流畅的Python之奇技淫巧(一)
第1章 Python数据类型
1.3 特殊方法一览
原文如下
Python 语言参考手册中的“Data Model”(https://docs.python.org/3/reference/datamodel.html)
一章列出了 83 个特殊方法的名字,其中 47 个用于实现算术运算、位运算和比较操作。
表 1-1 和表 1-2 列出了这些方法的概况。※奇技淫巧之魔法方法的巧妙使用
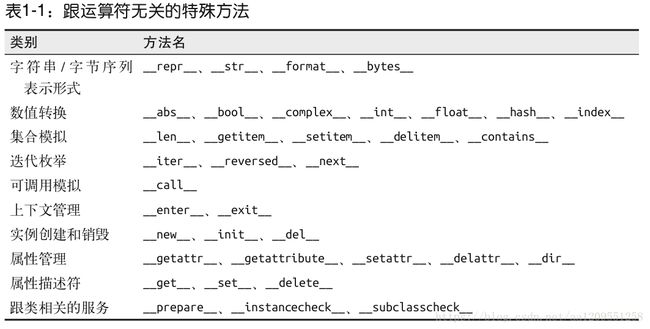

注! 当交换两个操作数的位置时,就会调用反向运算符( b * a 而不是 a * b )。增量赋值运算符则是一种把中缀运算符变成赋值运算的捷径( a = a * b 就变成了 a *= b )。第 13 章会对这两者作出详细解释。注意标准模板
第2章 序列构成的数组
2.1 内置序列类型概览
Python 标准库用 C 实现了丰富的序列类型,列举如下。
- 容器序列
- list 、 tuple 和 collections.deque 这些序列能存放不同类型的数据。
- 扁平序列
- str 、 bytes 、 bytearray 、 memoryview 和 array.array ,这类序列只能容纳一种类型。
- 可变序列
- list 、 bytearray 、 array.array 、 collections.deque 和 memoryview 。
- 不可变序列
- tuple 、 str 和 bytes 。
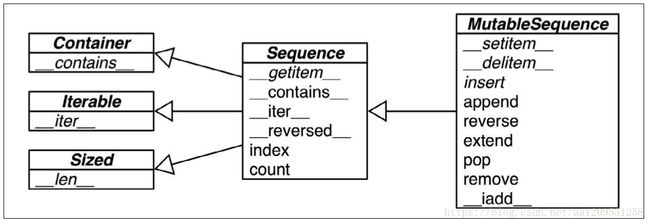
注! 容器序列存放的是它们所包含的任意类型的对象的引用,而扁平序列里存放的是值而不是 引用。换句话说,扁平序列其实是一段连续的内存空间。由此可见扁平序列其实更加紧凑,但是它里面只能存放诸如字符、字节和数值这种基础类型。 序列类型还能按照能否被修改来分类。
图 2-1 显示了可变序列( MutableSequence )和不可变序列( Sequence )的差异,同时也
能看出前者从后者那里继承了一些方法。虽然内置的序列类型并不是直接从 Sequence 和
MutableSequence 这两个抽象基类(Abstract Base Class,ABC)继承而来的,但是了解这
些基类可以帮助我们总结出那些完整的序列类型包含了哪些功能
2.2 列表推导和生成器表达式
2.2.1 列表推导和可读性
Python2中列表推倒式会有变量泄露问题,而Python3中不存在的~
**列表推导不会再有变量泄漏的问题**
Python 2.x 中,在列表推导中 for 关键词之后的赋值操作可能会影响列表推导上下文中
的同名变量。像下面这个 Python 2.7 控制台对话:
Python 2.7.6 (default, Mar 22 2014, 22:59:38)
[GCC 4.8.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> x = 'my precious'
>>> dummy = [x for x in 'ABC']
>>> x
'C'
如你所见, x 原本的值被取代了,但是这种情况在 Python 3 中是不会出现的。
列表推导、生成器表达式,以及同它们很相似的集合( set )推导和字典( dict )推
导,在 Python 3 中都有了自己的局部作用域,就像函数似的。表达式内部的变量和赋
值只在局部起作用,表达式的上下文里的同名变量还可以被正常引用,局部变量并不
会影响到它们。
这是 Python 3 代码:
>>> x = 'ABC'
>>> dummy = [ord(x) for x in x]
>>> x ➊
'ABC'
>>> dummy ➋
[65, 66, 67]
>>>
➊ x 的值被保留了。
➋ 列表推导也创建了正确的列表。2.2.3 笛卡儿积
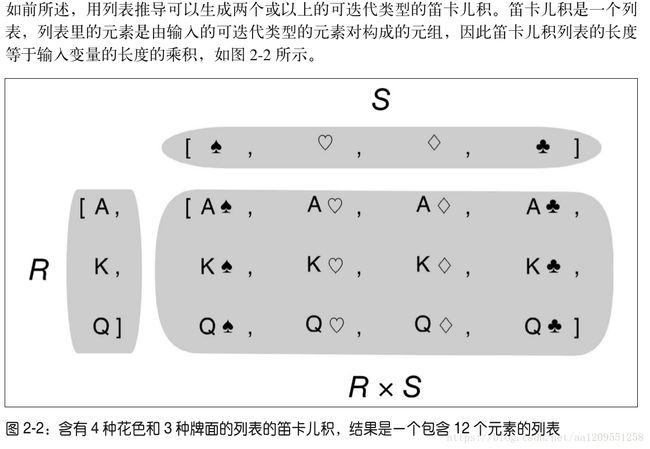
※奇技淫巧之列表推导式的巧妙使用
示例 2-4 使用列表推导计算笛卡儿积
>>> colors = ['black', 'white']
>>> sizes = ['S', 'M', 'L']
>>> tshirts = [(color, size) for
>>> tshirts
[('black', 'S'), ('black', 'M'),('black', 'L'), ('white', 'S'),('white', 'M'), ('white', 'L')]
>>> for color in colors: ➋
... for size in sizes:
... print((color, size))
...
('black', 'S')
('black', 'M')
('black', 'L')
('white', 'S')
('white', 'M')
('white', 'L')
>>> tshirts = [(color, size) for size in sizes for color in colors]➌
>>> tshirts
[('black', 'S'), ('white', 'S'),('black', 'M'), ('white', 'M'),('black', 'L'), ('white', 'L')]
➊ 这里得到的结果是先以颜色排列,再以尺码排列。
➋ 注意,这里两个循环的嵌套关系和上面列表推导中 for 从句的先后顺序一样。
➌ 如果想依照先尺码后颜色的顺序来排列,只需要调整从句的顺序。我在这里插入了一个
换行符,这样顺序安排就更明显了。
在第 1 章的示例 1-1 中,有下面这样一段程序注!生成器表达式即将
[]换为()即可.
2.3.4 具名元组
collections.namedtuple 是一个工厂函数,它可以用来构建一个带字段名的元组和一个有名字的类——这个带名字的类对调试程序有很大帮助。
注!用 namedtuple 构建的类的实例所消耗的内存跟元组是一样的,因为字段名都被存在对应的类里面。这个实例跟普通的对象实例比起来也要小一些,因为Python 不会用 dict 来存放这些实例的属性。
示例 2-9 定义和使用具名元组
>>> from collections import namedtuple
>>> City = namedtuple('City', 'name country population coordinates')➊
>>> tokyo = City('Tokyo', 'JP', 36.933, (35.689722, 139.691667))➋
>>> tokyo
City(name='Tokyo', country='JP', population=36.933, coordinates=(35.689722,139.691667))
>>> tokyo.population➌
36.933
>>> tokyo.coordinates
(35.689722, 139.691667)
>>> tokyo[1]
'JP'
➊ 创建一个具名元组需要两个参数,一个是类名,另一个是类的各个字段的名字。后者可以是由数个字符串组成的可迭代对象,或者是由空格分隔开的字段名组成的字符串。
➋ 存放在对应字段里的数据要以一串参数的形式传入到构造函数中(注意,元组的构造函数却只接受单一的可迭代对象)。
➌ 你可以通过字段名或者位置来获取一个字段的信息。
除了从普通元组那里继承来的属性之外,具名元组还有一些自己专有的属性。示例 2-10 中就展示了几个最有用的: _fields 类属性、类方法 _make(iterable) 和实例方法 _asdict() 。
示例 2-10 具名元组的属性和方法(接续前一个示例)
>>> City._fields➊
('name', 'country', 'population', 'coordinates')
>>> LatLong = namedtuple('LatLong', 'lat long')
>>> delhi_data = ('Delhi NCR', 'IN', 21.935, LatLong(28.613889, 77.208889))
>>> delhi = City._make(delhi_data)➋
>>> delhi._asdict()➌
OrderedDict([('name', 'Delhi NCR'), ('country', 'IN'), ('population',21.935), ('coordinates', LatLong(lat=28.613889, long=77.208889))])
>>> for key, value in delhi._asdict().items():
print(key + ':', value)
name: Delhi NCR
country: IN
population: 21.935
coordinates: LatLong(lat=28.613889, long=77.208889)
>>>
➊ _fields 属性是一个包含这个类所有字段名称的元组。
➋ 用 _make()通过接受一个可迭代对象来生成这个类的一个示例,它的做工跟City(*delhi_data) 是一样的。
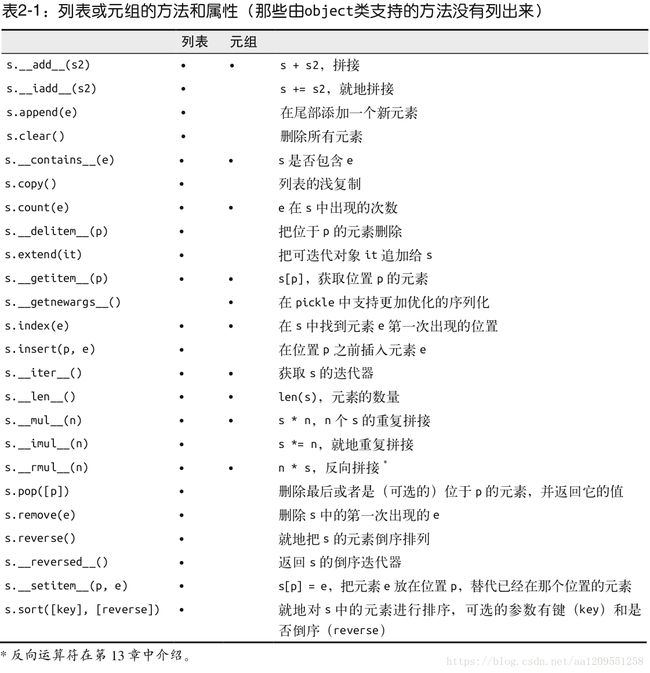
➌ _asdict() 把具名元组以 collections.OrderedDict 的形式返回,我们可以利用它来把元组里的信息友好地呈现出来。2.3.5 列表与元祖底层实现的魔法方法对比(作为不可变列表的元组)
2.4.3 多维切片和省略
- 切片
[]运算符里还可以使用以逗号分开的多个索引或者是切片,外部库 NumPy 里就用到了这
个特性,二维的 numpy.ndarray 就可以用a[i, j]这种形式来获取,抑或是用a[m:n, k:l]
的方式来得到二维切片。稍后的示例 2-22 会展示这个用法。要正确处理这种[]运算符的
话,对象的特殊方法__getitem__和__setitem__需要以元组的形式来接收a[i, j]中的索
引。也就是说,如果要得到a[i, j]的值,Python 会调用a.__getitem__((i, j))
- 省略
- 省略(ellipsis)的正确书写方法是三个英语句号( … ),而不是 Unicdoe 码位 U+2026 表示的半个省略号(…)。省略在 Python 解析器眼里是一个符号,而实际上它是 Ellipsis 对象的别名,而 Ellipsis 对象又是 ellipsis 类*的单一实例。 2 它可以当作切片规范的一部分,也可以用在函数的参数清单中,比如 f(a, …, z) ,或 a[i:…] 。在 NumPy 中, … 用作多维数组切片的快捷方式。如果 x 是四维数组,那么 x[i, …] 就是 x[i, :, :, :] 的缩写*。如果想了解更多,请参见“Tentative NumPy Tutorial”(http://wiki.scipy.org/Tentative_NumPy_Tutorial)
2.4.4 给切片赋值
>>> l = list(range(10))
>>> l
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 创建出来的列表l
>>> l[2:5] = [20, 30] # 1.给切片赋值
>>> l
[0, 1, 20, 30, 5, 6, 7, 8, 9]
>>> del l[5:7] # 2.切片删除
>>> l
[0, 1, 20, 30, 5, 8, 9]
>>> l[3::2] = [11, 22] # 3.切片赋值
>>> l
[0, 1, 20, 11, 5, 22, 9]
>>> l[2:5] = 100 ➊ # 错误类型展示
Traceback (most recent call last):
File "" , line 1, in
TypeError: can only assign an iterable
>>> l[2:5] = [100]
>>> l
[0, 1, 100, 22, 9]
➊ 如果赋值的对象是一个切片,那么赋值语句的右侧必须是个可迭代对象。即便只有单独
一个值,也要把它转换成可迭代的序列。 2.5 对序列使用 + 和 *
如果想要把一个序列复制几份然后再拼接起来,更快捷的做法是把这个序列乘以一个整
数。同样,这个操作会产生一个新序列:
>>> l = [1, 2, 3]
>>> l * 5
[1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3]
>>> 5 * 'abcd'
'abcdabcdabcdabcdabcd'+ 和 * 都遵循这个规律,不修改原有的操作对象,而是构建一个全新的序列。
注! 注! 如果在
a * n这个语句中,序列 a 里的元素是对其他可变对象的引用的话,你就需要格外注意了,因为这个式子的结果可能会出乎意料。比如,你想用my_list = [[]] * 3来初始化一个由列表组成的列表,但是你得到的列表里包含的 3 个元素其实是 3 个引用,而且这3 个引用指向的都是同一个列表。这可能不是你想要的效果。
示例 2-12 一个包含 3 个列表的列表,嵌套的 3 个列表各自有 3 个元素来代表井字游戏的一行方块
>>> board = [['_'] * 3 for i in range(3)] ➊
>>> board
[['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]
>>> board[1][2] = 'X' ➋
>>> board
[['_', '_', '_'], ['_', '_', 'X'], ['_', '_', '_']]
➊ 建立一个包含 3 个列表的列表,被包含的 3 个列表各自有 3 个元素。打印出这个嵌套列表。
➋ 把第 1 行第 2 列的元素标记为 X ,再打印出这个列表。
示例 2-13 展示了另一个方法,这个方法看上去是个诱人的捷径,但实际上它是错的。
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
示例 2-13 含有 3 个指向同一对象的引用的列表是毫无用处的
>>> weird_board = [['_'] * 3] * 3 ➊
>>> weird_board
[['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]
>>> weird_board[1][2] = 'O' ➋
>>> weird_board
[['_', '_', 'O'], ['_', '_', 'O'], ['_', '_', 'O']]
➊ 外面的列表其实包含 3 个指向同一个列表的引用。当我们不做修改的时候,看起来都还好。
➋ 一旦我们试图标记第 1 行第 2 列的元素,就立马暴露了列表内的 3 个引用指向同一个对象的事实。2.6 序列的增量赋值
增量赋值运算符
+=和*=+=背后的特殊方法是__iadd__(用于“就地加法”)。
但是如果一个类没有实现这个方法的话,Python 会退一步调用__add__eg:–>
a += b如果a 实现 了__iadd__方法,就会调用这个方法。同时对可变序列(例如list、bytearray和array.array)来说, a 会就地改动,就像调用了a.extend(b)一样了:首先计算a + b,得到一个新的对象,然后赋值给 a。也就是说,在这个表达式中,变量名会不会被关联到新的对象,完全取决于这个类型有没有实现__iadd__这个方法。类似的
*=相对应的是__imul__和__mul__
接下来有个小例子,展示的是 *= 在可变和不可变序列上的作用:
>>> l = [1, 2, 3]
>>> id(l)
4311953800 # ➊ 刚开始时列表的ID。
>>> l *= 2
>>> l
[1, 2, 3, 1, 2, 3]
>>> id(l)
4311953800 # ➋ 运用增量乘法后,列表的 ID 没变,新元素追加到列表上。
>>> t = (1, 2, 3)
>>> id(t)
4312681568 # ➌ 元组最开始的 ID。
>>> t *= 2
>>> id(t)
4301348296 # ➍ 运用增量乘法后,新的元组被创建。注!对不可变序列进行重复拼接操作的话,效率会很低,因为每次都有一个新对象,而解释器需要把原来对象中的元素先复制到新的对象里,然后再追加新的元素。(str 是一个例外,因为对字符串做 += 实在是太普遍了,所以 CPython 对它做了优化。为 str 初始化内存的时候,程序会为它留出额外的可扩展空间,因此进行增量操作的时候,并不会涉及复制原有字符串到新位置这类操作。)
**一个关于 += 的谜题**
读完下面的代码,然后回答这个问题:
示例 2-14 中的两个表达式到底会产生什么结果? 回答之前不要用控制台去运行这两个式子。
示例 2-14 一个谜题
>>> t = (1, 2, [30, 40])
>>> t[2] += [50, 60]
到底会发生下面 4 种情况中的哪一种?
a. t 变成 (1, 2, [30, 40, 50, 60]) 。
b. 因为 tuple 不支持对它的元素赋值,所以会抛出 TypeError 异常。
c. 以上两个都不是。
d. a 和 b 都是对的。
哈哈哈哈~~~~此处插入裘千仞老前辈的枣核之笑^(* ̄(oo) ̄)^
正确答案为 d! 你答对了嘛 详情见示例 2-15
示例 2-15 没人料到的结果: t[2] 被改动了,但是也有异常抛出➊
>>> t = (1, 2, [30, 40])
>>> t[2] += [50, 60]
Traceback (most recent call last):
File "" , line 1, in
TypeError: 'tuple' object does not support item assignment
>>> t
(1, 2, [30, 40, 50, 60])
➊有读者提出,如果写成 t[2].extend([50, 60]) 就能避免这个异常。确实是这样,但这个例子是为了展示这种奇怪的现象而专门写的。
有兴趣的,或者不理解其中的奥秘的,Python Tutor(http://www.pythontutor.com是一个对 Python 运行原理进行可视化分析的工具)进行分析拆解. ※奇技淫巧之字节码查看代码执行的巧妙使用
示例 2-16 s[a] = b 背后的字节码
>>> import dis
>>> dis.dis('s[a] += b')
1 0 LOAD_NAME 0 (s)
2 LOAD_NAME 1 (a)
4 DUP_TOP_TWO
6 BINARY_SUBSCR ➊
8 LOAD_NAME 2 (b)
10 INPLACE_ADD ➋
12 ROT_THREE
14 STORE_SUBSCR ➌
16 LOAD_CONST 0 (None)
18 RETURN_VALUE
>>>
➊ 将 s[a] 的值存入 TOS (Top Of Stack,栈的顶端)。
➋ 计算 TOS += b 。这一步能够完成,是因为 TOS 指向的是一个可变对象(也就是示例 2-15里的列表)。
➌ s[a] = TOS 赋值。这一步失败,是因为 s 是不可变的元组(示例 2-15 中的元组 t )。
至此我得到3粒精华。
• 不要把可变对象放在元组里面。
• 增量赋值不是一个原子操作。我们刚才也看到了,它虽然抛出了异常,但还是完成了操作。
• 查看 Python 的字节码并不难,而且它对我们了解代码背后的运行机制很有帮助。2.7 list.sort() 方法和内置函数 sorted(list)
>>> a = [5, 2, 1, 3, 4, 0] # 定义列表a
>>> xx = a.sort() # 对a进行排序
>>> a # 查看a的值
[0, 1, 2, 3, 4, 5] # WC?被改变了
>>> xx # 查看返回值
>>> print(xx) # 返回值为None
None
----------- 华丽的分割线之sorted() ----------------
>>> b = [3, 5, 1, 7, 6, 8] # 定义列表b
>>> yy = sorted(b) # 对b进行排序
>>> b # 查看b的值
[3, 5, 1, 7, 6, 8] # 嗯哼~ 小伙子立场坚定
>>> yy # 查看返回值, 呦~ 还创造了下一代
[1, 3, 5, 6, 7, 8]
>>>关于list.sort() 和sorted(list)都有的参数
- reverse
- True为被排序的序列里的元素会以降序输出,默认值是 False 。
- key
- eg:–> key=str.lower来实现忽略大小写的排序,或 key=len 进行基于字符串长度的排序。
下面通过这个小例子来看看这两个函数和它们的关键字参数:
>>> fruits = ['grape', 'raspberry', 'apple', 'banana']
>>> sorted(fruits)
['apple', 'banana', 'grape', 'raspberry'] ➊
>>> fruits
['grape', 'raspberry', 'apple', 'banana'] ➋
>>> sorted(fruits, reverse=True)
['raspberry', 'grape', 'banana', 'apple'] ➌
>>> sorted(fruits, key=len)
['grape', 'apple', 'banana', 'raspberry'] ➍
>>> sorted(fruits, key=len, reverse=True)
['raspberry', 'banana', 'grape', 'apple'] ➎
>>> fruits
['grape', 'raspberry', 'apple', 'banana'] ➏
>>> fruits.sort() ➐
>>> fruits
['apple', 'banana', 'grape', 'raspberry'] ➑
>>>
➊新建了一个按照字母排序的字符串列表。
➋原列表并没有变化。
➌按照字母降序排序。
➍新建一个按照长度排序的字符串列表。因为这个排序算法是稳定的,grape 和 apple 的长度都是 5,它们的相对位置跟在原来的列表里是一样的。
➎按照长度降序排序的结果。结果并不是上面那个结果的完全翻转,因为用到的排序算法是稳定的,也就是说在长度一样时,grape 和 apple 的相对位置不会改变。
➏直到这一步,原列表 fruits 都没有任何变化。
➐对原列表就地排序,返回值 None 会被控制台忽略。
➑此时 fruits 本身被排序。未完待续…
!!!版权声明!!!
本系列为博主学心得与体会,所有内容均为原创(✿◡‿◡)
欢迎传播、复制、修改。引用、转载等请注明转载来源。感谢您的配合
用于商业目的,请与博主采取联系,并请与原书版权所有者联系,谢谢!\(≧▽≦)/
!!!版权声明!!!
《流畅的Python》
著 [巴西] Luciano Ramalho
译 安 道 吴 珂
2017年 5 月北京第 1 次印刷
感谢编、著、译、等等

生活嘛~ 最重要的就是开心喽~ O(∩_∩)O~~