深度学习--手写数字识别<一>
手写字符识别数据集THE MNIST DATABASE of handwritten digits:http://yann.lecun.com/exdb/mnist/
其中训练集60000例,测试集10000例.
加载数据
1. 读取数据
#!/usr/bin/python
# coding:utf-8
import numpy as np
import cPickle
import gzip
def load_data():
# 读取压缩文件, 返回一个描述符f
f = gzip.open('../data/mnist.pkl.gz', 'rb')
# 从文件中读取数据
training_data, validation_data, test_data = cPickle.load(f)
f.close()
return (training_data, validation_data, test_data)
if __name__ == '__main__':
training_set, validation_set, test_set = load_data()
print test_set
打印结果:
可以看到数据已经被读取
(array([[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
...,
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.]], dtype=float32), array([7, 2, 1, ..., 4, 5, 6]))2 显示
import matplotlib
import matplotlib.pyplot as plt
def ShowImage():
# 加载数据
training_set, validation_set, test_set = load_data()
# 获取validation_set中的data数据(validation_set中存放两个array,第0个为图像数据,第1个为labels)
# 此时flattened_images大小为(10000*784)
flattened_images = validation_set[0]
# 将validation_set中每行数据(即每个图像数据)转换为(28*28)的二维NumPy数组
images = [np.reshape(f, (-1, 28)) for f in flattened_images]
# 显示数字图像
for i in range(16):
ax = plt.subplot(4, 4, i+1)
ax.matshow(images[i], cmap = matplotlib.cm.binary)
plt.xticks(np.array([]))
plt.yticks(np.array([]))
plt.show()
if __name__ == '__main__':
# # 显示图像
ShowImage()
显示结果:
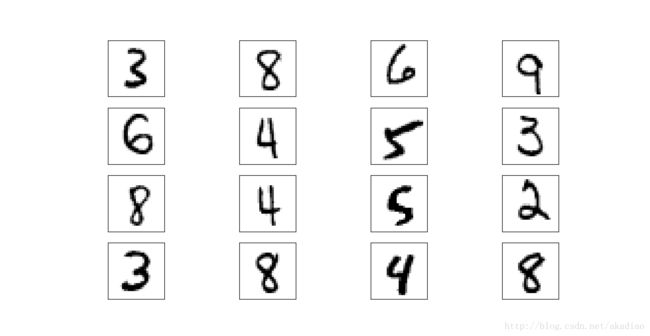
随机梯度下降法SGD:
传统的批量梯度下降法(BGD-Batch Gradient Descent)更新每一个参数时都使用所有的样本进行更新,这样随着样本数量的增大算法会变得非常缓慢.
随机梯度下降法(SGD-Stochastic Gradient Descent)通过每次从所有训练实例中取一个小的样本(sample中包含一个或多个实例)mini-batch来估计梯度向量gradient vector,进行迭代更新.
优点:训练速度快;
缺点:准确度下降,不易于并行实现;
梯度下降法中对weights和biases的更新方式为:
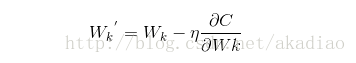
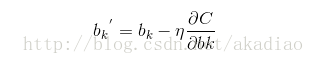
由于SGD中采用的是通过训练集中的一个采样(mini_batch)对weights和biases进行更新,因此在梯度向量上应该除以采样样本的大小m:
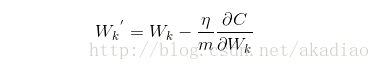
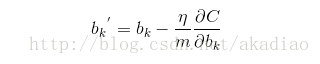
实现:函数update_mini_batch()中,通过传入的mini_batch(即对原训练集的一个抽样)中的所有训练实例,对整个神经网络的wights和biases进行更新.然后重新选择一个mini_batch来训练.
向量化:
将训练集/验证集/测试集中的labels由[5 0 4 …, 8 4 8]转化为向量形式,即label:0对应向量为
[[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]]
label:1对应向量为
[[ 0.]
[ 1.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]]
label:2对应向量为
[[ 0.]
[ 0.]
[ 1.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]]
依次类推;
实现:通过函数vectorized_result(j)实现,即传入一个0-9的整数j,返回一个长度为10的向量,第j位为1,其余为0.
定义神经网络结构
# 定义神经网络结构
class Network(object):
def __init__(self, sizes):
# 获取神经网络的层数
self.num_layers = len(sizes)
# sizes即每层神经元的个数
self.sizes = sizes
# 赋随机值(服从高斯分布),对权重和偏向进行初始化
# bais从第2行开始
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]
# zip从传入的可循环的两组量中取出对应数据组成一个tuple
self.weights = [np.random.randn(y, x) for x, y in zip(sizes[:-1], sizes[1:])]
# print self.weights
# print self.biases
# 根据当前输入利用sigmoid函数来计算输出
def feedforward(self, a):
for b, w in zip(self.biases, self.weights):
a = sigmoid(np.dot(w, a) + b)
return a
# epochs训练多少轮, mini_batch_size抽取多少实例,eta学习率
def SGD(self, training_data, epochs, mini_batch_size, eta, test_data=None):
# 测试集的大小
if test_data:
n_test = len(test_data)
n = len(training_data)
# j代表第几轮
for j in xrange(epochs):
# 将training_data中的数据随机打乱
random.shuffle(training_data)
# mini_batchs每次抽取mini_batch_size大小的数据作为一小块
mini_batches = [training_data[k:k + mini_batch_size]
# 从0到n每次间隔mini_batch_size张图片
for k in xrange(0, n, mini_batch_size)]
# 对取出来的mini_batchs逐个进行更新,更新weights和biases
for mini_batch in mini_batches:
self.update_mini_batch(mini_batch, eta)
# 每一轮训练后进行评估
if test_data:
print "Epoch {0}: {1} / {2}".format(j, self.evaluate(test_data), n_test)
else:
print "Epoch {0} complete".format(j)
# eta:学习率 传入单个的mini_batch,根据其x.y值,对整个神经网络的wights和biases进行更新
def update_mini_batch(self, mini_batch, eta):
# 初始化
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
# 计算对应的偏导数
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb + dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw + dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
# 权重weights更新 W'k=Wk-(eta/m)&C/&Wk
self.weights = [w - (eta / len(mini_batch)) * nw
for w, nw in zip(self.weights, nabla_w)]
# 偏向biases更新 b'k=bk-(ets/m)&C/&bk
self.biases = [b - (eta / len(mini_batch)) * nb
for b, nb in zip(self.biases, nabla_b)]
# 计算对应的偏导数
def backprop(self, x, y):
# 返回一个元组(nabla_b,nabla_w)代表成本函数C_x的渐变。
# nabla_b和nabla_w是numpy数组np.array的逐层列表,类似于self.biases和self.weights.
# 分别生成与biases weights等大小的0矩阵
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# 激活项
activation = x
# 列表存储所有的激活,逐层
activations = [x]
# 列表存储所有中间向量z,逐层
zs = []
for b, w in zip(self.biases, self.weights):
# 计算中间变量 Z=W*X+b
z = np.dot(w, activation) + b
# 列表存储所有中间向量z
zs.append(z)
# 激活activation=sigmoid(W*X+b)
activation = sigmoid(z)
# 列表存储所有的激活
activations.append(activation)
# 反向更新
# ### 输出层
# 计算输出层error=Oj(1-Oj)(Tj-Oj);
# cost_derivative(activations[-1], y)即C对a的梯度:(Tj-Oj)
# sigmoid_prime(zs[-1])即:Oj(1-Oj)
delta = self.cost_derivative(activations[-1], y) * sigmoid_prime(zs[-1])
# 更新输出层的nabla_b,nabla_w
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
# ### 隐藏层
# l = 1表示神经元的最后一层,l = 2是第二层,依此类推.反向更新直到初始层
for l in xrange(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
# weights[-l + 1]即下一层的权重,
delta = np.dot(self.weights[-l + 1].transpose(), delta) * sp
# 输出C对w,b的偏导
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l - 1].transpose())
return (nabla_b, nabla_w)
def evaluate(self, test_data):
# 返回神经网络输出正确结果的测试输入的数量。 注意,神经网络的输出被假定为最终层中具有最高激活的神经元的指数。
test_results = [(np.argmax(self.feedforward(x)), y) for (x, y) in test_data]
return sum(int(x == y) for (x, y) in test_results)
def cost_derivative(self, output_activations, y):
# 返回输出激活的偏导数 partial C_x,partial a的向量。
return (output_activations - y)
# sigmoid函数
def sigmoid(z):
return 1.0 / (1.0 + np.exp(-z))
# sigmoid函数的导数
def sigmoid_prime(z):
return sigmoid(z) * (1 - sigmoid(z))
# 向量化
def vectorized_result(j):
e = np.zeros((10, 1))
e[j] = 1.0
return e
# 数据转换,将数据转换为长度为784的numpy.ndarray组成的list,将对应label向量化
def load_data_wrapper():
tr_d, va_d, te_d = load_data()
# # 数据转换
# tr_d是由50000个长度为784的numpy.ndarray组成的tuple
# 转换后的training_inputs是由50000个长度为784的numpy.ndarray组成的list
training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]
training_results = [vectorized_result(y) for y in tr_d[1]]
# 训练集 training_data
# zip()返回一个列表的元组,其中每个元组包含从每个参数序列的第i个元素。
training_data = zip(training_inputs, training_results)
validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]]
# 验证集 validation_data
validation_data = zip(validation_inputs, va_d[1])
test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]
# 测试集 test_data
test_data = zip(test_inputs, te_d[1])
return (training_data, validation_data, test_data)
if __name__ == '__main__':
training_data, valivation_data, test_data =load_data_wrapper()
# # 显示图像
# ShowImage()
net = Network([784, 30, 10])
# 训练集training_data,训练10轮,每次取样10个作为mini_batch,学习率为3
net.SGD(training_data, 10, 10, 3.0, test_data=test_data)
输出结果:
Epoch 0: 9106 / 10000
Epoch 1: 9220 / 10000
Epoch 2: 9286 / 10000
Epoch 3: 9313 / 10000
Epoch 4: 9378 / 10000
Epoch 5: 9381 / 10000
Epoch 6: 9414 / 10000
Epoch 7: 9418 / 10000
Epoch 8: 9435 / 10000
Epoch 9: 9419 / 10000附:
1. BGD批量梯度下降算法/SGD随机梯度下降算法/MBGD小批量梯度下降算法 对比
2.神经网路算法Neural Network