TensorFlow学习笔记(一)MNIST手写字识别
TensorFlow 是一个非常强大的用来做大规模数值计算的库。其所擅长的任务之一就是实现以及训练深度神经网络。
TensorFlow 可以拆分成 tensor 和 flow 两部分来理解,tensor 指的是张量,是维度的推广,表示更多维度的矩阵;flow 指的是流,一层层的计算可以看作是“张量”在计算模型上的流动,简单的说就是看作计算过程。
TensorFlow 的工作方式是:
- 使用图(graph)来表示计算任务.
- 在会话(Session)的上下文(context)中执行图.
- 使用 tensor 表示数据.
- 通过变量(Variable)维护状态.
- 使用 feed 和 fetch 可以为任意的操作(arbitrary operation)赋值或者从其中获取数据.
TensorFlow 程序通常被组织成一个构建阶段和一个执行阶段。在构建阶段, 节点的执行步骤被描述成一个图;在执行阶段, 使用会话执行图中的节点计算。
当我们开始学习编程的时候,第一件事往往是学习打印”Hello World”。就好比编程入门有Hello World,机器学习入门有MNIST。MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片:

它也包含每一张图片对应的标签,告诉我们这个是数字几。比如,上面这四张图片的标签分别是5,0,4,1。
这里我们搭建一个卷积神经网络来识别图中的数字。
加载MNIST数据集
首先是采用一个脚本来自动下载和导入MNIST数据集,它会自动创建一个’MNIST_data’的目录来存储数据。
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot = True)使用InteractiveSession类创建一个会话,通过它可以更加灵活地构建代码。它能在运行图的时候,插入一些计算图,如果没有使用InteractiveSession,那么需要在启动session之前构建整个计算图,然后启动该计算图。
import tensorflow as tf
sess = tf.InteractiveSession()设置输入数据的参数,x、y_用占位符表示,用来存储输入图像展开形成的向量和输入图像的标签。
x = tf.placeholder("float", shape = [None, 784])
y_ = tf.placeholder("float", shape = [None, 10])tf.placeholder(dtype, shape=None, name=None)函数可以理解为形参,用于定义过程,在执行的时候再赋具体的值,返回的是一个tensor。
参数:
- dtype:数据类型,常用的数据类型有tf.float32,tf.float64等.
- shape:数据形状,可以是一维值,也可以是多维。这里的[None, 784]和[None,10]表示的是固定列数、任意行数的数据.
- name:名称.
初始化权重
创建这个模型需要创建大量的权重和偏置项,而且权重在初始化时应该加入少量的噪声来打破对称性以及避免0梯度。我们使用的是ReLU神经元,因此比较好的做法是用一个较小的正数来初始化偏置项,以避免神经元节点输出恒为0的问题(dead neurons)。为了不在建立模型的时候反复做初始化操作,这里定义两个函数用于初始化。
#生成shape形状的标准差为0.1的正态分布中的随机值
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev = 0.1)
return tf.Variable(initial)
#生成形状为shape的值都为0.1的常量
def bias_variable(shape):
initial = tf.constant(0.1, shape = shape)
return tf.Variable(initial)tf.truncated_normal(shape, mean, stddev, dtype, seed=None, name=None)函数表示从截断的正态分布中输出随机值, 生成的值服从具有指定平均值和标准偏差的正态分布。
参数:
- shape:输出张量的维度.
- mean: 正态分布的均值.
- stddev: 正态分布的标准差.
- dtype: 输出的类型.
- seed: 一个整数,当设置之后,每次生成的随机数都一样.
- name: 操作的名字.
在正态分布的曲线中,
横轴区间(μ-2σ,μ+2σ)内的面积为95.449974%。
横轴区间(μ-3σ,μ+3σ)内的面积为99.730020%。
随机数落在(μ-3σ,μ+3σ)以外的概率小于千分之三,基本上可以把区间(μ-3σ,μ+3σ)看作是随机变量X实际可能的取值区间,这称之为正态分布的“3σ”原则。
如果随机数的取值在区间(μ-2σ,μ+2σ)之外则重新进行选择,这样保证了生成的值都在均值附近。
tf.constant (value, dtype=None, shape=None, name=’Const’)函数创建一个tensor常量。
参数:
- value:常量的值。value可以是一个数,也可以是一个list。如果是一个数,那么这个常量中所有值的按该数来赋值。 如果是list,那么len(value)一定要小于等于shape展开后的长度,赋值时,先将value中的值逐个存入,不够的部分,则全部存入value的最后一个值.
- dtype: 输出的类型.
- shape:输出张量的维度.
- name:操作的名字.
卷积和池化
卷积使用1步长(stride size),0边距(padding size)的模板,保证输出和输入是同一个大小。池化用简单传统的2x2大小的模板做max pooling。为了代码更简洁,把这部分抽象成一个函数。
#输入图像为x,卷积核为W,步长为1*1,填充方式为SAME
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides = [1,1,1,1], padding='SAME')
#输入图像为x,池化窗口大小为2*2,步长为2*2,填充方式为SAME
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1,2,2,1], padding='SAME')tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)函数用来实现卷积,结果返回一个Tensor,这个输出就是feature map。
参数:
input:指需要做卷积的输入图像,它要求是一个Tensor,具有 [batch, in__height, in_width, in_channels] 这样的shape,含义是:训练batch个图片,图片高度为in_height,图片宽度为in_width, 图像通道数为:in_channels。这是一个4维的Tensor,要求类型为float32和float64其中之一.
filter:相当于CNN中的卷积核,它要求是一个Tensor,具有 [filter_height, filter_width, in_channels, out_channels] 这样的 shape,代表的含义是对输入为 in_channels通道数的图像进行卷积,卷积核的高度为 filter_height,卷积核的宽度为 filter_width,卷积核个数为out_channels,也就是生成卷积层的个数。这里要求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维,输入图像的通道数.
strides:卷积时在图像每一维的步长,这是一个一维的向量,长度4.
padding:string类型的量,只能是”SAME”,”VALID”其中之一,这个值决定了不同的卷积方式。
use_cudnn_on_gpu:bool类型,是否使用cudnn加速,默认为true.
name: 为操作的名字.
关于”SAME”和”VALID”的不同,这里举个例子来说明:

在例子中,Input width=13,Filter width=6,Stride=5。
“SAME”指的是补全方式,当滑动窗口滑动到不足一个窗口时,采用的“0”填充。若填充的个数为偶数,则左右填充相同个数的“0”,若填充的个数为奇数,则采用左奇右偶的原则,左边填充奇数个“0”,右边填充偶数个“0”。对于上述的情况,允许滑动3次,但是需要补3个元素,左奇右偶,在左边补一个0,右边补2个0。
“VALID”指的是丢弃方式,当滑动窗口滑动到不足一个窗口时,多余元素全部丢掉。
tf.nn.max_pool(value, ksize, strides, padding, name=None)函数返回一个Tensor,类型不变。
参数:
value:需要池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,依然是[batch, height, width, channels]这样的shape.
ksize:池化窗口的大小,取一个四维向量,一般是[1, height, width, 1],因为不想在batch和channels上做池化,所以这两个维度设为了1.
strides:和卷积类似,表示窗口在每一个维度上滑动的步长,一般也是[1, stride,stride, 1].
padding:和卷积类似,可以取’VALID’ 或者’SAME’.
第一层卷积层
第一层由一个卷积接一个max pooling完成。卷积在每个5x5的patch中算出32个特征。卷积的权重张量形状是[5, 5, 1, 32],前两个维度是patch的大小,接着是输入的通道数目,最后是输出的通道数目。 而对于每一个输出通道都有一个对应的偏置量。
#生成权重和偏置项
W_conv1 = weight_variable([5,5,1,32])
b_conv1 = bias_variable([32])为了用这一层,需要把输入的图像变成一个4维向量,其第2、第3维对应图片的宽、高,最后一维代表图片的颜色通道数。这里采用的图像是灰度图像,因此最后一维为1。
x_image = tf.reshape(x, [-1, 28, 28, 1])tf.reshape(tensor, shape, name=None) 函数的作用是将tensor变换为参数shape的形式。
参数:
- tensor:需要改变形状的tensor.
- shape:一个列表形式,特殊的一点是列表中可以存在-1。-1代表的含义是不用我们自己指定这一维的大小,函数会自动计算,但列表中只能存在一个-1(如果存在多个-1,就是一个存在多解的方程了)。
我们把x_image和权值进行卷积,加上偏置项,然后应用ReLU激活函数,最后进行max pooling。
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)第二层卷积层
为了构建一个更深的网络,通常会把几个类似的层堆叠起来。第二层中,每个5x5的patch会得到64个特征。
W_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)密集连接层
现在,图片尺寸减小到7x7,我们加入一个有1024个神经元的全连接层,用于处理整个图片。首先把池化层输出的张量reshape成需要的形状,乘上权重矩阵,加上偏置,然后对其使用ReLU。
#密集连接层的权重和偏置
W_fc1 = weight_variable([7*7*64, 1024])
b_fc1 = bias_variable([1024])
#把第二卷积层输出的张量重组为任意行,7*7*64列的张量
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)Dropout
为了减少过拟合,可以在输出层之前加入dropout。我们用一个placeholder来代表一个神经元的输出在dropout中保持不变的概率。这样我们可以在训练过程中启用dropout,在测试过程中关闭dropout。 TensorFlow的tf.nn.dropout操作除了可以屏蔽神经元的输出外,还会自动处理神经元输出值的scale,所以用dropout的时候可以不用考虑scale。
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)tf.nn.dropout(x, keep_prob, noise_shape=None, seed=None, name=None)函数可以根据给出的keep_prob参数,将输入tensor x按比例输出。
参数:
- x:输入的tensor.
- keep_prob:float类型,每个元素被保留下来的概率.
- noise_shape:一个1维的int32张量,代表了随机产生“保留/丢弃”标志的shape.
- seed:整形变量,随机数种子.
输出层
这里采用softmax回归进行分类,把向量化后的图片x和权重矩阵W相乘,加上偏置b,然后计算每个分类的softmax概率值。
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)训练和评估模型
为了训练模型,首先需要定义一个成本函数或者损失函数来评估这个模型的好坏。这里采用的是一个非常常见的成本函数“交叉熵”(cross-entropy)。它的定义如下:
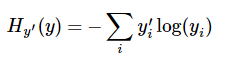
y 是预测的概率分布, y’ 是实际的分布(输入的one-hot vector),可以粗略的解释为交叉熵是用来衡量我们的预测用于描述真相的低效性。
#初始化变量
sess.run(tf.global_variables_initializer())
#交叉熵
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))tf.reduce_sum(input_tensor, axis=None, keep_dims=False, name=None, reduction_indices=None)函数用来计算输入tensor元素的和。
参数:
- input_tensor:输入的张量.
- axis:在哪个维度进行求和操作.
- keep_dims:是否保留原始数据的维度,False相当于执行完后原始数据就会少一个维度.
- reduction_indices:为了跟旧版本的兼容,现在已经不使用了.
TensorFlow拥有一张描述各个计算单元的图,它可以自动地使用反向传播算法来有效地确定变量是如何影响需要最小化的那个成本值的。然后,TensorFlow会用已选择的优化算法来不断地修改变量以降低成本。这里采用用ADAM优化器来做梯度最速下降。
#使用梯度下降法最小化成本函数,学习率为1e-4
train_step = tf.train.AdamOptimizer(1e-4) .minimize(cross_entropy)在训练样本过程中,我们想要知道训练的精度怎么样,训练好模型之后,也想知道测试的精度怎么样。首先需要找出那些预测正确的标签,tf.argmax函数能给出某个tensor对象在某一维上的其数据最大值所在的索引值,也就是类别标签。使用tf.equal函数得到的是一组布尔值,为了计算正确预测项的比例,我们可以把布尔值转换成浮点数,然后取平均值。例如,[True, False, True, True] 会变成 [1,0,1,1] ,取平均值后得到 0.75,即为预测的正确率。
#判断预测的标签是否正确
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
#正确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))tf.argmax(input, axis=None, name=None, dimension=None)函数是对矩阵按行或列计算最大值,返回Tensor的行或列的最大值下标向量。
参数:
- input:输入Tensor.
- axis:在哪个维度上进行运算,0表示按列,1表示按行.
- dimension:和axis功能一样,默认axis取值优先,是新加的字段.
tf.equal(A, B)函数是对比两个矩阵或者向量的元素是否相等,如果是相等的那就返回True,否则返回False,返回的值的维度和A是一样的。
tf.cast(x, dtype, name=None)函数是类型转换函数,将 x 的数据格式转化成dtype类型的,返回一个tensor。
tf.reduce_mean(input_tensor, reduction_indices=None, keep_dims=False, name=None)函数是按某一维度(reduction_indices)计算一个张量的所有元素的平均值,参数与tf.reduce_sum()函数类似。
这里我们让模型循环训练20000次,每次该循环都会随机抓取训练数据中的50个批处理数据点,然后用这些数据点作为参数替换之前的占位符 x和y_ ,同时在feed_dict中加入额外的参数keep_prob来控制dropout比例。运行 train_step,每循环100次,打印一次预测的精度。
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict = {x:batch[0],y_:batch[1], keep_prob:0.5})
print("step %d, training accuracy %g" % (i, train_accuracy))
train_step.run(feed_dict={x:batch[0], y_:batch[1],keep_prob:0.5})accuracy.eval(feed_dict=None, session=None)函数的作用是:在一个Seesion里面“评估”tensor的值(其实就是计算),首先执行之前的所有必要的操作来产生这个计算的tensor需要的输入,然后通过这些输入产生这个tensor。在激发tensor.eval()这个函数之前,tensor的图必须已经投入到session里面,或者一个默认的session是有效的,或者显式指定session。返回表示“计算”结果值的数组。
参数:
- feed_dict:一个字典,用来表示tensor被feed的值(之前已经用placeholder定义过的)
- session:用来计算这个tensor的session,要是没有指定的话,那么就会使用默认的session。
最后,我们计算训练好的的模型在测试数据集上面的正确率。
print("test accuracy %g" % accuracy.eval(feed_dict={x:mnist.test.images, y_:mnist.test.labels, keep_prob:1.0}))以上代码,在最终测试集上的准确率大概是99%。
以上是我学习TensorFlow的第一节笔记,可能不是很完善和准确,有不准确的地方欢迎大家指正!