知识图谱阶段汇总
这是在实习结束前,给同事交接时候写得文档,离职前和这位博士师兄聊了很多,也教了我很多东西,如果他早点来公司就好了,那样能跟他学习更多的东西了。这个是很基础的知识图谱的学习资料,我想着这个文档还是公开吧,个人觉得还是比较清晰详细的,希望能够帮助更多人。
最后两个学期,就多专注于一些算法了。
第一章 知识图谱简介
1.1 知识图谱的基本概念
当下,知识图谱逐渐成为继万维网web1.0(1990-2000)、群体智能web2.0(2000-2006)后新一代知识表示方法,其主要代表为DBpedia,Freebase,KnowItAll,WikiTaxonomy和YAGO等[1]。
知识图谱主要由以下部分组成:
- 概念:对具有相同属性的事物的概括和抽象(类似于 neo4j中的标签),如人类和办公用品是两种概念。
- 实体:指的是客观世界中的事物,比如某个人,型号为华为p30的手机等
- 关系:两个实体之间的关系,比如两个人之间是情侣关系,同事关系等。
- 属性:实体或者关系的一些属性,实体的属性如一个人的年龄,身高体重等信息。关系的属性包括两个人的关系是情侣,这个情侣关系的属性如交往时间等。
图谱的基本组成形式为三元组形式,即【实体】-【关系】-【实体】,如图所示:
上图中,圆圈代表实体,两个实体之间的连线代表关系,实体不同颜色可以代表不同的概念(标签),可以根据职业划分标签,可以根据年龄段划分标签等等,不同标签的名称不一样。
1.2 知识图谱搭建流程
知识图谱完整流程如下所示:
| 知识建模(图谱设计)→知识获取→知识融合(自然语言处理技术)→知识储存→ 知识计算(推理计算,可以应用于金融反欺诈,行业发展趋势等等)→知识应用 |
我们的工作将知识图谱按照以下四个步骤进行搭建:数据预处理→知识图谱的设计→数据导入到Neo4j→后续操作。
第二章 数据预处理(知识获取+知识融合)
由于知识图谱处理的数据,多为文字的形式,原始数据可能为一大段话,一篇文章,一本书等形式,因此首先需要将数据整理成结构化的形式,便于后续的知识图谱搭建。
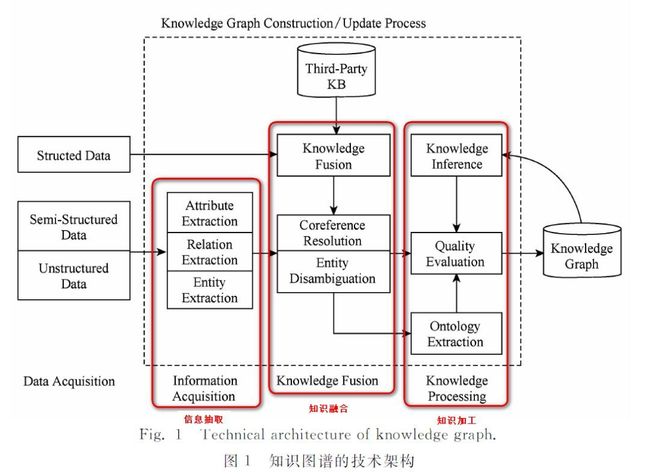
从上图中可以看出,数据预处理在知识图谱构建中占据很大的工作量。
2. 1 数据预流程
- 数据获取:通过网络爬虫、数据下载等方式获取数据。
- 数据整理:将原始数据整理成结构化形式,便于Python的读取,这样可用于后续的知识图谱设计搭建。且将结构化的数据储存为json、txt、xlsx、csv等文件。如json形式:{“name1”:”content1”, “name2”:”content2”,…..}
2.2 涉及到的技术
1.网络爬虫技术
2.对于全部是文字的原始数据,需要对其进行自然语言处理,包括不限于:
1. 实体抽取:也就是命名实体识别,包括实体的检测及分类
2. 关系抽取:通常我们说的三元组抽取,一个谓词带2个形参,如 Founding-location
3. 实体统一:如“中国”和“中华人民共和国”指的是一个实体,需要进行实体统一。
4. 指带消解: 如“小明来了,今天他穿着红色的衣服”,这里“他”指的是小明。
2.3 注意事项
- 结构化数据质量的好坏,决定知识图谱内容的好坏。
- 对于数据存在的分隔符,尽量统一分隔符,便于后续处理。
- 我们之前没有做相关的内容,只是将别人爬去的数据直接下载拿来用,发现他们的数据存在数据格式不统一、分隔符种类多、单位不统一、名字混乱、有’\n’,’\t’等内容的情况,造成了后续处理较为麻烦,因此数据结构化是非常重要的过程。
第三章 知识图谱的设计(知识建模)
3.1 知识图谱设计思想
首先需要对行业知识有相应的了解,明确想要建立的图谱结构,确定好实体,属性以及关系,设计结构需合理。

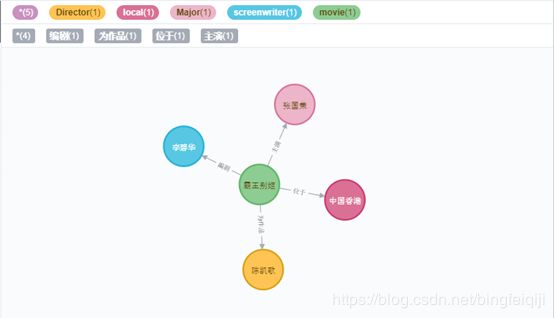
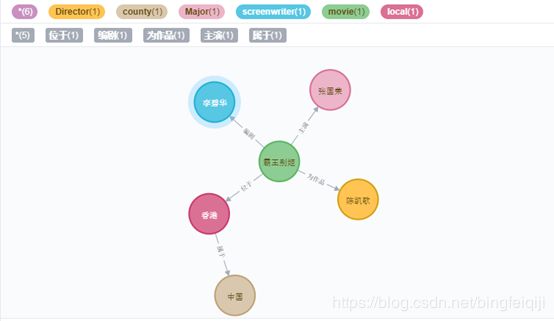
图谱的结构需要自己权衡。如我们电影知识图谱案例中,定义的实体包括:导演,主演,编剧,电影类型,制片地区;属性包括电影名称,电影网址,电影中文名等。这里面是我们自己定义的,但其实制片地区可以设计成属性的形式,也可以设计成制片国家→制片省份/州→制片城市的三层次实体形式。如下图所示为不同的知识图谱设计结构:
第四章 数据导入到Neo4j(知识储存)
将数据导入Neo4j有多种方法,但是速度和效率不同[5],具体比较如下图所示:
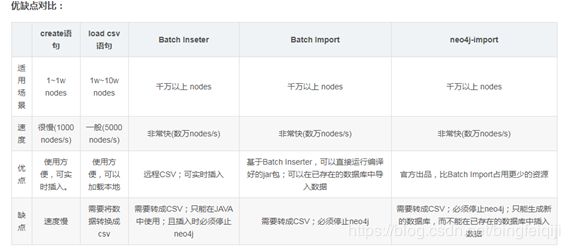
本报告介绍的创建包括两种,python-py2neo创建与import创建。
4.1 环境
Python: Python3
Neo4j:Neo4j DeskTop
Python依赖包:py2neo, hashlib, re, json, os, pandas等
4.2 使用Python中的py2neo包导入数据流程
1. 主要依赖函数:py2neo模块中的Graph,Node
2. 使用python联结neo4j:
1. 打开neo4j数据库
2. 使用Graph函数联结neo4j,函数中的参数要对应,即可联结neo4j
3. 导入实体:
1.由于在知识图谱设计的过程中,已经将实体与关系确定并存储到变量中,因此可以直接使用
2.使用Node函数创建实体,该python函数对应数据库中create函数
4. 导入关系:
1.实际在py2neo模块中有relationship函数可以对应数据库中 create(u:…)-[r:…]->[n:..]命令,但是relationship函数需要创建实体的过程中,同时导入关系,效率较低,因此不使用该函数创建关系
2.在python中使用数据库语言create(u:…)-[r:…]->[n:..] 创建关系的方式为定义好后使用Graph().run()函数
4.3 使用Neo4j – import 导入数据
1. 将实体,关系提取后转化为csv文件,抬头的名称如下形式: (注意这里必须是csv文件)
实体:Name_id:ID; name; attribute1; attribute2; ,,,; :LABEL
关系:: STARD_ID; ROLE; :END_ID; :TYPE
2. 将生成后的csv数据,复制到原数据库import文件夹下
3. 在数据库文件夹下打开cmd,输入:
.\bin\neo4j-admin import --nodes=import\movies2.csv --nodes=import\actors2.csv --relationships=import\roles2.csv 第五章 数据查询(知识计算+知识应用)
5.1 数据查询相关内容
- 数据库常用查询函数:MATCH ; WHERE; RETURN. 这几个函数通常不是单独使用,而是组合在一起使用。
- 在知识问答中,有一种最简单的方法为将所有想到的关键词归类,如果在问句中出现已经归类的关键词,则返回对应的问题,并从数据库中查询
- 在python查询数据库
(1) 使用Graph()函数连接Neo4j
(2) 创建好查询语句,如 “MATCH (u:movie), where u.name=霸王别姬, return u”
(3) 使用Graph().run()函数运行查询语句
第六章 个人总结与思考
1. 知识图谱是一项很复杂的工作,将数据导入到Neo4j只是知识图谱创建的一项基本工作,我们之前做过的内容也只是一小部分。数据预处理过程是非常占据工作量的,而且这一部分工作能直接影响知识图谱内容好坏。
2. 据我们现在的了解:基于Neo4j 储存数据的工作的优点是高效易懂,缺点是不能像RDF形式那样可以进行知识图谱的知识推理。比如使用RDF可以定义父类和子类,可以定义类别之间的对立、包含关系等,这是图数据库做不到的。我想基于图数据库的知识图谱如果想要做到这一点,可能在后续应用的中,撰写代码实现,而不是在图数据库中实现。
3.使用RDF建立知识图谱应该可以借助Protégé这个工具实现,其中官方文档为英文的,相较于新版protégé,官方文档有些地方是错误的。我们对照英文文档翻译成中文的,有改进也有省略。在.\知识图谱自编\ protege学习笔记当中。官网的protégé 不好下,需要重复多次。
参考文献
[1] 2018知识图谱发展报告.pdf
[2] https://xz.aliyun.com/t/2139
[3]http://www.4u4v.net/xiang-jie-zi-xia-er-shang-gou-jian-zhi-shi-tu-pu-quan-guo-cheng.html
[4] 知识图谱技术与应用-李文哲.docx
[5] https://blog.csdn.net/qq_32519415/article/details/87942379
[6] https://neo4j.com/docs/operations-manual/current/tutorial/import-tool/