TensorFlow学习--ResNet实现
github上用ResNet模型对CIFAR-10数据集进行分类,链接:CIFAR-10 ResNet model
CIFAR-10数据集,链接:The CIFAR-10 dataset
ResNet结构
从AlexNet之后神经网络有两个发展方向,一是调整网络结构,二是增加网络深度,如下所示:
LeNet→AlexNet→{NIN→InceptionV1→InceptionV2→InceptionV3VGG→MSRANet→ResNet→ResNetV2 L e N e t → A l e x N e t → { N I N → I n c e p t i o n V 1 → I n c e p t i o n V 2 → I n c e p t i o n V 3 V G G → M S R A N e t → R e s N e t → R e s N e t V 2
在加深网络深度方向,AlexNet使用了5层卷积,而VGG训练了19层的网络,一直到ResNet成功训练了152层深的网络.
ResNet允许原始输入信息直接传输到后面的层中,假定某段神经网络的输入是x,期望输出是H(x),若直接将输入x传到输出作为初始结果,则需要学习的目标为F(x)=H(x)-x.
ResNet引入残差学习单元,不再学习一个完整的输出H(x)而是输出与输入的的差别H(x)-x,即残差.
ResNet的残差学习单元:

可以看到ResNet利用旁路支线将输入直接接到后面的层,使后面的层可以直接学习残差.
ResNet的基础结构主要是两层残差学习单元和三层残差学习单元组成,如图
两层残差学习单元:
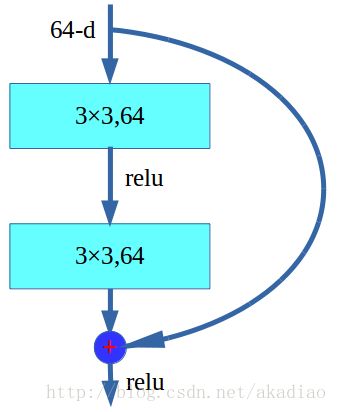
三层残差学习单元:
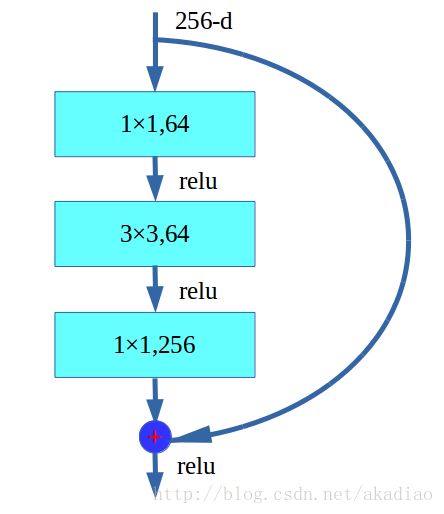
组成ResNet的基本结构.
VGG-19直连的34层网络与ResNet的34层网络的结构对比,如图:

ResNet全部参数梯度耗时
#!/usr/bin/python
# coding:utf-8
import collections
import tensorflow as tf
import time
import math
from datetime import datetime
slim = tf.contrib.slim
class Block(collections.namedtuple('Bolck', ['scope', 'unit_fn', 'args'])):
'A named tuple describing a ResNet block.'
def subsample(inputs, factor, scope = None):
if factor == 1:
return inputs
else:
return slim.max_pool2d(inputs, [1, 1], stride = factor, scope = scope)
def conv2d_same(inputs, num_outputs, kernel_size, stride, scope = None):
if stride == 1:
return slim.conv2d(inputs, num_outputs, kernel_size, stride = 1, padding = 'SAME', scope = scope)
else:
pad_total = kernel_size - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg
inputs = tf.pad(inputs, [[0, 0], [pad_beg, pad_end], [pad_beg, pad_end], [0, 0]])
return slim.conv2d(inputs, num_outputs, kernel_size, stride = stride, padding = 'VALID', scope = scope)
@slim.add_arg_scope
def stack_blocks_dense(net, blocks, outputs_collections = None):
for block in blocks:
with tf.variable_scope(block.scope, 'block', [net]) as sc:
for i, unit in enumerate(block.args):
with tf.variable_scope('unit_%d' %(i + 1), values = [net]):
unit_depth, unit_depth_bottleneck, unit_stride = unit
net = block.unit_fn(net, depth = unit_depth,
depth_bottleneck=unit_depth_bottleneck,
stride = unit_stride)
net = slim.utils.collect_named_outputs(outputs_collections, sc.name, net)
return net
def resnet_arg_scope(is_training = True,
weight_decay = 0.0001,
batch_norm_decay = 0.997,
batch_norm_epsilon = 1e-5,
batch_norm_scale = True):
batch_norm_params = {
'is_training': is_training,
'decay': batch_norm_decay,
'epsilon': batch_norm_epsilon,
'scale': batch_norm_scale,
'updates_collections': tf.GraphKeys.UPDATE_OPS,
}
with slim.arg_scope(
[slim.conv2d],
weights_regularizer = slim.l2_regularizer(weight_decay),
weights_initializer = slim.variance_scaling_initializer(),
activation_fn = tf.nn.relu,
normalizer_fn = slim.batch_norm,
normalizer_params = batch_norm_params):
with slim.arg_scope([slim.batch_norm], **batch_norm_params):
with slim.arg_scope([slim.max_pool2d], padding = 'SAME') as arg_sc:
return arg_sc
@slim.add_arg_scope
def bottleneck(inputs, depth, depth_bottleneck, stride, outputs_collections = None, scope = None):
with tf.variable_scope(scope, 'bottleneck_v2', [inputs]) as sc:
depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank = 4)
preact = slim.batch_norm(inputs, activation_fn = tf.nn.relu, scope = 'preact')
if depth == depth_in:
shortcut = subsample(inputs, stride, 'shortcut')
else:
shortcut = slim.conv2d(preact, depth, [1, 1], stride = stride, normalizer_fn = None, activation_fn = None, scope = 'shortcut')
residual = slim.conv2d(preact, depth_bottleneck, [1, 1], stride = 1, scope = 'conv1')
residual = conv2d_same(residual, depth_bottleneck, 3, stride, scope = 'conv2')
residual = slim.conv2d(residual, depth, [1, 1], stride = 1, normalizer_fn = None, activation_fn = None, scope = 'conv3')
output = shortcut + residual
return slim.utils.collect_named_outputs(outputs_collections, sc.name, output)
def resnet_v2(inputs, blocks, num_classes = None, global_pool = True, include_root_block = True, reuse = None, scope = None):
with tf.variable_scope(scope, 'resnet_v2', [inputs], reuse = reuse) as sc:
end_points_collection = sc.original_name_scope + '_end_points'
with slim.arg_scope([slim.conv2d, bottleneck, stack_blocks_dense], outputs_collections = end_points_collection):
net = inputs
if include_root_block:
with slim.arg_scope([slim.conv2d], activation_fn = None, normalizer_fn = None):
net = conv2d_same(net, 64, 7, stride = 2, scope = 'conv1')
net = slim.max_pool2d(net, [3, 3], stride = 2, scope = 'pool1')
net = stack_blocks_dense(net, blocks)
net = slim.batch_norm(net, activation_fn = tf.nn.relu, scope = 'postnorm')
if global_pool:
net = tf.reduce_mean(net, [1, 2], name = 'pool5', keep_dims = True)
if num_classes is not None:
net = slim.conv2d(net, num_classes, [1, 1], activation_fn = None, normalizer_fn = None, scope = 'logits')
end_points = slim.utils.convert_collection_to_dict(end_points_collection)
if num_classes is not None:
end_points['predictions'] = slim.softmax(net, scope = 'predictions')
return net, end_points
def resnet_v2_50(inputs, num_classes = None, global_pool = True, reuse = None, scope = 'resnet_v2_50'):
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 3 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 5 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(2048, 1024, 1)] * 3)]
return resnet_v2(inputs, blocks, num_classes, global_pool, include_root_block = True, reuse = reuse, scope = scope)
def resnet_v2_101(inputs, num_classes = None, global_pool = True, reuse = None, scope = 'resnet_v2_101'):
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 3 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 22 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(2048, 512, 1)] * 3)]
return resnet_v2(inputs, blocks, num_classes, global_pool, include_root_block = True, reuse = reuse, scope = scope)
def resnet_v2_152(inputs, num_classes = None, global_pool = True, reuse = None, scope = 'resnet_v2_152'):
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 7 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 35 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(2048, 512, 1)] * 3)]
return resnet_v2(inputs, blocks, num_classes, global_pool, include_root_block = True, reuse = reuse, scope = scope)
def resnet_v2_200(inputs, num_classes = None, global_pool = True, reuse = None, scope = 'resnet_v2_200'):
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 23 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 35 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(2048, 512, 1)] * 3)]
return resnet_v2(inputs, blocks, num_classes, global_pool, include_root_block = True, reuse = reuse, scope = scope)
def time_tensorflow_run(session, target, info_string):
num_batches = 100
num_steps_burn_in = 10
total_duration = 0.0
total_duration_squared = 0.0
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target)
# 持续时间
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print '%s: step %d, duration = %.3f' % (datetime.now().strftime('%X'), i - num_steps_burn_in, duration)
# 总持续时间
total_duration += duration
# 总持续时间平方和
total_duration_squared += duration * duration
# 计算每轮迭代的平均耗时mn,和标准差sd
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn * mn
sd = math.sqrt(vr)
# 打印出每轮迭代耗时
print '%s: %s across %d steps, %.3f +/- %.3f sec /batch' % (datetime.now().strftime('%X'), info_string, num_batches, mn, sd)
batch_size = 32
height, width = 224, 224
inputs = tf.random_uniform((batch_size, height, width, 3))
with slim.arg_scope(resnet_arg_scope(is_training = False)):
net, end_points = resnet_v2_152(inputs, 1000)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
num_batches = 100
time_tensorflow_run(sess, net, "Forward")输出:
16:09:27: step 0, duration = 35.510
16:19:18: step 10, duration = 58.923
16:29:05: step 20, duration = 59.376
16:39:21: step 30, duration = 56.854
16:48:58: step 40, duration = 57.112
16:58:52: step 50, duration = 59.859
17:09:47: step 60, duration = 67.583
17:19:43: step 70, duration = 55.242
17:26:09: step 80, duration = 31.743
17:34:08: step 90, duration = 55.089
17:39:01: Forward across 100 steps, 54.089 +/- 11.882 sec / batch相关链接
ResNetDeep Residual Learning for Image Recognition
The Power of Depth for Feedforward Neural Networks
Highway Network针对极深神经网络难以训练的问题:Highway and Residual Networks learn Unrolled Iterative Estimation