hanlp和jieba等六大中文分工具的测试对比
本篇文章测试的哈工大LTP、中科院计算所NLPIR、清华大学THULAC和jieba、FoolNLTK、HanLP这六大中文分词工具是由 水...琥珀 完成的。相关测试的文章之前也看到过一些,但本篇阐述的可以说是比较详细的了。这里就分享一下给各位朋友!
安装调用
jieba“结巴”中文分词:做最好的 Python 中文分词组件
THULAC清华大学:一个高效的中文词法分析工具包
FoolNLTK可能不是最快的开源中文分词,但很可能是最准的开源中文分词
教程:FoolNLTK 及 HanLP使用
HanLP最高分词速度2,000万字/秒
**中科院 Ictclas 分词系统 - NLPIR汉语分词系统
哈工大 LTP
LTP安装教程[python 哈工大NTP分词 安装pyltp 及配置模型(新)]
如下是测试代码及结果

下面测试的文本上是极易分词错误的文本,分词的效果在很大程度上就可以提现分词器的分词情况。接下来验证一下,分词器的宣传语是否得当吧。

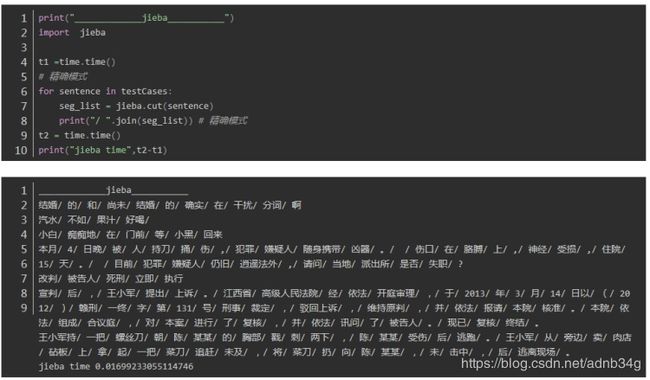
jieba 中文分词
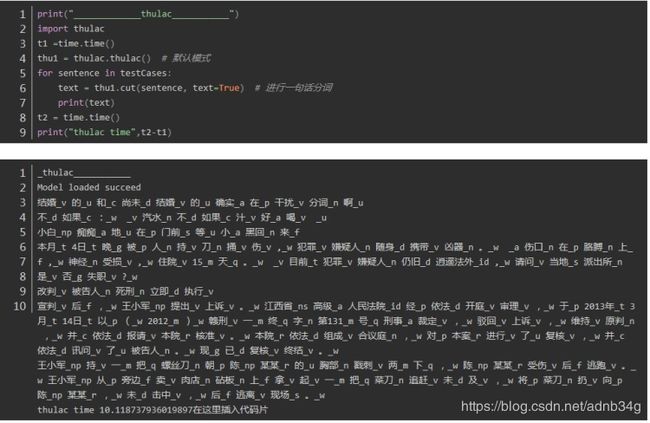
thulac 中文分词
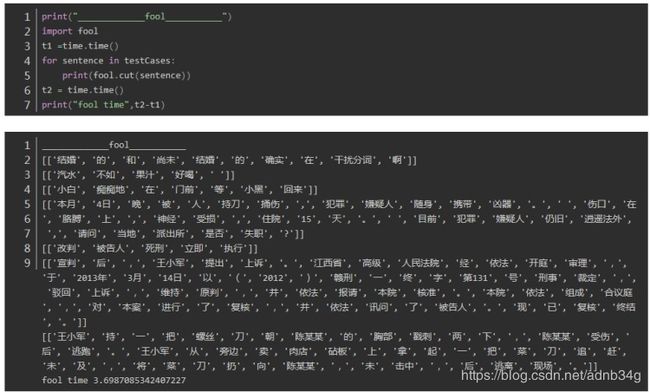
fool 中文分词
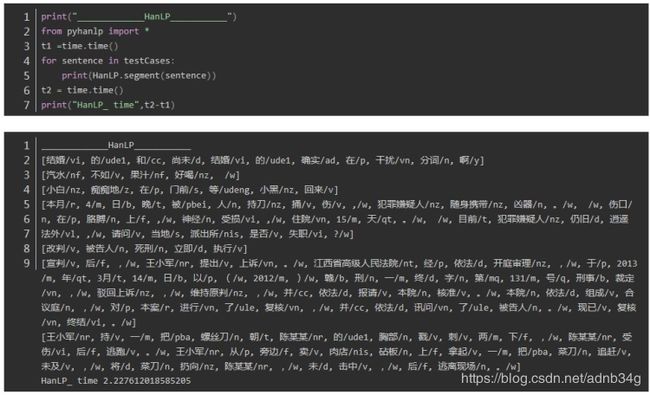
HanLP 中文分词
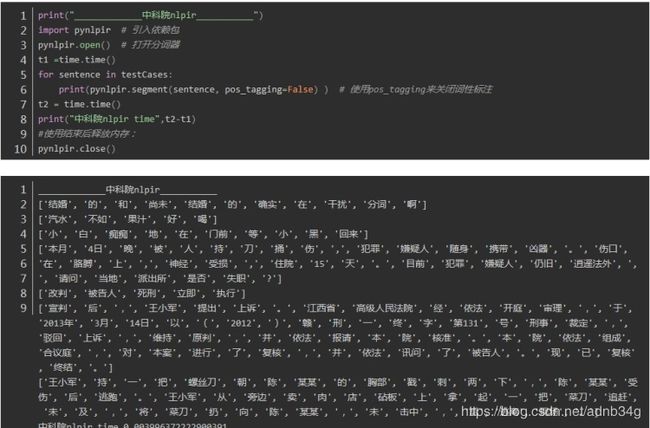
中科院分词 nlpir
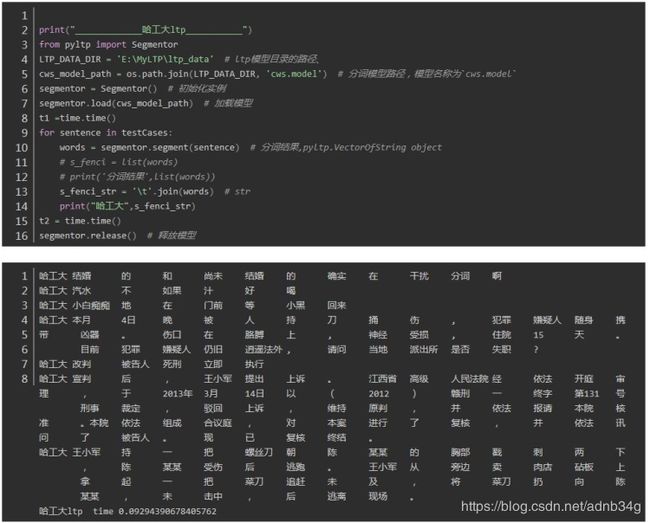
哈工大ltp 分词
以上可以看出分词的时间,为了方便比较进行如下操作:
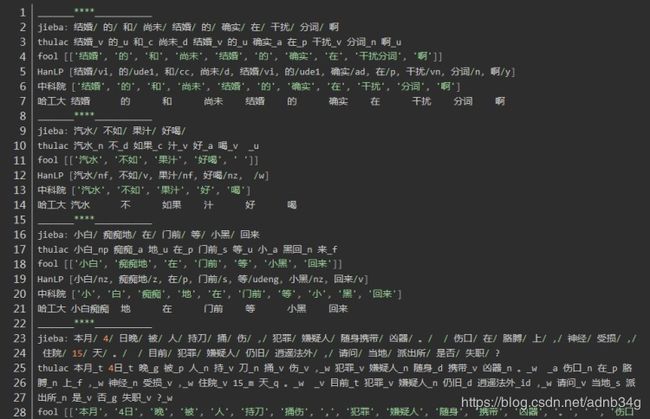
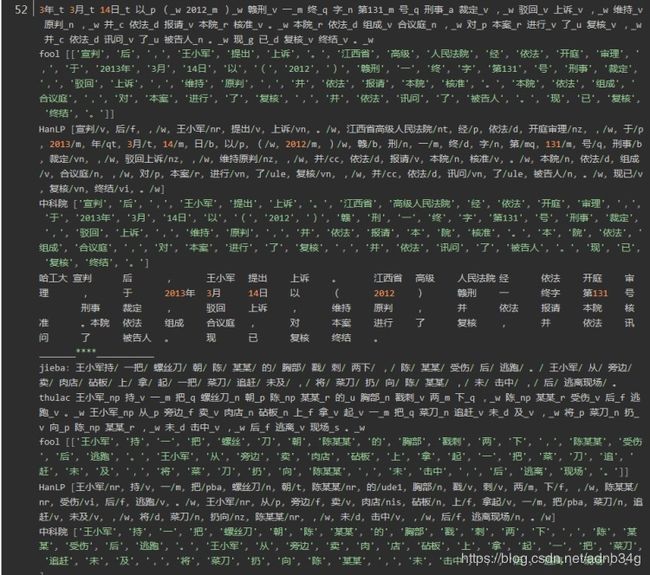
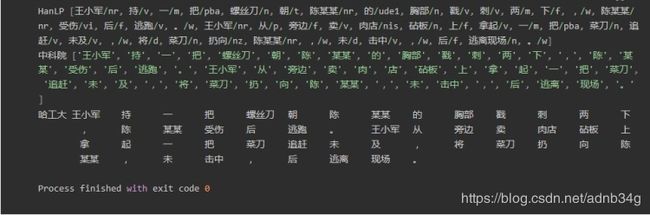
分词效果对比

结果为:

总结:
1.时间上(不包括加载包的时间),对于相同的文本测试两次,四个分词器时间分别为:
jieba: 0.01699233055114746 1.8318662643432617
thulac : 10.118737936019897 8.155954599380493
fool: 2.227612018585205 2.892209053039551
HanLP: 3.6987085342407227 1.443108320236206
中科院nlpir:0.002994060516357422
哈工大ltp_ :0.09294390678405762
可以看出平均耗时最短的是中科院nlpir分词,最长的是thulac,时间的差异还是比较大的。
2.分词准确率上,通过分词效果操作可以看出
第一句:结婚的和尚未结婚的确实在干扰分词啊
四个分词器都表现良好,唯一不同的是fool将“干扰分词”合为一个词
第二句:汽水不如果汁好喝,重点在“不如果”,“”不如“” 和“”如果“” 在中文中都可以成词,但是在这个句子里是不如 与果汁 正确分词
jieba thulac fool HanLP
jieba、 fool 、HanLP正确 thulac错误
第三句: 小白痴痴地在门前等小黑回来,体现在人名的合理分词上
正确是:
小白/ 痴痴地/ 在/ 门前/ 等/ 小黑/ 回来
jieba、 fool 、HanLP正确,thulac在两处分词错误: 小白_np 痴痴_a 地_u 在_p 门前_s 等_u 小_a 黑回_n 来_f
第四句:是有关司法领域文本分词
发现HanLP的分词粒度比较大,fool分词粒度较小,导致fool分词在上有较大的误差。在人名识别上没有太大的差异,在组织机构名上分词,分词的颗粒度有一些差异,Hanlp在机构名的分词上略胜一筹。
六种分词器使用建议:
对命名实体识别要求较高的可以选择HanLP,根据说明其训练的语料比较多,载入了很多实体库,通过测试在实体边界的识别上有一定的优势。
中科院的分词,是学术界比较权威的,对比来看哈工大的分词器也具有比较高的优势。同时这两款分词器的安装虽然不难,但比较jieba的安装显得繁琐一点,代码迁移性会相对弱一点。哈工大分词器pyltp安装配置模型教程
结巴因为其安装简单,有三种模式和其他功能,支持语言广泛,流行度比较高,且在操作文件上有比较好的方法好用python -m jieba news.txt > cut_result.txt
对于分词器的其他功能就可以在文章开头的链接查看,比如说哈工大的pyltp在命名实体识别方面,可以输出标注的词向量,是非常方便基础研究的命名实体的标注工作。

精简文本 效果对比


https://blog.csdn.net/shuihupo/article/details/81540433