Sparksql实战 - 用户行为日志
文章目录
- 用户行为日志概述
- 数据处理流程
- 项目需求
- imooc网主站日志内容构成
- 数据清洗
- 数据清洗之第一步原始日志解析
- 数据清洗之二次清洗概述
- 数据清洗之日志解析
- 数据清洗之ip地址解析
- 数据清洗结果以及存储到目标地址
- 需求统计功能实现
- Spark on YARN基础
- 数据清洗作业运行到YARN上
- 统计作业运行在YARN上
- 性能优化
- 性能优化之存储格式的选择
- 性能调优之压缩格式的选择
- 性能优化之代码优化
- 性能调优之参数优化
- 功能实现之数据可视化展示概述
- ECharts饼图静态数据展示
- ECharts饼图动态展示之一查询MySQL中的数据
- ECharts饼图动态展示之二前端开发
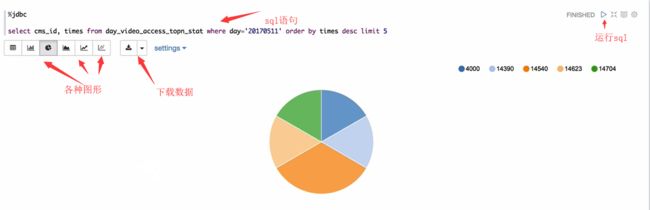
- 使用Zeppelin进行统计结果的展示
用户行为日志概述
用户行为日志:用户每次访问网站时所有的行为数据(访问、浏览、搜索、点击…)
用户行为轨迹、流量日志
典型的日志来源于Nginx和Ajax
日志数据内容:
1)访问的系统属性: 操作系统、浏览器等等
2)访问特征:点击的url、从哪个url跳转过来的(referer)、页面上的停留时间等
3)访问信息:session_id、访问ip(访问城市)等
比如
2013-05-19 13:00:00 http://www.taobao.com/17/?tracker_u=1624169&type=1 B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1 http://hao.360.cn/ 1.196.34.243
数据处理流程
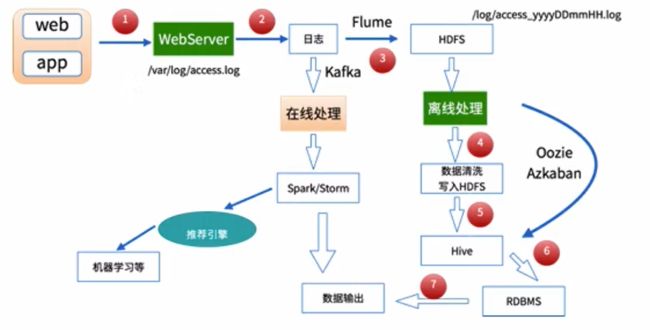
1)数据采集
Flume: web日志写入到HDFS
2)数据清洗
脏数据
Spark、Hive、MapReduce 或者是其他的一些分布式计算框架
清洗完之后的数据可以存放在HDFS(Hive/Spark SQL)
3)数据处理
按照我们的需要进行相应业务的统计和分析
Spark、Hive、MapReduce 或者是其他的一些分布式计算框架
4)处理结果入库
结果可以存放到RDBMS、NoSQL
5)数据的可视化
通过图形化展示的方式展现出来:饼图、柱状图、地图、折线图
ECharts、HUE、Zeppelin
项目需求
需求一:统计imooc主站最受欢迎的课程/手记的Top N访问次数
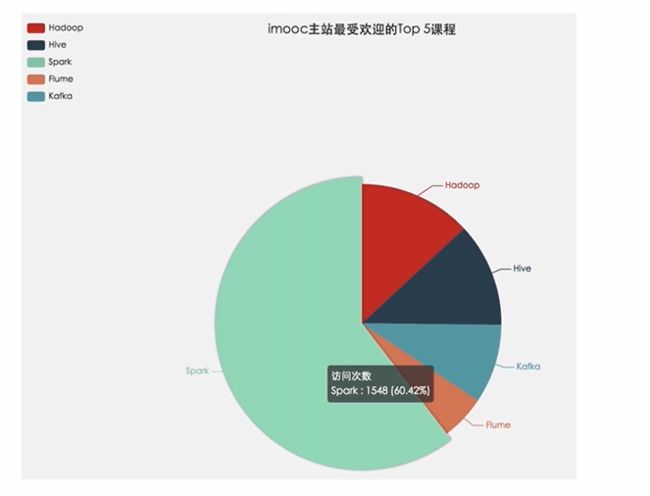
需求二:按地市统计imooc主站最受欢迎的Top N课程
- 根据IP地址提取出城市信息
- 窗口函数在Spark SQL中的使用
需求三:按流量统计imooc主站最受欢迎的TopN课程
imooc网主站日志内容构成
百条日志包下载链接
https://download.csdn.net/download/bingdianone/10800924
183.162.52.7 - - [10/Nov/2016:00:01:02 +0800] "POST /api3/getadv HTTP/1.1" 200 813 "www.imooc.com" "-" cid=0×tamp=1478707261865&uid=2871142&marking=androidbanner&secrect=a6e8e14701ffe9f6063934780d9e2e6d&token=f51e97d1cb1a9caac669ea8acc162b96 "mukewang/5.0.0 (Android 5.1.1; Xiaomi Redmi 3 Build/LMY47V),Network 2G/3G" "-" 10.100.134.244:80 200 0.027 0.027
106.39.41.166 - - [10/Nov/2016:00:01:02 +0800] "POST /course/ajaxmediauser/ HTTP/1.1" 200 54 "www.imooc.com" "http://www.imooc.com/video/8701" mid=8701&time=120.0010000000002&learn_time=16.1 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0" "-" 10.100.136.64:80 200 0.016 0.016
开发相关依赖
<properties>
<maven.compiler.source>1.5maven.compiler.source>
<maven.compiler.target>1.5maven.compiler.target>
<encoding>UTF-8encoding>
<scala.version>2.11.8scala.version>
<spark.version>2.1.0spark.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.spark-project.hivegroupId>
<artifactId>hive-jdbcartifactId>
<version>1.2.1.spark2version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.38version>
dependency>
<dependency>
<groupId>com.ggstargroupId>
<artifactId>ipdatabaseartifactId>
<version>1.0version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poi-ooxmlartifactId>
<version>3.14version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poiartifactId>
<version>3.14version>
dependency>
dependencies>
数据清洗
数据清洗之第一步原始日志解析
工具类
package com.imooc.log
import java.util.{Date, Locale}
import org.apache.commons.lang3.time.FastDateFormat
/**
* 日期时间解析工具类:
* 注意:SimpleDateFormat是线程不安全
*/
object DateUtils {
//输入文件日期时间格式
//10/Nov/2016:00:01:02 +0800
val YYYYMMDDHHMM_TIME_FORMAT = FastDateFormat.getInstance("dd/MMM/yyyy:HH:mm:ss Z", Locale.ENGLISH)
//目标日期格式
val TARGET_FORMAT = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss")
/**
* 获取时间:yyyy-MM-dd HH:mm:ss
*/
def parse(time: String) = {
TARGET_FORMAT.format(new Date(getTime(time)))
}
/**
* 获取输入日志时间:long类型
*
* time: [10/Nov/2016:00:01:02 +0800]
*/
def getTime(time: String) = {
try {
YYYYMMDDHHMM_TIME_FORMAT.parse(time.substring(time.indexOf("[") + 1,
time.lastIndexOf("]"))).getTime
} catch {
case e: Exception => {
0l
}
}
}
def main(args: Array[String]) {
println(parse("[10/Nov/2016:00:01:02 +0800]"))
}
}
package com.imooc.log
import org.apache.spark.sql.SparkSession
/**
* 第一步清洗:抽取出我们所需要的指定列的数据
*/
object SparkStatFormatJob {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("SparkStatFormatJob")
.master("local[2]").getOrCreate()
//读取源数据
val acccess = spark.sparkContext.textFile("file:///Users/rocky/data/imooc/10000_access.log")
//acccess.take(10).foreach(println)
acccess.map(line => {
val splits = line.split(" ")
val ip = splits(0)
/**
* 原始日志的第三个和第四个字段拼接起来就是完整的访问时间:
* [10/Nov/2016:00:01:02 +0800] ==> yyyy-MM-dd HH:mm:ss
*/
val time = splits(3) + " " + splits(4)
val url = splits(11).replaceAll("\"","")
val traffic = splits(9)
// (ip, DateUtils.parse(time), url, traffic)
DateUtils.parse(time) + "\t" + url + "\t" + traffic + "\t" + ip
}).saveAsTextFile("file:///Users/rocky/data/imooc/output/")
spark.stop()
}
}
清洗之后的样式
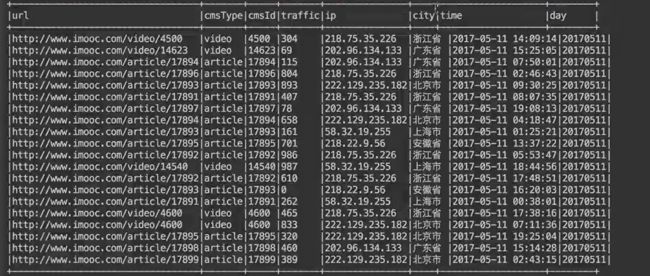
访问时间、访问URL、耗费的流量、访问IP地址信息
2017-05-11 00:38:01 http://www.imooc.com/article/17891 262 58.32.19.255
数据清洗之二次清洗概述
- 使用Spark SQL解析访问日志
- 解析出课程编号、类型
- 根据IP解析出城市信息
- 使用Spark SQL将访问时间按天进行分区输出
一般的日志处理方式,我们是需要进行分区的,
按照日志中的访问时间进行相应的分区,比如:d,h,m5(每5分钟一个分区);数据量越大建议分区越多
数据清洗之日志解析
输入:访问时间、访问URL、耗费的流量、访问IP地址信息
输出:URL、cmsType(video/article)、cmsId(编号)、流量、ip、城市信息、访问时间、天
数据清洗之ip地址解析
使用github上已有的开源项目
1)git clone https://github.com/wzhe06/ipdatabase.git
2)进入该项目目录下,编译下载的项目:mvn clean package -DskipTests
3)安装jar包到自己的maven仓库
mvn install:install-file -Dfile=/Users/rocky/source/ipdatabase/target/ipdatabase-1.0-SNAPSHOT.jar -DgroupId=com.ggstar -DartifactId=ipdatabase -Dversion=1.0 -Dpackaging=jar
记得加入poi包
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poi-ooxmlartifactId>
<version>3.14version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poiartifactId>
<version>3.14version>
dependency>
需要加入配置文件否则报错
java.io.FileNotFoundException:
file:/Users/rocky/maven_repos/com/ggstar/ipdatabase/1.0/ipdatabase-1.0.jar!/ipRegion.xlsx (No such file or directory)
解决:
将下列包导入到本地IDEA项目中


测试
package com.imooc.log
import com.ggstar.util.ip.IpHelper
/**
* IP解析工具类
*/
object IpUtils {
def getCity(ip:String) = {
IpHelper.findRegionByIp(ip)
}
def main(args: Array[String]) {
println(getCity("218.75.35.226"))
}
}
相关工具类
package com.imooc.log
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.{LongType, StringType, StructField, StructType}
/**
* 访问日志转换(输入==>输出)工具类
*/
object AccessConvertUtil {
//定义的输出的字段
val struct = StructType(
Array(
StructField("url",StringType),
StructField("cmsType",StringType),
StructField("cmsId",LongType),
StructField("traffic",LongType),
StructField("ip",StringType),
StructField("city",StringType),
StructField("time",StringType),
StructField("day",StringType)
)
)
/**
* 根据输入的每一行信息转换成输出的样式
* @param log 输入的每一行记录信息
*/
def parseLog(log:String) = {
try{
val splits = log.split("\t")
val url = splits(1)
val traffic = splits(2).toLong
val ip = splits(3)
val domain = "http://www.imooc.com/"
val cms = url.substring(url.indexOf(domain) + domain.length)
val cmsTypeId = cms.split("/")
var cmsType = ""
var cmsId = 0l
if(cmsTypeId.length > 1) {
cmsType = cmsTypeId(0)
cmsId = cmsTypeId(1).toLong
}
val city = IpUtils.getCity(ip)//需要加入外部ip解析工具
val time = splits(0)
val day = time.substring(0,10).replaceAll("-","")
//这个row里面的字段要和struct中的字段对应上
Row(url, cmsType, cmsId, traffic, ip, city, time, day)
} catch {
case e:Exception => Row(0)
}
}
}
数据清洗结果以及存储到目标地址
package com.imooc.log
import org.apache.spark.sql.{SaveMode, SparkSession}
/**
* 使用Spark完成我们的数据清洗操作
*/
object SparkStatCleanJob {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("SparkStatCleanJob")
.config("spark.sql.parquet.compression.codec","gzip")
.master("local[2]").getOrCreate()
//读取上一步清洗后的数据
val accessRDD = spark.sparkContext.textFile("/Users/rocky/data/imooc/access.log")
//accessRDD.take(10).foreach(println)
//RDD ==> DF
val accessDF = spark.createDataFrame(accessRDD.map(x => AccessConvertUtil.parseLog(x)),
AccessConvertUtil.struct)
// accessDF.printSchema()
// accessDF.show(false)
//按照day进行分区进行存储;coalesce(1)为了减少小文件;只有一个文件
accessDF.coalesce(1).write.format("parquet").mode(SaveMode.Overwrite)
.partitionBy("day").save("/Users/rocky/data/imooc/clean2")
spark.stop
}
}
输出的类型和结果

需求统计功能实现
Scala操作MySQL工具类开发
package com.imooc.log
import java.sql.{Connection, PreparedStatement, DriverManager}
/**
* MySQL操作工具类
*/
object MySQLUtils {
/**
* 获取数据库连接
*/
def getConnection() = {
DriverManager.getConnection("jdbc:mysql://localhost:3306/imooc_project?user=root&password=root")
}
/**
* 释放数据库连接等资源
* @param connection
* @param pstmt
*/
def release(connection: Connection, pstmt: PreparedStatement): Unit = {
try {
if (pstmt != null) {
pstmt.close()
}
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (connection != null) {
connection.close()
}
}
}
def main(args: Array[String]) {
println(getConnection())
}
}
创建相关表
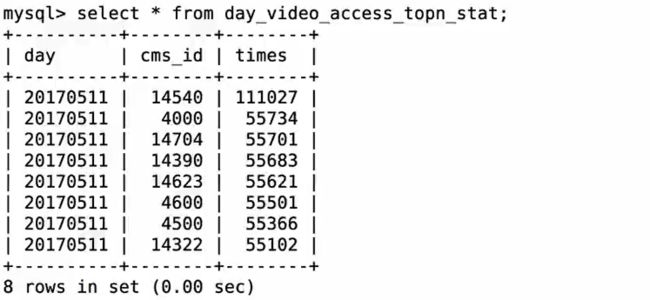
create table day_video_access_topn_stat (
day varchar(8) not null,
cms_id bigint(10) not null,
times bigint(10) not null,
primary key (day, cms_id)
);
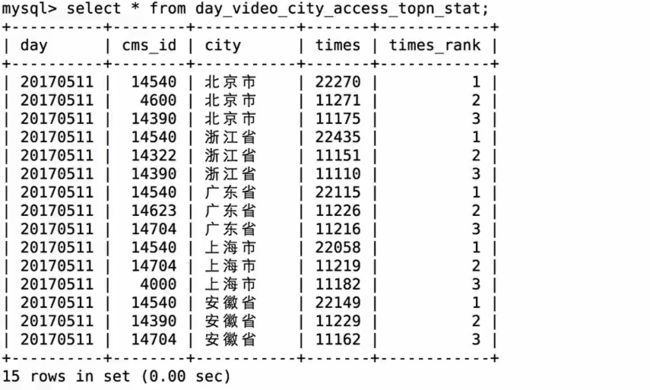
create table day_video_city_access_topn_stat (
day varchar(8) not null,
cms_id bigint(10) not null,
city varchar(20) not null,
times bigint(10) not null,
times_rank int not null,
primary key (day, cms_id, city)
);
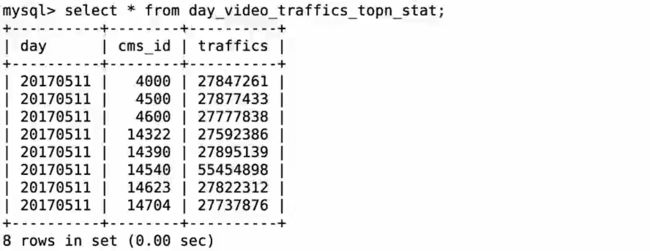
create table day_video_traffics_topn_stat (
day varchar(8) not null,
cms_id bigint(10) not null,
traffics bigint(20) not null,
primary key (day, cms_id)
);
每天课程访问次数实体类
package com.imooc.log
/**
* 每天课程访问次数实体类
*/
case class DayVideoAccessStat(day: String, cmsId: Long, times: Long)
各个维度统计的DAO操作
package com.imooc.log
import java.sql.{PreparedStatement, Connection}
import scala.collection.mutable.ListBuffer
/**
* 各个维度统计的DAO操作
*/
object StatDAO {
/**
* 批量保存DayVideoAccessStat到数据库
*/
def insertDayVideoAccessTopN(list: ListBuffer[DayVideoAccessStat]): Unit = {
var connection: Connection = null
var pstmt: PreparedStatement = null
try {
connection = MySQLUtils.getConnection()
connection.setAutoCommit(false) //设置手动提交
val sql = "insert into day_video_access_topn_stat(day,cms_id,times) values (?,?,?) "
pstmt = connection.prepareStatement(sql)
for (ele <- list) {
pstmt.setString(1, ele.day)
pstmt.setLong(2, ele.cmsId)
pstmt.setLong(3, ele.times)
pstmt.addBatch()
}
pstmt.executeBatch() // 执行批量处理
connection.commit() //手工提交
} catch {
case e: Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)
}
}
/**
* 批量保存DayCityVideoAccessStat到数据库
*/
def insertDayCityVideoAccessTopN(list: ListBuffer[DayCityVideoAccessStat]): Unit = {
var connection: Connection = null
var pstmt: PreparedStatement = null
try {
connection = MySQLUtils.getConnection()
connection.setAutoCommit(false) //设置手动提交
val sql = "insert into day_video_city_access_topn_stat(day,cms_id,city,times,times_rank) values (?,?,?,?,?) "
pstmt = connection.prepareStatement(sql)
for (ele <- list) {
pstmt.setString(1, ele.day)
pstmt.setLong(2, ele.cmsId)
pstmt.setString(3, ele.city)
pstmt.setLong(4, ele.times)
pstmt.setInt(5, ele.timesRank)
pstmt.addBatch()
}
pstmt.executeBatch() // 执行批量处理
connection.commit() //手工提交
} catch {
case e: Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)
}
}
/**
* 批量保存DayVideoTrafficsStat到数据库
*/
def insertDayVideoTrafficsAccessTopN(list: ListBuffer[DayVideoTrafficsStat]): Unit = {
var connection: Connection = null
var pstmt: PreparedStatement = null
try {
connection = MySQLUtils.getConnection()
connection.setAutoCommit(false) //设置手动提交
val sql = "insert into day_video_traffics_topn_stat(day,cms_id,traffics) values (?,?,?) "
pstmt = connection.prepareStatement(sql)
for (ele <- list) {
pstmt.setString(1, ele.day)
pstmt.setLong(2, ele.cmsId)
pstmt.setLong(3, ele.traffics)
pstmt.addBatch()
}
pstmt.executeBatch() // 执行批量处理
connection.commit() //手工提交
} catch {
case e: Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)
}
}
/**
* 删除指定日期的数据
*/
def deleteData(day: String): Unit = {
val tables = Array("day_video_access_topn_stat",
"day_video_city_access_topn_stat",
"day_video_traffics_topn_stat")
var connection:Connection = null
var pstmt:PreparedStatement = null
try{
connection = MySQLUtils.getConnection()
for(table <- tables) {
// delete from table ....
val deleteSQL = s"delete from $table where day = ?"
pstmt = connection.prepareStatement(deleteSQL)
pstmt.setString(1, day)
pstmt.executeUpdate()
}
}catch {
case e:Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)
}
}
}
使用DataFrame API完成统计分析
使用SQL API完成统计分析
调优点:
- 控制文件输出的大小: coalesce
- 分区字段的数据类型调整:spark.sql.sources.partitionColumnTypeInference.enabled
- 批量插入数据库数据,提交使用batch操作
package com.imooc.log
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
import org.apache.spark.sql.{DataFrame, SparkSession}
import scala.collection.mutable.ListBuffer
/**
* TopN统计Spark作业
*/
object TopNStatJob {
def main(args: Array[String]) {
//类型推测关闭;不然会将day的string类型推导为int类型
val spark = SparkSession.builder().appName("TopNStatJob")
.config("spark.sql.sources.partitionColumnTypeInference.enabled","false")
.master("local[2]").getOrCreate()
//读取上一步清洗后的数据
val accessDF = spark.read.format("parquet").load("/Users/rocky/data/imooc/clean")
// accessDF.printSchema()
// accessDF.show(false)
val day = "20170511"
StatDAO.deleteData(day)
//最受欢迎的TopN课程
videoAccessTopNStat(spark, accessDF, day)
//按照地市进行统计TopN课程
cityAccessTopNStat(spark, accessDF, day)
//按照流量进行统计
videoTrafficsTopNStat(spark, accessDF, day)
spark.stop()
}
/**
* 按照流量进行统计
*/
def videoTrafficsTopNStat(spark: SparkSession, accessDF:DataFrame, day:String): Unit = {
import spark.implicits._
val cityAccessTopNDF = accessDF.filter($"day" === day && $"cmsType" === "video")
.groupBy("day","cmsId").agg(sum("traffic").as("traffics"))
.orderBy($"traffics".desc)
//.show(false)
/**
* 将统计结果写入到MySQL中
*/
try {
cityAccessTopNDF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayVideoTrafficsStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val traffics = info.getAs[Long]("traffics")
list.append(DayVideoTrafficsStat(day, cmsId,traffics))
})
StatDAO.insertDayVideoTrafficsAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
}
/**
* 按照地市进行统计TopN课程
*/
def cityAccessTopNStat(spark: SparkSession, accessDF:DataFrame, day:String): Unit = {
import spark.implicits._
val cityAccessTopNDF = accessDF.filter($"day" === day && $"cmsType" === "video")
.groupBy("day","city","cmsId")
.agg(count("cmsId").as("times"))
//cityAccessTopNDF.show(false)
//Window函数在Spark SQL的使用
val top3DF = cityAccessTopNDF.select(
cityAccessTopNDF("day"),
cityAccessTopNDF("city"),
cityAccessTopNDF("cmsId"),
cityAccessTopNDF("times"),
row_number().over(Window.partitionBy(cityAccessTopNDF("city"))
.orderBy(cityAccessTopNDF("times").desc)
).as("times_rank")
).filter("times_rank <=3") //.show(false) //Top3
/**
* 将统计结果写入到MySQL中
*/
try {
top3DF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayCityVideoAccessStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val city = info.getAs[String]("city")
val times = info.getAs[Long]("times")
val timesRank = info.getAs[Int]("times_rank")
list.append(DayCityVideoAccessStat(day, cmsId, city, times, timesRank))
})
StatDAO.insertDayCityVideoAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
}
/**
* 最受欢迎的TopN课程
*/
def videoAccessTopNStat(spark: SparkSession, accessDF:DataFrame, day:String): Unit = {
/**
* 使用DataFrame的方式进行统计
*/
import spark.implicits._
val videoAccessTopNDF = accessDF.filter($"day" === day && $"cmsType" === "video")
.groupBy("day","cmsId").agg(count("cmsId").as("times")).orderBy($"times".desc)
videoAccessTopNDF.show(false)
/**
* 使用SQL的方式进行统计
*/
// accessDF.createOrReplaceTempView("access_logs")
// val videoAccessTopNDF = spark.sql("select day,cmsId, count(1) as times from access_logs " +
// "where day='20170511' and cmsType='video' " +
// "group by day,cmsId order by times desc")
//
// videoAccessTopNDF.show(false)
/**
* 将统计结果写入到MySQL中
*/
try {
videoAccessTopNDF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayVideoAccessStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val times = info.getAs[Long]("times")
/**
* 不建议大家在此处进行数据库的数据插入
*/
list.append(DayVideoAccessStat(day, cmsId, times))
})
StatDAO.insertDayVideoAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
}
}
Spark on YARN基础
在Spark中,支持4种运行模式:
1)Local:开发时使用
2)Standalone: 是Spark自带的,如果一个集群是Standalone的话,那么就需要在多台机器上同时部署Spark环境
3)YARN:建议大家在生产上使用该模式,统一使用YARN进行整个集群作业(MR、Spark)的资源调度
4)Mesos
不管使用什么模式,Spark应用程序的代码是一模一样的,只需要在提交的时候通过–master参数来指定我们的运行模式即可
Client
Driver运行在Client端(提交Spark作业的机器)
Client会和请求到的Container进行通信来完成作业的调度和执行,Client是不能退出的
日志信息会在控制台输出:便于我们测试
Cluster
Driver运行在ApplicationMaster中
Client只要提交完作业之后就可以关掉,因为作业已经在YARN上运行了
日志是在终端看不到的,因为日志是在Driver上,只能通过yarn logs -applicationIdapplication_id
yarn-client模式:
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--executor-memory 1G \
--num-executors 1 \
/home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/examples/jars/spark-examples_2.11-2.1.0.jar \
4
此处的yarn就是我们的yarn client模式
如果是yarn cluster模式的话,yarn-cluster
Exception in thread "main" java.lang.Exception: When running with master 'yarn' either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment.
错误原因:
如果想运行在YARN之上,那么就必须要在spark-env.sh设置HADOOP_CONF_DIR或者是YARN_CONF_DIR
1) export HADOOP_CONF_DIR=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
2) $SPARK_HOME/conf/spark-env.sh
yarn-cluster模式:
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn-cluster \
--executor-memory 1G \
--num-executors 1 \
/home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/examples/jars/spark-examples_2.11-2.1.0.jar \
4
yarn logs -applicationId application_1495632775836_0002
数据清洗作业运行到YARN上
重构
package com.imooc.log
import org.apache.spark.sql.{SaveMode, SparkSession}
/**
* 使用Spark完成我们的数据清洗操作:运行在YARN之上
*/
object SparkStatCleanJobYARN {
def main(args: Array[String]) {
if(args.length !=2) {
println("Usage: SparkStatCleanJobYARN " )
System.exit(1)
}
val Array(inputPath, outputPath) = args
val spark = SparkSession.builder().getOrCreate()
val accessRDD = spark.sparkContext.textFile(inputPath)
//RDD ==> DF
val accessDF = spark.createDataFrame(accessRDD.map(x => AccessConvertUtil.parseLog(x)),
AccessConvertUtil.struct)
accessDF.coalesce(1).write.format("parquet").mode(SaveMode.Overwrite)
.partitionBy("day").save(outputPath)
spark.stop
}
}
打包之前注意将不需要的依赖注释掉
比如下图中一个依赖添加就不会打进去
在开始的pom依赖中这个标签是注释掉的;去掉注释即可

打包时要注意,pom.xml中需要添加如下plugin
<plugin>
<artifactId>maven-assembly-pluginartifactId>
<configuration>
<archive>
<manifest>
<mainClass>mainClass>
manifest>
archive>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
configuration>
plugin>
我的pom文件改过后的样子
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.imooc.sparkgroupId>
<artifactId>sqlartifactId>
<version>1.0version>
<name>${project.artifactId}name>
<description>My wonderfull scala appdescription>
<inceptionYear>2010inceptionYear>
<licenses>
<license>
<name>My Licensename>
<url>http://....url>
<distribution>repodistribution>
license>
licenses>
<properties>
<maven.compiler.source>1.5maven.compiler.source>
<maven.compiler.target>1.5maven.compiler.target>
<encoding>UTF-8encoding>
<scala.version>2.11.8scala.version>
<spark.version>2.1.0spark.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>${spark.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_2.11artifactId>
<version>${spark.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.spark-project.hivegroupId>
<artifactId>hive-jdbcartifactId>
<version>1.2.1.spark2version>
<scope>providedscope>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.38version>
dependency>
<dependency>
<groupId>com.ggstargroupId>
<artifactId>ipdatabaseartifactId>
<version>1.0version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poi-ooxmlartifactId>
<version>3.14version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poiartifactId>
<version>3.14version>
dependency>
dependencies>
<build>
<sourceDirectory>src/main/scalasourceDirectory>
<testSourceDirectory>src/test/scalatestSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-toolsgroupId>
<artifactId>maven-scala-pluginartifactId>
<version>2.15.0version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
<configuration>
<args>
<arg>-dependencyfilearg>
<arg>${project.build.directory}/.scala_dependenciesarg>
args>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-surefire-pluginartifactId>
<version>2.6version>
<configuration>
<useFile>falseuseFile>
<disableXmlReport>truedisableXmlReport>
<includes>
<include>**/*Test.*include>
<include>**/*Suite.*include>
includes>
configuration>
plugin>
<plugin>
<artifactId>maven-assembly-pluginartifactId>
<configuration>
<archive>
<manifest>
<mainClass>mainClass>
manifest>
archive>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
configuration>
plugin>
plugins>
build>
project>
进入项目目录打包:
mvn assembly:assembly
将打好的jar放入服务器
运行之前注意将ip外部工具类所需文件放入服务器路径
/home/hadoop/lib/ipDatabase.csv,/home/hadoop/lib/ipRegion.xlsx
./bin/spark-submit \
--class com.imooc.log.SparkStatCleanJobYARN \
--name SparkStatCleanJobYARN \
--master yarn \
--executor-memory 1G \
--num-executors 1 \
--files /home/hadoop/lib/ipDatabase.csv,/home/hadoop/lib/ipRegion.xlsx \
/home/hadoop/lib/sql-1.0-jar-with-dependencies.jar \
hdfs://hadoop001:8020/imooc/input/* hdfs://hadoop001:8020/imooc/clean
注意:--files在spark中的使用
--files /home/hadoop/lib/ipDatabase.csv,/home/hadoop/lib/ipRegion.xlsx \
查看结果:
spark.read.format("parquet").load("/imooc/clean/day=20170511/part-00000-71d465d1-7338-4016-8d1a-729504a9f95e.snappy.parquet").show(false)
统计作业运行在YARN上
重构
package com.imooc.log
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
import org.apache.spark.sql.{DataFrame, SparkSession}
import scala.collection.mutable.ListBuffer
/**
* TopN统计Spark作业:运行在YARN之上
*/
object TopNStatJobYARN {
def main(args: Array[String]) {
if(args.length !=2) {
println("Usage: TopNStatJobYARN " )
System.exit(1)
}
val Array(inputPath, day) = args
val spark = SparkSession.builder()
.config("spark.sql.sources.partitionColumnTypeInference.enabled","false")
.getOrCreate()
val accessDF = spark.read.format("parquet").load(inputPath)
StatDAO.deleteData(day)
//最受欢迎的TopN课程
videoAccessTopNStat(spark, accessDF, day)
//按照地市进行统计TopN课程
cityAccessTopNStat(spark, accessDF, day)
//按照流量进行统计
videoTrafficsTopNStat(spark, accessDF, day)
spark.stop()
}
/**
* 按照流量进行统计
*/
def videoTrafficsTopNStat(spark: SparkSession, accessDF:DataFrame, day:String): Unit = {
import spark.implicits._
val cityAccessTopNDF = accessDF.filter($"day" === day && $"cmsType" === "video")
.groupBy("day","cmsId").agg(sum("traffic").as("traffics"))
.orderBy($"traffics".desc)
//.show(false)
/**
* 将统计结果写入到MySQL中
*/
try {
cityAccessTopNDF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayVideoTrafficsStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val traffics = info.getAs[Long]("traffics")
list.append(DayVideoTrafficsStat(day, cmsId,traffics))
})
StatDAO.insertDayVideoTrafficsAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
}
/**
* 按照地市进行统计TopN课程
*/
def cityAccessTopNStat(spark: SparkSession, accessDF:DataFrame, day:String): Unit = {
import spark.implicits._
val cityAccessTopNDF = accessDF.filter($"day" === day && $"cmsType" === "video")
.groupBy("day","city","cmsId")
.agg(count("cmsId").as("times"))
//cityAccessTopNDF.show(false)
//Window函数在Spark SQL的使用
val top3DF = cityAccessTopNDF.select(
cityAccessTopNDF("day"),
cityAccessTopNDF("city"),
cityAccessTopNDF("cmsId"),
cityAccessTopNDF("times"),
row_number().over(Window.partitionBy(cityAccessTopNDF("city"))
.orderBy(cityAccessTopNDF("times").desc)
).as("times_rank")
).filter("times_rank <=3") //.show(false) //Top3
/**
* 将统计结果写入到MySQL中
*/
try {
top3DF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayCityVideoAccessStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val city = info.getAs[String]("city")
val times = info.getAs[Long]("times")
val timesRank = info.getAs[Int]("times_rank")
list.append(DayCityVideoAccessStat(day, cmsId, city, times, timesRank))
})
StatDAO.insertDayCityVideoAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
}
/**
* 最受欢迎的TopN课程
*/
def videoAccessTopNStat(spark: SparkSession, accessDF:DataFrame, day:String): Unit = {
/**
* 使用DataFrame的方式进行统计
*/
import spark.implicits._
val videoAccessTopNDF = accessDF.filter($"day" === day && $"cmsType" === "video")
.groupBy("day","cmsId").agg(count("cmsId").as("times")).orderBy($"times".desc)
videoAccessTopNDF.show(false)
/**
* 使用SQL的方式进行统计
*/
// accessDF.createOrReplaceTempView("access_logs")
// val videoAccessTopNDF = spark.sql("select day,cmsId, count(1) as times from access_logs " +
// "where day='20170511' and cmsType='video' " +
// "group by day,cmsId order by times desc")
//
// videoAccessTopNDF.show(false)
/**
* 将统计结果写入到MySQL中
*/
try {
videoAccessTopNDF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayVideoAccessStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val times = info.getAs[Long]("times")
list.append(DayVideoAccessStat(day, cmsId, times))
})
StatDAO.insertDayVideoAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
}
}
注意服务器上的MySQL也要有相关表的创建。
打包和上小节一样
./bin/spark-submit \
--class com.imooc.log.TopNStatJobYARN \
--name TopNStatJobYARN \
--master yarn \
--executor-memory 1G \
--num-executors 1 \
/home/hadoop/lib/sql-1.0-jar-with-dependencies.jar \
hdfs://hadoop001:8020/imooc/clean 20170511
需求一表:
需求二表:
需求三表:
性能优化
性能优化之存储格式的选择
存储格式的选择:http://www.infoq.com/cn/articles/bigdata-store-choose/
性能调优之压缩格式的选择
压缩格式的选择:https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-compression-analysis/
注意如果要用支持分割的压缩格式,只有Bzip2直接支持分割
spark中支持配置压缩格式

性能优化之代码优化
- 选择高性能的算子
- 复用已有的数据
package com.imooc.log
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
import org.apache.spark.sql.{DataFrame, SparkSession}
import scala.collection.mutable.ListBuffer
/**
* TopN统计Spark作业:复用已有的数据
*/
object TopNStatJob2 {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("TopNStatJob")
.config("spark.sql.sources.partitionColumnTypeInference.enabled","false")
.master("local[2]").getOrCreate()
val accessDF = spark.read.format("parquet").load("/Users/rocky/data/imooc/clean")
// accessDF.printSchema()
// accessDF.show(false)
val day = "20170511"
import spark.implicits._
val commonDF = accessDF.filter($"day" === day && $"cmsType" === "video")
commonDF.cache()
StatDAO.deleteData(day)
//最受欢迎的TopN课程
videoAccessTopNStat(spark, commonDF)
//按照地市进行统计TopN课程
cityAccessTopNStat(spark, commonDF)
//按照流量进行统计
videoTrafficsTopNStat(spark, commonDF)
commonDF.unpersist(true)
spark.stop()
}
/**
* 按照流量进行统计
*/
def videoTrafficsTopNStat(spark: SparkSession, commonDF:DataFrame): Unit = {
import spark.implicits._
val cityAccessTopNDF = commonDF.groupBy("day","cmsId")
.agg(sum("traffic").as("traffics"))
.orderBy($"traffics".desc)
//.show(false)
/**
* 将统计结果写入到MySQL中
*/
try {
cityAccessTopNDF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayVideoTrafficsStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val traffics = info.getAs[Long]("traffics")
list.append(DayVideoTrafficsStat(day, cmsId,traffics))
})
StatDAO.insertDayVideoTrafficsAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
}
/**
* 按照地市进行统计TopN课程
*/
def cityAccessTopNStat(spark: SparkSession, commonDF:DataFrame): Unit = {
val cityAccessTopNDF = commonDF
.groupBy("day","city","cmsId")
.agg(count("cmsId").as("times"))
//cityAccessTopNDF.show(false)
//Window函数在Spark SQL的使用
val top3DF = cityAccessTopNDF.select(
cityAccessTopNDF("day"),
cityAccessTopNDF("city"),
cityAccessTopNDF("cmsId"),
cityAccessTopNDF("times"),
row_number().over(Window.partitionBy(cityAccessTopNDF("city"))
.orderBy(cityAccessTopNDF("times").desc)
).as("times_rank")
).filter("times_rank <=3") //.show(false) //Top3
/**
* 将统计结果写入到MySQL中
*/
try {
top3DF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayCityVideoAccessStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val city = info.getAs[String]("city")
val times = info.getAs[Long]("times")
val timesRank = info.getAs[Int]("times_rank")
list.append(DayCityVideoAccessStat(day, cmsId, city, times, timesRank))
})
StatDAO.insertDayCityVideoAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
}
/**
* 最受欢迎的TopN课程
*/
def videoAccessTopNStat(spark: SparkSession, commonDF:DataFrame): Unit = {
/**
* 使用DataFrame的方式进行统计
*/
import spark.implicits._
val videoAccessTopNDF = commonDF
.groupBy("day","cmsId").agg(count("cmsId").as("times")).orderBy($"times".desc)
videoAccessTopNDF.show(false)
/**
* 使用SQL的方式进行统计
*/
// accessDF.createOrReplaceTempView("access_logs")
// val videoAccessTopNDF = spark.sql("select day,cmsId, count(1) as times from access_logs " +
// "where day='20170511' and cmsType='video' " +
// "group by day,cmsId order by times desc")
//
// videoAccessTopNDF.show(false)
/**
* 将统计结果写入到MySQL中
*/
try {
videoAccessTopNDF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayVideoAccessStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val times = info.getAs[Long]("times")
/**
* 不建议大家在此处进行数据库的数据插入
*/
list.append(DayVideoAccessStat(day, cmsId, times))
})
StatDAO.insertDayVideoAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
}
}
性能调优之参数优化
http://spark.apache.org/docs/2.2.1/sql-programming-guide.html#other-configuration-options
![]()
一般在生产上200是不够用的
调整并行度
./bin/spark-submit \
--class com.imooc.log.TopNStatJobYARN \
--name TopNStatJobYARN \
--master yarn \
--executor-memory 1G \
--num-executors 1 \
--conf spark.sql.shuffle.partitions=100 \
/home/hadoop/lib/sql-1.0-jar-with-dependencies.jar \
hdfs://hadoop001:8020/imooc/clean 20170511
分区字段类型推测:spark.sql.sources.partitionColumnTypelnference.enabled
这个在上面某小节中已经提到过
功能实现之数据可视化展示概述
百度echarts:
http://echarts.baidu.com/echarts2/doc/example.html
数据可视化:一副图片最伟大的价值莫过于它能够使得我们实际看到的比我们期望看到的内容更加丰富
常见的可视化框架
1)echarts
2)highcharts
3)D3.js
4)HUE (不需要开发;直接sql就可图形化查看)
5)Zeppelin (不需要开发;直接sql就可图形化查看)
ECharts饼图静态数据展示
五分钟上手:
http://echarts.baidu.com/tutorial.html#5 分钟上手 ECharts
创建一个webapp

<html lang="en">
<head>
<meta charset="UTF-8">
<title>Echarts HelloWorldtitle>
<script src="js/echarts.min.js">script>
head>
<body>
<div id="main" style="width: 600px;height:400px;">div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据
var option = {
title : {
text: '某站点用户访问来源',
subtext: '纯属虚构',
x:'center'
},
tooltip : {
trigger: 'item',
formatter: "{a}
{b} : {c} ({d}%)"
},
legend: {
orient: 'vertical',
left: 'left',
data: ['直接访问','邮件营销','联盟广告','视频广告','搜索引擎']
},
series : [
{
name: '访问来源',
type: 'pie',
radius : '55%',
center: ['50%', '60%'],
data:[
{value:335, name:'直接访问'},
{value:310, name:'邮件营销'},
{value:234, name:'联盟广告'},
{value:135, name:'视频广告'},
{value:1548, name:'搜索引擎'}
],
itemStyle: {
emphasis: {
shadowBlur: 10,
shadowOffsetX: 0,
shadowColor: 'rgba(0, 0, 0, 0.5)'
}
}
}
]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
script>
body>
html>
右键运行test.html

结果

ECharts饼图动态展示之一查询MySQL中的数据
以下只是需求一的展示;其他需求和需求一实现方式一样
添加maven依赖
<dependencies>
<dependency>
<groupId>javax.servletgroupId>
<artifactId>servlet-apiartifactId>
<version>2.5version>
dependency>
<dependency>
<groupId>javax.servletgroupId>
<artifactId>jsp-apiartifactId>
<version>2.0version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.38version>
dependency>
<dependency>
<groupId>net.sf.json-libgroupId>
<artifactId>json-libartifactId>
<version>2.4version>
<classifier>jdk15classifier>
dependency>
dependencies>
Utils工具类
package com.imooc.utils;
import java.sql.*;
/**
* 操作MySQL的工具类
*/
public class MySQLUtils {
private static final String USERNAME = "root";
private static final String PASSWORD = "root";
private static final String DRIVERCLASS = "com.mysql.jdbc.Driver";
private static final String URL = "jdbc:mysql://localhost:3306/imooc_project";
/**
* 获取数据库连接
*/
public static Connection getConnection() {
Connection connection = null;
try {
Class.forName(DRIVERCLASS);
connection = DriverManager.getConnection(URL,USERNAME,PASSWORD);
} catch (Exception e) {
e.printStackTrace();
}
return connection;
}
/**
* 释放资源
*/
public static void release(Connection connection, PreparedStatement pstmt, ResultSet rs) {
if(rs != null) {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(pstmt != null) {
try {
pstmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(connection != null) {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
System.out.println(getConnection());
}
}
实体类
package com.imooc.domain;
public class VideoAccessTopN {
private String name;
private long value ;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public long getValue() {
return value;
}
public void setValue(long value) {
this.value = value;
}
}
dao层
package com.imooc.dao;
import com.imooc.domain.VideoAccessTopN;
import com.imooc.utils.MySQLUtils;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 面向接口编程
*/
public class VideoAccessTopNDAO {
static Map<String,String> courses = new HashMap<String,String>();
static {
courses.put("4000", "MySQL优化");
courses.put("4500", "Crontab");
courses.put("4600", "Swift");
courses.put("14540", "SpringData");
courses.put("14704", "R");
courses.put("14390", "机器学习");
courses.put("14322", "redis");
courses.put("14390", "神经网络");
courses.put("14623", "Docker");
}
/**
* 根据课程编号查询课程名称
*/
public String getCourseName(String id) {
return courses.get(id);
}
/**
* 根据day查询当天的最受欢迎的Top5课程
* @param day
*/
public List<VideoAccessTopN> query(String day) {
List<VideoAccessTopN> list = new ArrayList<VideoAccessTopN>();
Connection connection = null;
PreparedStatement psmt = null;
ResultSet rs = null;
try {
connection = MySQLUtils.getConnection();
String sql = "select cms_id ,times from day_video_access_topn_stat where day =? order by times desc limit 5";
psmt = connection.prepareStatement(sql);
psmt.setString(1, day);
rs = psmt.executeQuery();
VideoAccessTopN domain = null;
while(rs.next()) {
domain = new VideoAccessTopN();
/**
* TODO... 在页面上应该显示的是课程名称,而我们此时拿到的是课程编号
*
* 如何根据课程编号去获取课程名称呢?
* 编号和名称是有一个对应关系的,一般是存放在关系型数据库
*/
domain.setName(getCourseName(rs.getLong("cms_id")+""));
domain.setValue(rs.getLong("times"));
list.add(domain);
}
}catch (Exception e) {
e.printStackTrace();
} finally {
MySQLUtils.release(connection, psmt, rs);
}
return list;
}
public static void main(String[] args) {
VideoAccessTopNDAO dao = new VideoAccessTopNDAO();
List<VideoAccessTopN> list = dao.query("20170511");
for(VideoAccessTopN result: list) {
System.out.println(result.getName() + " , " + result.getValue());
}
}
}
web层
package com.imooc.web;
import com.imooc.dao.VideoAccessTopNDAO;
import com.imooc.domain.VideoAccessTopN;
import net.sf.json.JSONArray;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.List;
/**
* 最受欢迎的TOPN课程
*
* Web ==> Service ==> DAO
*/
public class VideoAccessTopNServlet extends HttpServlet{
private VideoAccessTopNDAO dao;
@Override
public void init() throws ServletException {
dao = new VideoAccessTopNDAO();
}
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String day = req.getParameter("day");
List<VideoAccessTopN> results = dao.query(day);
JSONArray json = JSONArray.fromObject(results);
resp.setContentType("text/html;charset=utf-8");
PrintWriter writer = resp.getWriter();
writer.println(json);
writer.flush();
writer.close();
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
this.doGet(req, resp);
}
}
ECharts饼图动态展示之二前端开发
web.xml配置
<web-app>
<display-name>Archetype Created Web Applicationdisplay-name>
<servlet>
<servlet-name>statservlet-name>
<servlet-class>com.imooc.web.VideoAccessTopNServletservlet-class>
servlet>
<servlet-mapping>
<servlet-name>statservlet-name>
<url-pattern>/staturl-pattern>
servlet-mapping>
web-app>
topn需求一的页面
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Echarts HelloWorldtitle>
<script src="js/echarts.min.js">script>
<SCRIPT src="js/jquery.js">SCRIPT>
head>
<body>
<div id="main" style="width: 600px;height:400px;">div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据
var option = {
title : {
text: '主站最受欢迎的TopN课程',
x:'center'
},
tooltip : {
trigger: 'item',
formatter: "{a}
{b} : {c} ({d}%)"
},
legend: {
orient: 'vertical',
left: 'left',
data: []
},
series : [
{
name: '访问次数',
type: 'pie',
radius : '55%',
center: ['50%', '60%'],
data:(function(){
var courses = [];
$.ajax({
type:"GET",
url:"/stat?day=20170511",
dataType:'json',
async:false,
success:function(result) {
for(var i=0;i<result.length; i++){
courses.push({"value": result[i].value,"name":result[i].name});
}
}
})
return courses;
})(),
itemStyle: {
emphasis: {
shadowBlur: 10,
shadowOffsetX: 0,
shadowColor: 'rgba(0, 0, 0, 0.5)'
}
}
}
]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
script>
body>
html>

使用Zeppelin进行统计结果的展示
下载Zeppelin
http://zeppelin.apache.org/download.html
解压后直接进入bin目录运行
![]()
默认端口是8080;打开后