HBase学习笔记 (贰)- HBase原理与实战 **
文章目录
- HBase写流程
- 存储结构介绍
- 写入流程
- 简要概括
- HBase读流程
- 简要概括
- HBase模块协作
- Hbase启动
- regionserver失效
- HMaster失效
- Shell命令实战
- Hbase Shell命令
- HBase Java API
- HBase数据库操作类
- Hbase数据过滤
- Java Api实现HBase操作类
- 开发HBase数据库操作类
- 通过多种过滤器过滤数据,实现HBase高级查询
- 自定义过滤器
HBase写流程
存储结构介绍
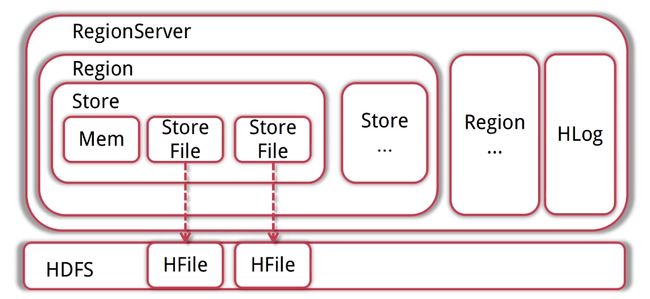
- RegionServer管理着多个region;每个RegionServer都有对应的HLog实例
- region是Hbase存储的单元,数据都存在region中,需要注意的是每一个region只存储一个column family的数据而且只是这个列族的一部分;当region达到一定的大小之后会根据rowkey的排序划分为多个region;每个region里面包含多个store对象;每个store对象里面包含一个memstore和一个或多个storefile
- memstore是数据在内存中的实体;并且一般是有序的;当有数据写入的时候会先写入到memstore;当memstore大小达到上线之后store会flish(创建)
storefile(hfile的一层封装)文件;最终写入到hdfs中。 - Hlog保证了内存中的数据不会丢失;WAL的一种实现预写日志;regionserver会将更新操作记录到memstore然后记录到hlog中;只有当hlog更新完成之后这条记录才是真正成功写入。(一般的WAL是先写入日志再写入内存;hbase是先写入内存再写入日志的)
写入流程

- client客户端会首先访问zookeeper;从中获取表的相关信息和表的region的相关信息;根据要插入的rowkey获取指定的regionserver的信息;如果是批量提交会把rowkey根据hregion location进行分组;当我们得到了要访问的regionserver之后;
- client会向regionserver发出写请求;将数据发送给这个regionserver;这个regionserver收请求之后;首先会进行各种检查操作比如看一下这个regionserver是不是只读状态;memstore是否超过了broking memstore size的大小;之后进行数据写入;将数据同时写入memstore和hlog;这俩者都写入成功后才算完结。这里面比较复杂;写入memstore和hlog是事务性操作;需要获取相关的锁;要么全部成功要么全失败。
- 当memstore大小达到阈值之后store会flish成storefile文件;当storefile文件达到一定数量后会促发combine合并机制;将多个storefile文件合并成一个大的storefile文件;如果单个stroefile文件达到了一定的阈值会触发split机制;将regionserver一分为二;之后hmaster给两个region分配相应的regionserver进行管理;从而分担压力。
简要概括
- Client会先访问zookeeper, 得到对应的regionserver地址
- Client对regionserver发起写请求, Regionserver接受数据写入内存
- 当memstore的大小达到一定的值后, Flush到storefile并存储到Hdfs
HBase读流程
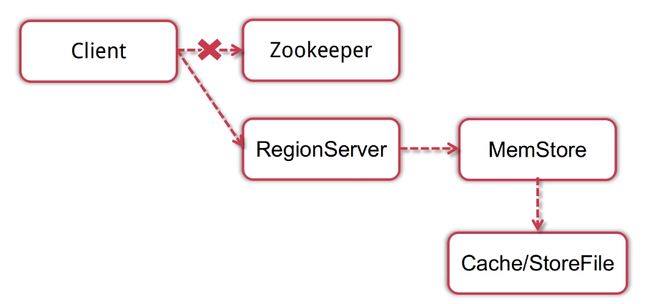
- client读取数据首先链接zookeeper,通过访问meta 表和regisonserver的节点信息;将meta 表缓存到本地;通过缓存的meta 表获取要访问的表所对应的regionserver的信息,让后向对应的regionserver发起读请求;
- regionsserver收到读请求后做一些复杂的操作见下面红字
- meta表就相当于一个目录;可以快速定位到数据的实际位置
简要概括
- Client会先访问zookeeper, 得到对应的regionserver地址
- Client对regionserver发起读请求
- 当regionserver收到client的读请求后, 先扫描自己的memstore, 再扫描
blockcache (加速读内容缓存区) 如果还没找到则 Storefile中读取数据, 然后将数据返回给Client
HBase模块协作
◆Hbase启动时发生了什么?
◆当regionserver失效后会发生什么?
◆当hmaster失效后会发生什么?
Hbase启动
- HMaster启动、注册到Zookeeper,等待RegionServer汇报;
- RegionServer注册到Zookeeper,并向HMaster汇报
- HMaster对各个Regionserver (包括失效的) 的数据进行整理, 分配region和meta信息。
注意:集群中在注册Zookeeper之前首先会将自己注册到backupmaster节点;这里是因为在集群中有多个master;在不确定谁是acive之前都会先注册到backupmaster节点中;当某个节点成为activemaster就会删除自身的在backupmaster的信息;才会实例化相关的类比如masterServertive,serverManager,tableStaticManager
Hmaster将meta表交给zookeeper就没事了;backupmaster节点里的unactive的master会从action master处定期更新自己的meta表保证最新。
regionserver失效
- Hmaster将失效regionserver上的region分配到其他节点
- Hmaster更新hbase: Meta表以保证数据正常访问:
HMaster失效
- (集群中)处于backup状态的其他hmaster节点推选出一个转为active状态
- (非集群)数据能正常读写, 但是不能创建删除表, 也不能更改表结构
Shell命令实战
Hbase Shell命令
◆ HBase shell基础命令: status, List, create Table等
◆ HBase shell数据模型操作命令: Put, get, delete, Scan等

详细命令
# HBase shell中的帮助命令非常强大,使用help获得全部命令的列表,使用help ‘command_name’获得某一个命令的详细信息
help 'status'
# 查询服务器状态
status
# 查看所有表
list
# 创建一个表
create 'FileTable','fileInfo','saveInfo'
# 获得表的描述
describe 'FileTable'
# 添加一个列族
alter 'FileTable', 'cf'
# 删除一个列族
alter 'FileTable', {NAME => 'cf', METHOD => 'delete'}
# 插入数据
put 'FileTable', 'rowkey1','fileInfo:name','file1.txt'
put 'FileTable', 'rowkey1','fileInfo:type','txt'
put 'FileTable', 'rowkey1','fileInfo:size','1024'
put 'FileTable', 'rowkey1','saveInfo:path','/home'
put 'FileTable', 'rowkey1','saveInfo:creator','tom'
put 'FileTable', 'rowkey2','fileInfo:name','file2.jpg'
put 'FileTable', 'rowkey2','fileInfo:type','jpg'
put 'FileTable', 'rowkey2','fileInfo:size','2048'
put 'FileTable', 'rowkey2','saveInfo:path','/home/pic'
put 'FileTable', 'rowkey2','saveInfo:creator','jerry'
# 查询表中有多少行
count 'FileTable'
# 获取一个rowkey的所有数据
get 'FileTable', 'rowkey1'
# 获得一个id,一个列簇(一个列)中的所有数据
get 'FileTable', 'rowkey1', 'fileInfo'
# 查询整表数据
scan 'FileTable'
# 扫描整个列簇
scan 'FileTable', {COLUMN=>'fileInfo'}
# 指定扫描其中的某个列
scan 'FileTable', {COLUMNS=> 'fileInfo:name'}
# 除了列(COLUMNS)修饰词外,HBase还支持Limit(限制查询结果行数),STARTROW(ROWKEY起始行。会先根据这个key定位到region,再向后扫描)、STOPROW(结束行)、TIMERANGE(限定时间戳范围)、VERSIONS(版本数)、和FILTER(按条件过滤行)等。比如我们从RowKey1这个rowkey开始,找下一个行的最新版本
scan 'FileTable', { STARTROW => 'rowkey1', LIMIT=>1, VERSIONS=>1}
# Filter是一个非常强大的修饰词,可以设定一系列条件来进行过滤。比如我们要限制名称为file1.txt
scan 'FileTable', FILTER=>"ValueFilter(=,'name:file1.txt’)"
# FILTER中支持多个过滤条件通过括号、AND和OR的条件组合
scan 'FileTable', FILTER=>"ColumnPrefixFilter('typ') AND ValueFilter ValueFilter(=,'substring:10')"
# 通过delete命令,我们可以删除某个字段,接下来的get就无结果
delete 'FileTable','rowkey1','fileInfo:size'
get 'FileTable','rowkey1','fileInfo:size'
# 删除整行的值
deleteall 'FileTable','rowkey1'
get 'FileTable',’rowkey1'
# 通过enable和disable来启用/禁用这个表,相应的可以通过is_enabled和is_disabled来检查表是否被禁用
is_enabled 'FileTable'
is_disabled 'FileTable'
# 使用exists来检查表是否存在
exists 'FileTable'
# 删除表需要先将表disable
disable 'FileTable'
drop 'FileTable'
HBase Java API
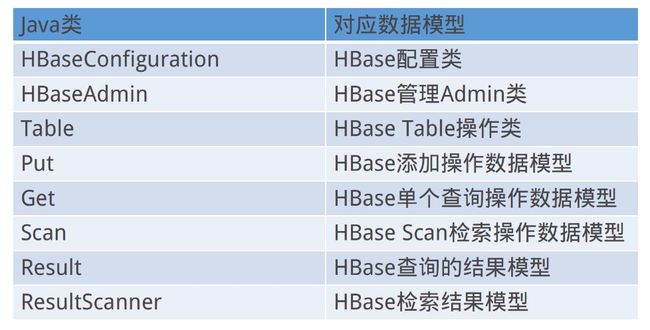
HBase数据库操作类
- 开发hbase数据库操作类
- 获取数据库链接;其代码在hbase-example\hbase-api-test\HBaseConn中
- 增删改查模块编写
- 增删改查方法测试
Hbase数据过滤
过滤器能干什么?
- Hbase为筛选数据提供了一组过滤器, 通过过滤器可以在hbase中的数
据的多个维度 (行kitakatta, 列bu, 数据版本) 上进行对数据的筛选操作 - 通常来说, 通过行键 、 列来筛选数据的应用场景较多
- 基于行的过滤器
- Prefixfilter: 行的前缀匹配.
- Pagefilter: 基于行的分页
- 基于列的过滤器
- Columnprefixfilter: 列前缀匹配
- Firstkeyonlyfilter: 只返回每一行的第一列
- 基于单元值的过滤器
- Keyonlyfilter: 返回的数据不包括单元值, 只包含行键与列
- Timestampsfilter: 根据数据的时间戳版本进行过滤
- 基于列和单元值的过滤器.
- Singlecolumnvaluefilter: 对该列的单元值进行比较过滤
- Singlecolumnvalueexcludefilter: 对该列的单元值进行比较过滤
按实现划分可划分为:
比较过滤器
- 比较过滤器通常需要一个比较运算符以及一个比较器来实现过滤
- RowFilter, Familyfilter, Qualifierfilter, Valuefilter
常用过滤器

Java Api实现HBase操作类
开发HBase数据库操作类
package com.kun.hbase;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Table;
/**
*单例类
*/
public class HBaseConn {
private static final HBaseConn INSTANCE = new HBaseConn();
private static Configuration configuration;
private static Connection connection;
private HBaseConn() {
try {
if (configuration == null) {
configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "localhost:2181");
}
} catch (Exception e) {
e.printStackTrace();
}
}
private Connection getConnection() {
if (connection == null || connection.isClosed()) {
try {
connection = ConnectionFactory.createConnection(configuration);
} catch (Exception e) {
e.printStackTrace();
}
}
return connection;
}
/**
* 获取hbase链接
* @return
*/
public static Connection getHBaseConn() {
return INSTANCE.getConnection();
}
/**
* 获取表实例
* @param tableName
* @return
* @throws IOException
*/
public static Table getTable(String tableName) throws IOException {
return INSTANCE.getConnection().getTable(TableName.valueOf(tableName));
}
/**
* 关闭链接
*/
public static void closeConn() {
if (connection != null) {
try {
connection.close();
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
}
}
package com.kun.hbase;
import java.io.IOException;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.Table;
import org.junit.Test;
import com.imooc.bigdata.hbase.api.HBaseConn;
/**
* 测试HbaseConn类
*/
public class HBaseConnTest {
/**
* 测试hbase数据库链接
*/
@Test
public void getConnTest() {
Connection conn = HBaseConn.getHBaseConn();
System.out.println(conn.isClosed());
HBaseConn.closeConn();
System.out.println(conn.isClosed());
}
/**
* 测试获取一个table
*/
@Test
public void getTableTest() {
try {
Table table = HBaseConn.getTable("US_POPULATION");
System.out.println(table.getName().getNameAsString());
table.close();
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
}
增删查操作
package com.kun.hbase;
import java.io.IOException;
import java.util.Arrays;
import java.util.List;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.util.Bytes;
/**
*代码中都有Bytes.toBytes的意思是HBase都是以byte来存储的和关系数据库不一样;
* 从而导致了hbase没有更新操作;跟新操作是删除后重新插入。
*/
public class HBaseUtil {
/**
* 创建HBase表.
*
* @param tableName 表名
* @param cfs 列族的数组
* @return 是否创建成功
*/
public static boolean createTable(String tableName, String[] cfs) {
try (HBaseAdmin admin = (HBaseAdmin) HBaseConn.getHBaseConn().getAdmin()) {
if (admin.tableExists(tableName)) {
return false;
}
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf(tableName));
Arrays.stream(cfs).forEach(cf -> {
HColumnDescriptor columnDescriptor = new HColumnDescriptor(cf);
columnDescriptor.setMaxVersions(1);
tableDescriptor.addFamily(columnDescriptor);
});
admin.createTable(tableDescriptor);
} catch (Exception e) {
e.printStackTrace();
}
return true;
}
/**
* 删除hbase表.
*
* @param tableName 表名
* @return 是否删除成功
*/
public static boolean deleteTable(String tableName) {
try (HBaseAdmin admin = (HBaseAdmin) HBaseConn.getHBaseConn().getAdmin()) {
admin.disableTable(tableName);
admin.deleteTable(tableName);
} catch (Exception e) {
e.printStackTrace();
}
return true;
}
/**
* hbase插入一条数据.
*
* @param tableName 表名
* @param rowKey 唯一标识
* @param cfName 列族名
* @param qualifier 列标识
* @param data 数据
* @return 是否插入成功
*/
public static boolean putRow(String tableName, String rowKey, String cfName, String qualifier,
String data) {
try (Table table = HBaseConn.getTable(tableName)) {
Put put = new Put(Bytes.toBytes(rowKey));
put.addColumn(Bytes.toBytes(cfName), Bytes.toBytes(qualifier), Bytes.toBytes(data));
table.put(put);
} catch (IOException ioe) {
ioe.printStackTrace();
}
return true;
}
/**
* 批量插入数据
* @param tableName
* @param puts
* @return
*/
public static boolean putRows(String tableName, List<Put> puts) {
try (Table table = HBaseConn.getTable(tableName)) {
table.put(puts);
} catch (IOException ioe) {
ioe.printStackTrace();
}
return true;
}
/**
* 获取单条数据.
*
* @param tableName 表名
* @param rowKey 唯一标识
* @return 查询结果
*/
public static Result getRow(String tableName, String rowKey) {
try (Table table = HBaseConn.getTable(tableName)) {
Get get = new Get(Bytes.toBytes(rowKey));
return table.get(get);
} catch (IOException ioe) {
ioe.printStackTrace();
}
return null;
}
/**
* 根据过滤器获取单条数据
* @param tableName
* @param rowKey
* @param filterList
* @return
*/
public static Result getRow(String tableName, String rowKey, FilterList filterList) {
try (Table table = HBaseConn.getTable(tableName)) {
Get get = new Get(Bytes.toBytes(rowKey));
get.setFilter(filterList);
return table.get(get);
} catch (IOException ioe) {
ioe.printStackTrace();
}
return null;
}
/**
* 检索数据
* @param tableName
* @return
*/
public static ResultScanner getScanner(String tableName) {
try (Table table = HBaseConn.getTable(tableName)) {
Scan scan = new Scan();
scan.setCaching(1000);
return table.getScanner(scan);
} catch (IOException ioe) {
ioe.printStackTrace();
}
return null;
}
/**
* 批量【某一区间内】检索数据.
*
* @param tableName 表名
* @param startRowKey 起始RowKey
* @param endRowKey 终止RowKey
* @return ResultScanner实例
*/
public static ResultScanner getScanner(String tableName, String startRowKey, String endRowKey) {
try (Table table = HBaseConn.getTable(tableName)) {
Scan scan = new Scan();
scan.setStartRow(Bytes.toBytes(startRowKey));
scan.setStopRow(Bytes.toBytes(endRowKey));
scan.setCaching(1000);
return table.getScanner(scan);
} catch (IOException ioe) {
ioe.printStackTrace();
}
return null;
}
/**
* 有过滤器的批量【某一区间内】检索数据.
* @param tableName
* @param startRowKey
* @param endRowKey
* @param filterList
* @return
*/
public static ResultScanner getScanner(String tableName, String startRowKey, String endRowKey,
FilterList filterList) {
try (Table table = HBaseConn.getTable(tableName)) {
Scan scan = new Scan();
scan.setStartRow(Bytes.toBytes(startRowKey));
scan.setStopRow(Bytes.toBytes(endRowKey));
scan.setFilter(filterList);
scan.setCaching(1000);
return table.getScanner(scan);
} catch (IOException ioe) {
ioe.printStackTrace();
}
return null;
}
/**
* HBase删除一行记录.
*
* @param tableName 表名
* @param rowKey 唯一标识
* @return 是否删除成功
*/
public static boolean deleteRow(String tableName, String rowKey) {
try (Table table = HBaseConn.getTable(tableName)) {
Delete delete = new Delete(Bytes.toBytes(rowKey));
table.delete(delete);
} catch (IOException ioe) {
ioe.printStackTrace();
}
return true;
}
/**
* 删除某一列的列族
* @param tableName
* @param cfName
* @return
*/
public static boolean deleteColumnFamily(String tableName, String cfName) {
try (HBaseAdmin admin = (HBaseAdmin) HBaseConn.getHBaseConn().getAdmin()) {
admin.deleteColumn(tableName, cfName);
} catch (Exception e) {
e.printStackTrace();
}
return true;
}
/**
* 删除某一列的列标识【qualifier】
* @param tableName
* @param rowKey
* @param cfName
* @param qualifier
* @return
*/
public static boolean deleteQualifier(String tableName, String rowKey, String cfName,
String qualifier) {
try (Table table = HBaseConn.getTable(tableName)) {
Delete delete = new Delete(Bytes.toBytes(rowKey));
delete.addColumn(Bytes.toBytes(cfName), Bytes.toBytes(qualifier));
table.delete(delete);
} catch (IOException ioe) {
ioe.printStackTrace();
}
return true;
}
}
通过多种过滤器过滤数据,实现HBase高级查询
通过多种过滤器过滤数据, 实现HBase高级查询
package com.kun.hbase;
import java.util.Arrays;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import org.apache.hadoop.hbase.filter.ColumnPrefixFilter;
import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.FilterList.Operator;
import org.apache.hadoop.hbase.filter.KeyOnlyFilter;
import org.apache.hadoop.hbase.filter.PrefixFilter;
import org.apache.hadoop.hbase.filter.RowFilter;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.Test;
public class HBaseFilterTest {
@Test
public void createTable() {
HBaseUtil.createTable("FileTable", new String[]{"fileInfo", "saveInfo"});
}
@Test
public void addFileDetails() {
HBaseUtil.putRow("FileTable", "rowkey1", "fileInfo", "name", "file1.txt");
HBaseUtil.putRow("FileTable", "rowkey1", "fileInfo", "type", "txt");
HBaseUtil.putRow("FileTable", "rowkey1", "fileInfo", "size", "1024");
HBaseUtil.putRow("FileTable", "rowkey1", "saveInfo", "creator", "jixin");
HBaseUtil.putRow("FileTable", "rowkey2", "fileInfo", "name", "file2.jpg");
HBaseUtil.putRow("FileTable", "rowkey2", "fileInfo", "type", "jpg");
HBaseUtil.putRow("FileTable", "rowkey2", "fileInfo", "size", "1024");
HBaseUtil.putRow("FileTable", "rowkey2", "saveInfo", "creator", "jixin");
HBaseUtil.putRow("FileTable", "rowkey3", "fileInfo", "name", "file3.jpg");
HBaseUtil.putRow("FileTable", "rowkey3", "fileInfo", "type", "jpg");
HBaseUtil.putRow("FileTable", "rowkey3", "fileInfo", "size", "1024");
HBaseUtil.putRow("FileTable", "rowkey3", "saveInfo", "creator", "jixin");
}
//
@Test
public void rowFilterTest() {
Filter filter = new RowFilter(CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("rowkey1")));
FilterList filterList = new FilterList(Operator.MUST_PASS_ONE, Arrays.asList(filter));
ResultScanner scanner = HBaseUtil
.getScanner("FileTable", "rowkey1", "rowkey3", filterList);
if (scanner != null) {
scanner.forEach(result -> {
System.out.println("rowkey=" + Bytes.toString(result.getRow()));
System.out.println("fileName=" + Bytes
.toString(result.getValue(Bytes.toBytes("fileInfo"), Bytes.toBytes("name"))));
});
scanner.close();
}
}
@Test
public void prefixFilterTest() {
Filter filter = new PrefixFilter(Bytes.toBytes("rowkey2"));
FilterList filterList = new FilterList(Operator.MUST_PASS_ALL, Arrays.asList(filter));
ResultScanner scanner = HBaseUtil
.getScanner("FileTable", "rowkey1", "rowkey3", filterList);
if (scanner != null) {
scanner.forEach(result -> {
System.out.println("rowkey=" + Bytes.toString(result.getRow()));
System.out.println("fileName=" + Bytes
.toString(result.getValue(Bytes.toBytes("fileInfo"), Bytes.toBytes("name"))));
});
scanner.close();
}
}
@Test
public void keyOnlyFilterTest() {
Filter filter = new KeyOnlyFilter(true);
FilterList filterList = new FilterList(Operator.MUST_PASS_ALL, Arrays.asList(filter));
ResultScanner scanner = HBaseUtil
.getScanner("FileTable", "rowkey1", "rowkey3", filterList);
if (scanner != null) {
scanner.forEach(result -> {
System.out.println("rowkey=" + Bytes.toString(result.getRow()));
System.out.println("fileName=" + Bytes
.toString(result.getValue(Bytes.toBytes("fileInfo"), Bytes.toBytes("name"))));
});
scanner.close();
}
}
@Test
public void columnPrefixFilterTest() {
Filter filter = new ColumnPrefixFilter(Bytes.toBytes("nam"));
FilterList filterList = new FilterList(Operator.MUST_PASS_ALL, Arrays.asList(filter));
ResultScanner scanner = HBaseUtil
.getScanner("FileTable", "rowkey1", "rowkey3", filterList);
if (scanner != null) {
scanner.forEach(result -> {
System.out.println("rowkey=" + Bytes.toString(result.getRow()));
System.out.println("fileName=" + Bytes
.toString(result.getValue(Bytes.toBytes("fileInfo"), Bytes.toBytes("name"))));
System.out.println("fileType=" + Bytes
.toString(result.getValue(Bytes.toBytes("fileInfo"), Bytes.toBytes("type"))));
});
scanner.close();
}
}
}
自定义过滤器
◆ 你真的需要自定义过滤器吗? (一般不需要自定义)
◆ 如何实现自定义过滤器 (参考官网)