Redis(三):常见数据结构 与 缓存击穿、缓存穿透与缓存雪崩解决
相关阅读:
Redis(一):Redis概述与常见问题
Redis(二):数据回收策略、持久化原理、事务、主从复制
Redis(三):常见数据结构 与 缓存击穿、缓存穿透与缓存雪崩
Redis(四):Redis的分布式锁实现
Redis(五):数据库 和 缓存 双写一致性
一、redis常见的数据结构以及使用场景分析:
1、String:
常用命令: set,get,decr,incr,mget等。
String数据结构是简单的key-value类型,value其实不仅可以是String,也可以是数字。一般做一些复杂的计数功能的缓存:微博数,粉丝数等。
2、Hash:
(1)常用命令:hget,hset,hgetall 等。
Hash是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象,可以方便的操作对象中的某个字段。例如做单点登录的时候,可以用这种数据结构存储用户信息,以cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。
(2)实现方式:压缩列表或者散列表。
压缩列表:类似数组,通过一片连续的内存空间,来存储数据。不过,它跟数组不同的一点是,它允许存储的数据大小不同。压缩列表这种存储结构,一方面比较节省内存,另一方面可以支持不同类型数据的存储。而且,因为数据存储在一片连续的内存空间,通过键来获取值为列表类型的数据,读取的效率也非常高。
①只有当存储的数据量比较小的情况下,Redis 才使用压缩列表来实现字典类型。具体需要满足两个条件:
a.字典中保存的键和值的大小都要小于 64 字节;
b.字典中键值对的个数要小于 512 个。
②当不能同时满足上面两个条件的时候,Redis 就使用散列表来实现字典类型,Redis 使用MurmurHash2这种运行速度快、随机性好的哈希算法作为哈希函数。并且使用链表法解决哈希冲突。除此之外,Redis 还支持散列表的动态扩容、缩容。
当数据动态增加之后,散列表的装载因子会不停地变大。为了避免散列表性能的下降,当装载因子大于 1 的时候,Redis 会触发扩容,将散列表扩大为原来大小的 2 倍左右;当数据动态减少之后,为了节省内存,当装载因子小于 0.1 的时候,Redis 就会触发缩容,缩小为字典中数据个数的大约2 倍大小。
3、List:
(1)常用命令: lpush,rpush,lpop,rpop,lrange等。
list 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销应用。
list 的应用场景非常多,比如微博的关注列表,粉丝列表,消息列表等功能都可以用Redis的 list 结构来实现。可以利用lrange命令,做基于redis的分页功能。
(2)实现方式:一种是压缩列表,另一种是双向循环链表。
①当列表中存储的数据量比较小的时候,列表就可以采用压缩列表的方方式实现:
a.列表中保存的单个数据(有可能是字符串类型的)小于 64 字节;
b.列表中数据个数少于512个。
②当列表中存储的数据量比较大的时候,也就是不能同时满足刚刚讲的的两个条件的时候,列表就要通过双向循环链表来实现了。
4、Set:
(1)常用命令:sadd,spop,smembers,sunion等。
因为set堆放的是一堆不重复值的集合,所以可以做全局去重的功能。并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。可以基于 set 轻易实现交集、并集、差集的操作,计算共同喜好,全部的喜好,自己独有的喜好等功能。
sinterstore key1 key2 key3 将交集存在key1内。
(2)实现方式:有序数组或者散列表。
①当要存储的数据,同时满足下面这样两个条件的时候,Redis 就采用有序数组,来实现集合这种数据类型:
a.存储的数据都是整数;
b.存储的数据元素个数不超过512个。
②当不能同时满足这两个条件的时候,Redis 就使用散列表来存储集合中的数据。
5、Sorted Set:
(1)常用命令:zadd,zrange,zrem,zcard等
Sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。另外,sorted set可以用来做延时任务。最后一个应用就是可以做范围查找。
(2)实现方式:压缩列表和跳表。
①使用压缩列表来实现有序集合的前提,有这样两个:
a.所有数据的大小都要小于 64 字节;
b.元素个数要小于 128 个。
②当不能同时满足这两个条件的时候,Redis 就使用跳表来存储有序集合中的数据。
二、缓存击穿、缓存穿透与缓存雪崩:
参考自:https://juejin.im/post/5c9a67ac6fb9a070cb24bf34?utm_source=gold_browser_extension
1、缓存穿透:
(1)缓存穿透:指利用一个数据库中一定不存在的Key,当访问缓存的时候,必然访问不到,那就会去数据库中查找。当存在一定量的并发,或者有人恶意频繁用不存在的key来访问我们的服务器的时候,那么每次请求都一定会打到数据库上面去,一定量的次数后,数据库服务器必然承受不住,宕机崩溃。
(2)解决方法:
①BloomFilter:用一个足够大的bit map (布隆过滤器),将所有可能性的key都存储在其中,如果出现一定不存在的key,拦截掉该不可能存在的请求,不让其访问数据库,从而避免了对底层存储系统的查询压力。
②缓存空值:如果出现访问数据库中不存在的key,数据库返回一个null值,然后我们把这个空结果存储在redis缓存中,并设置其过期时间极短,后面再出现查询这个key的请求的时候,直接返回null。
(3)如何选择:
针对于一些恶意攻击,攻击带过来的大量key 是不存在的,那么我们采用第二种方案就会缓存大量不存在key的数据。此时我们采用第二种方案就不合适了,我们完全可以先对使用第一种方案进行过滤掉这些key。
所以,针对这种key异常多、请求重复率比较低的数据,我们就没有必要进行缓存,使用第一种方案直接过滤掉。而对于空数据的key有限的,重复率比较高的,我们则可以采用第二种方式进行缓存。
2、缓存击穿:
(1)缓存击穿:指缓存中没有但数据库中有的数据,比如某一个热点数据,大量用户同时并发请求这个key,此时这个key正好失效,就会造成大量请求读缓存没读到数据,又同时去数据库去取数据,高并发下大量访问数据库,引起数据库压力瞬间增大,造成过大压力。
(2)解决方案:
我们可以在第一个线程查询数据的请求上使用一个互斥锁来锁住它,也就是说,在访问key之前,采用SETNX(set if not exists)来使用一个短期锁锁住当前key的访问,查询结束后做缓存,再删除该短期key。只有得到锁了的请求,才能去请求数据库,没得到锁,则休眠一段时间重试,后面来的线程进来发现已经有缓存了,接直接走缓存。
3、缓存雪崩:
(1)缓存雪崩:即缓存在同一时刻大面积的失效,比如你的缓存服务宕机了,会有大量的请求进来直接打到DB上,结果就是DB撑不住,挂掉。
(2)解决方法:
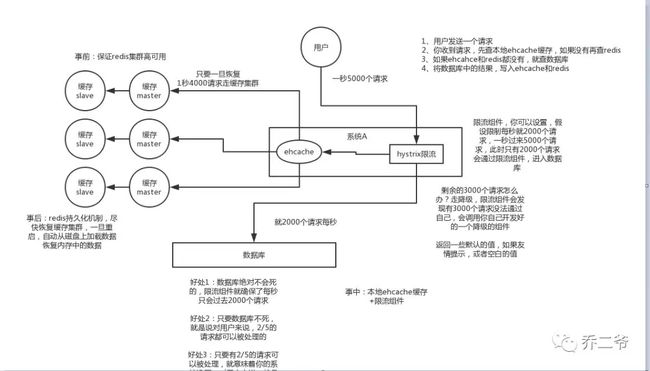
①事前:使用集群缓存,保证缓存服务的高可用:
这种方案就是在发生雪崩前对缓存集群实现高可用,如果是使用 Redis,可以使用 主从+哨兵 ,Redis Cluster 来避免 Redis 全盘崩溃的情况。、
②事中:ehcache本地缓存 + Hystrix限流&降级,避免MySQL被打死:
使用 ehcache 本地缓存的目的也是考虑在 Redis Cluster 完全不可用的时候,ehcache 本地缓存还能够支撑一阵。
使用 Hystrix进行限流 & 降级 ,比如一秒来了5000个请求,我们可以设置假设只能有一秒 2000个请求能通过这个组件,那么其他剩余的 3000 请求就会走限流逻辑。
然后去调用我们自己开发的降级组件(降级),比如设置的一些默认值呀之类的。以此来保护最后的 MySQL 不会被大量的请求给打死。
③事后:开启Redis持久化机制,尽快恢复缓存集群:
一旦重启,就能从磁盘上自动加载数据恢复内存中的数据。
防止雪崩方案如下图所示:
4、解决热点数据集中失效问题:
当我们设置的一些数据key设置缓存的时候,如果采用相同的过期时间,当达到一个过期时间临界点的时候,大部分缓存过期,这时候如果一个高并发量的访问过来,就会同时访问数据库,造成数据压力大或者崩溃。
解决方案:
①热点数据缓存永远不过期;
②可以在原有的失效时间的基础上,加上以个随机值,1-5分钟,这样就可以防止同时过期,造成大量数据库的访问。
③互斥锁在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据库和写缓存,其他线程都会被阻塞等待,知道锁被释放。但是由于它会阻塞其他的线程,此时系统吞吐量会下降。需要结合实际的业务去考虑是否要这么做