪速度。在这种方式中,很多
候选块被输入到整个网络中,而和目标有最高匹配得分的块则被认定为跟踪输出
。不同的是,我们的网络只需要对网络输入前后两帧图片,然后这个网络
基于回归的方式
直接找到目标区域并将其进行框定。由于
避免了对众多候选区域进行评分
,此算法能达到对目标跟踪达到100FPS的速度。
之前的这些尝试也让我们对神经网络用于目标检测中采取了其他不同的方式,例如视觉注意模等,然而,这些方式和当前的其他跟踪算法在用于时较为困难的跟踪数据并没有表现出非常出色的方面。
三、算法细节
3.1 算法概述
在大多数时候,当我们将视频帧输入到神经网络时,网络的输出成功的对视频的每一帧实现了目标跟踪定位。我们使用离线视频流或者图片对跟踪器进行训练。通过我们的离线训练过程,跟踪器学习到了一种能利用运动和外观间的关系实现跟踪目标物体的能力。
3.2 算法输入/输出
要跟踪的目标
。为了避免视频有太多的目标物体,网络必须接受一些信息了解到视频中需要进行跟踪的目标。为了实现这个要求,我们将一张目标图片输入网络中,以目标物体为中心对图片进行裁剪和缩放。这样的输入让网络能对之前没有见过的物体进行跟踪,实现对任意输入的裁剪目标进行良好跟踪,具体如下图所示,我们对裁剪的目标图像块进行适当的扩展,使得神经网络能获取跟踪目标的一些周围信息。
从更具体的角度来说,假如在t-1帧图像,跟踪器 已经预测到目标物体定位在一个以c=(c1,c2)为中心、宽为w、高为h的矩形框中。而在t时刻呢,我们将t-1时刻定位的目标物体在c=(c1,c2)为中心,宽k1w,高为k1h的区域框裁剪出来。这个图像块告诉网络下一步要跟踪的目标。我们假设c`=c,相当于一个运动定位模型,尽管有更复杂的运动模型也能得到同样的效果。对当前帧的裁剪块宽长分别为k2w和k2h,这里的w和h和前一帧的目标区域宽w和高h相同。K2定义了对跟踪目标的搜索区域,在实际中,k1=k2=2.
当目标没有被遮挡或者移动过快的情况下,目标物体将被框在这个区域中。对于快速移动的物体,搜索范围可以有所增大,但这将增大整个网络的复杂度。那对于长时间被遮挡或者大幅度移动的物体,我们的跟随器能结合其他的方式如在线训练物体检测器,就如TLD框架或者视觉注意框架,这将在未来的工作中实现。
网络输出
。网络输出当前帧目标物体的坐标,相对于前一帧目标物体的坐标的变化值。这个网络的输出包含了框的左上角坐标和右下角坐标。
3.3网络框架
对于单目标跟随,我们定义了一个通用图像比对跟随框架,具体如上图所示。在这个模型中,
我们将检测目标和搜索范围数据输入到卷积层序列中。这些卷积层的输出代表了图像在高维特征的表现。
这些卷积层的输出接下来被输入到一些来全链接层中,全连接层的作用是比较来自目标图像块的特征和当前帧的的特征来找到跟随目标的具体移动距离。在两帧之间,目标也许已经经历了变换、旋转、光线变换、遮挡或者变形。而通过全链接层学习到的函数也毫无疑问是一个 复杂的特征比较器,这个比较器能够通过大量的例子的学习使其能很好的应对各种因素同时输出目标物体的运动关系。
更具体的讲,我们
模型中使用到的
卷积层
是来源于CaffeNet的
前5个卷积层。我们将5个卷积层的输出连接成一个向量。这个向量接下来则输入到一3个全链接层中,每个全连接层包含4096个节点。最终,我们将最后一个全链接层的输出结果连接到一个输出层,该层包含4个节点用于代表输出矩形框的坐标关系。将输出数据除以10,通过验证集来选择(对所有的参数同样的处理),网络参数从CaffeNet的原本设置获得,并且在每个
全连接层之间我们使用
dropout
和
ReLU
作为非线性处理。整体的神经网络都是
基于Caffe的。
3.4跟踪
在测试阶段,我们将跟随器在第一帧中初始化为一个包围框作为参考标准(
Ground-truth),这也是单目表检测的标准做法。在每个帧流t时刻,我们将t-1时刻的目标块和t时刻的当前帧数据输入到网络中来预测t时刻帧的目标物体的位置,而在后续的视频流中迭代重复这一操作,这就能实现视频流的单目标跟踪。
4 训练
我们使用视频流和静态图片对网络进行训练,具体的训练过程如下,在所有的例子中,我们用预测坐标和参考坐标的L1范式loss来训练整个网络。
4.1从视频和图片中训练
在训练中我们使用了很多经过专门处理对每帧图像进行物体位置标注的视频。对训练集中的每一对连续帧,我么根据3.2节中的方法进行截取。在训练阶段,我们将这一对图片输入到网络中并试图预测目标是如何从第一帧中的情况运动到第二帧中的。整个过程能充分利用视频流中的每一帧经过标注的图片进行训练。这些训练数据教会了神经网络如何对更多样的目标物体进行识别并且能很好的避免对训练目标数据出现过拟合的现象。为了从一张图片中训练网络,我们根据4.2中提到的模型对一帧图片进行随机切割。在两个块间,目标已经经过了显著的变换和缩放,如下图所示:

我们认为这些块是从视频中的不同帧中提取的。尽管这些“运动”相比我们在实际训练中遇到的类型要少很多,这些图像对我们用于训练的神经网络进行不同目标进行检测仍然是有用的。
4.2平滑运动学习
真实世界的物体在空间运动中具有
平滑效应
,给一张目标物体不明确的模糊图片,一个跟踪器能预测出目标跟踪物体的位置在前一时刻保存的位置附近。这在具有多物体相近的视频中尤为重要,比如多种同种类的水果。因此我们希望教会神经网络,在其他情况相同的情况下,小运动优先于大运动。
为了让平滑运动的概念更清晰,我们定义
当前帧目标物体矩形框的中心坐标为(cx'.cy')和前一帧目标物体中心坐标的(cx,cy)间的关系
是:
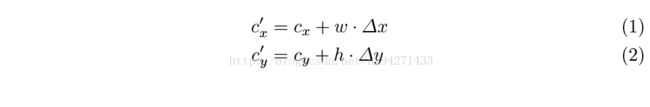
其中w和h分别是前一帧标定矩形框的宽和高。参量△x和△y是一个用于获取前一帧目标物体中心位置变化量的随机数。在训练阶段,我们发现
目标物体位置的该变量如△x和△y能模型化为一个
拉普拉斯分布和0的均值。这样一个分布模型在小运动上的出现的概率要远大于大运动。
我们的框尺寸变换如下:
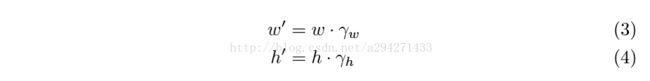
其中w'和h'分别是当前帧目标物体的框定宽度和高度,w和h为前一帧目标物体框定的宽度和高度,两个参量则体现了
框定的尺寸变化
。
我们在训练中发现这两个参量能模型化为一个拉普拉斯分布和1的均值。这样的分布在概率上更可能保持标定框大小和前一帧相同
。
为了教会网络对小范围运动更敏感,我们让训练集按照上诉的拉普拉斯分布进行随机切块。由于这些
训练样本是按照拉普拉斯分布取样的
,小幅度的运动会得到更多的取样,因此在其他条件相同时,我们的网络对于小幅度运动也将更加的敏感。接下来也将证明这种基于拉普拉斯切块的过程相比传统的标准统一切块将显著提高跟踪器性能。
其中拉普拉斯分布的
尺度参量
经过交互验证后选择为bx=1/5(对标定框的中心运动),bs=1/5(对于标定框尺度的变换)。我们对随机切块做出约束,其每个维度必须至少包含目标物体一半的内容。同时限定
框的尺度变换在
[0.6.1.4]之间,避免标定框过度拉伸或者变形,以至于难以学习到一个好的模型。
·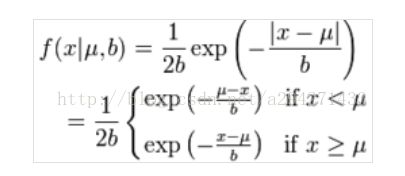
4.3训练过程
为了得到这个模型,每个训练样本都是选择性的从视频或者图片中获取。当我们使用视频作为训练时,随机选取一个视频,然后随机选取视频中的连续两帧。然后根据3.2中描述的过程对视频每一帧进行切块,另外对当前帧按照4.2中的描述取得k3个随机切块。用这k3个额外例子加强数据。接下来,随机选取一张图片,重复上诉过程。每次对一个视频或者图片进行取样,新的随机切块被得到,也使得整个训练过程多样性得到提升。在实验中,定义k3=10,每个批出的输入数据量为50。
网络中的卷积层是预先在Imagenet训练好的,因为限制训练集规模,不会对这些层进行fine-tune(微调),避免造成过拟合。整个训练过程的学习率为1e-5,其他超参数也完全选自CaffeNet网路的原始设置。
5 实验设置
5.1训练设置
如第四部分,我们通过结合视频和静态图片对网络进行训练,训练视频来源于ALOV300++,一个有着314个视频流的收藏。移除了其中七个不适合的,剩余307个用于训练。在这些数据中,大约每隔5帧就标定了一个要用于跟踪的对象,这些视频一般都很短,从几秒到几分钟不等。将这批视频的251个用于训练,56个用于验证和微调。训练集一共包含13082张图251个类。平均每个类别52张图,验证集包含2795张图片的56个类别。在设置完超参数后,我们对模型使用整个训练集进行重复训练(训练加验证)。
训练过程同时融入了一部分静态图片,如4.1中描述,这些图片来源于Imagenet挑战赛的训练数据。在训练的过程中对这些图片进行随机切块来得到两个图像块间的明显变换或者是尺度变换。随机切块处理只有当目标物体没有充满图像的整个画面时才是有用的。因此我们对图像滤波,使得框的大小在任何维度都不能超过图像尺寸的66%。这些措施有助于防止过拟合,对于网络对新检测目标的跟踪有好处。
5.2测试设置
测试集包含25个来源于VOT204跟踪挑战赛的视频,视频的每一帧都富含了大量的不同的属性:遮挡、光线变换、运动变换、尺寸变换、相机运动等。