《并行计算》期末总结
《并行计算》总结
标签: 并行计算
| . | . |
|---|---|
| 郑冬健 | [email protected] |
- 更新日志
| 编号 | 更新时间 | 内容 |
|---|---|---|
| 1 | 201606062144 | Openmp gcc 编译选项为-fopenmp |
| 2 | 201606062144 | 虚进程不能避免死锁,系理解错误 |
一、并行介绍
域分解
- 针对的分解对象:数据
- 首先确定数据如何划分到各处理器
- 然后确定各处理器要做的事情
- 示例:求最大值
任务(功能)分解
- 针对的分解对象:任务(功能)
- 首先将任务划分到各处理器
- 然后确定各处理器要处理的数据
二、并行硬件性能
Flynn弗林分类
- SISD: Single Instruction stream Single Data stream
- SIMD
- MISD
- MIMD
并行计算机结构模型
- PVP(Parellel Vector Processor),并行向量处理机。特点:不使用高速缓存,而是使用大量向量寄存器和指令缓存。只有充分考虑了向量处理特点的程序才能获得较好的性能。
- SMP(Symmetric Multiprocessor),并行多处理器,共享存储器。扩展性有限。
- MPP(Massively Parellel Processor),大规模并行处理器。只有微内核(每个节点无独立的操作系统etc),高通信带宽,低延迟互联网络,分布存储。异步MIMD。
- Cluster,集群。分布存储,每个节点是一个完整的计算机。投资风险小、结构灵活、性价比高、充分利用分散的计算资源、可扩展性好。问题:通信性能。
内存访问模型
- UMA(Uniform Memory Access),均匀存储访问。
- 物理存储器被均匀共享(访存时间)
- 可带私有Cache
- 外围设备也共享
- NUMA(Nonuniform Memory Access),非均匀存储访问。
- 被共享的存储器分布在所有处理器中
- 处理器访问存储器的时间不同:本地(LM)和群内共享(CSM)较快,外地和全局共享(GSM)较慢
- 可带私有Cache
- 外围设备共享
- NORMA(No-Remote Memory Access),非远程存储访问
- 所有存储器私有
- 节点间通过消息传递进行数据交换 -> 网络、环网、超立方、立方环
多核技术
- 摩尔定律(18个月单位面积晶体管数量翻一倍)
- Power Wall(性能越高,提高性能需要的功率越大)
Memory Wall,内存性能提高不及CPU
- 多核(Dual core)与超线程(Hyper Thread, HT)
- 双核是真正意义上的双处理器,不会发生资源冲突,每个线程拥有自己的缓存、寄存器和运算器
- 超线程提高性能>1/3,双核相当于 2×NHT
性能指标
- 执行时间 Elapsed Time, Tn=T计算+T并行开销+T通信
- 浮点运算数 Flop (Floating-point operation)
- 指令数目 MIPS (Million Instructions Per Sencond)
- 计算/通信比 TcompTcomm
- 加速比 S(n)=tstp
- 效率 E=tstp×n
- 代价 Cost=tsnS(n)=tsE
处理器数 P ,问题规模 W (串行分量 Ws ),并行化部分 Wp ,串行时间 Ts ,并行时间 Tp ,加速比 S ,效率 E
- 加速比定律 前两个拷一个
- Amdahl定律: 固定的计算负载,增加处理器数量加速。
S=Ws+WpWs+Wpp=f+(1−f)f+(1−f)/p=p1−f(p−1)
- Gustafson定律:增加计算量,响应增多处理器,以提高精度。
S′=Ws+pWpWs+pWp/p=f+p(1−f)=p−f(p−1)
- Sun and Ni定律:存储受限。
S′′=fW+(1−f)G(p)WfW+(1−f)G(p)W/p=f+(1−f)G(p)f+(1−f)G(p)/p
- G(p)=1 时为Amdahl定律
- G(p)=p 为Gustafson定律
- G(p)>p 时加速比Amdahl和Gustafson高
三、内存系统和多线程
内存系统对性能的影响
- 对很多应用而言,瓶颈在于内存系统,而不是CPU
- 内存性能包括:延迟和带宽
- 延迟:处理器向内存发起访问直到获取数据所需要的时间
- 带宽:内存系统向处理器传输数据的速率
- 想要立刻扑灭火灾 → 减少延迟
- 想要扑灭更大的火 → 增加带宽
- 使用高速缓存改善延迟
- 高速缓存生效的关键是:数据被重复利用。由高速缓存提供的数据份额称为高速缓存命中率
- 计算题:增加缓存后的峰值计算速度(MFLOPS)
- 时间本地性:对相同数据项的重复引用
- 空间本地性:对数据布局的假设 => 连续的数据字被连续的指令所使用。
- 时间本地性和空间本地性对减少内存延迟和提高有效内存带宽非常重要
- 提高整体计算性能的参考指标之一: 计算次数内存访问次数
多线程基本概念
- 线程是进程上下文中执行的代码序列,又称“轻量级进程”
| 比较 | 进程 | 线程 |
|---|---|---|
| 调度 | 代价大 | 代价小 |
| 并发性 | 可以并发执行 | 也可以并发执行,并发性更好 |
| 拥有资源 | 拥有自己的资源 | 除部分必不可少的栈和寄存器,不拥有自己的资源 |
| 系统开销 | 创建和撤销要分配/回收资源,耗时大 | 线程切换只涉及少量寄存器的操作,不涉及存储管理方面的操作,切换较为容易 |
- 线程层次
- 用户级线程:通过线程库实现
- 核心级线程:操作系统直接实现
- 硬件线程:线程在硬件执行资源上的表现形式
- 单个线程一般包括上述三个层次的表现:用户级线程通过操作系统被作为核心级线程实现,再通过硬件相应的接口作为硬件线程来执行
- 线程的声明周期
- 就绪状态:创建;唤醒
- 就绪状态 → 运行状态:进程调用
- 等待状态:睡眠
消亡
- 线程的同步
- 竞争条件:两个或多个进程视图在同一时刻访问共享内存,或读写某些共享数据,而最后的结果取决于线程执行的顺序,就成为竞争条件(Race Conditions)
- Bernstein条件: I1∩O2=∅,I2∩O1=∅,O1∩O2=∅ ,总结起来,就是 → 不能同时写←_←。满足Bernsteni条件的两个线程可以同步执行。
- 同步方法
- 临界区:包含有共享数据的一段代码,这些代码可能被多个线程执行。
- 信号量:用一个证书变量sem表示;两个原子操作(P和V) ⟶sem_post sem_wait
- 互斥锁:一种锁,线程在对共享资源进行访问前必须先获得锁。 → 死锁
- 条件变量:用于通知共享数据状态信息,当特定条件满足时,线程等待或者唤醒其他合作线程。 ⟶ pthread_cond_signal pthread_cond_broadcast
- 竞争条件:两个或多个进程视图在同一时刻访问共享内存,或读写某些共享数据,而最后的结果取决于线程执行的顺序,就成为竞争条件(Race Conditions)
pthread
| POSIX | func |
|---|---|
| pthread_cancel | 终止另一个线程 |
| pthread_create | 创建一个线程 |
| pthread_detach | |
| pthread_equal | 测试TID相等 |
| pthread_exit | |
| pthread_join | |
| pthread_self |
- pthread_mutex_t mtx
- pthread_mutex_init(&mtx, NULL);
- pthread_mutex_lock pthread_mutex_unlock
- pthread_mutex_destroy
实例:计算数组中3出现次数
- Cache一致性
- 假共享(solve: add padding)
四、OpenMP
OpenMP概述
- 是一种面向共享内存以及分布式共享内存的多处理器多线程并行编程语言
- 是一种能够被用于显示制导多线程、共享内存并行的应用程序编程接口(API)
- 编程模型:Fork-Join,并行时派生线程,并行结束后Join各线程
OpenMP实现
- 较新版本的gcc可在编译时指定
-popenmp-fopenmp - 编译制导语句:使用
#pragma omp parellel标识并行程序块
- 并行域:并行域中的代码被所有线程执行
- 共享任务:将其所包含的代码划分给线程组的各成员来执行(for、sections、single)
- for:。。。
- sections:内部代码划分给各线程
- single:内部代码只由一个线程执行
- 同步
- master:指定代码段只有主线程执行
- critical:域中的代码只能执行一个线程,其他线程被阻塞在临界区
- barrier:同步一个线程组中的所有线程
- atomic:指定特定的存储单元将被原子更新(x binop = expr)
- flush:标识一个同步点,用以确保所有线程看到一致的存储器视图
- ordered:指定其包含循环的执行按循环次序进行(任何时候只能有一个线程执行被ordered所限定的部分)
- 数据域属性子句
| 子句 | 功能 |
|---|---|
| private | 列出的变量对每个线程私有 |
| shared | 列出的变量为所有线程共享 |
| default | ? |
| firstprivate | 私有,且原子初始化 |
| lastprivate | 私有,且原始变量由最后一次迭代的赋值所修改 |
| reduction | 对列表中出现的变量进行归约 |
| threadprivate | 使一个全局文件作用域的变量在并行域内编程每个线程私有。每个线程对该变量赋值一份私有拷贝。 |
| copyin | 用来为线程组中所有线程的threadprivate变量赋相同的值 |
| copyprivate | ? |
运行时库函数:
omp.h环境变量:
OMP_SCHEDULE, etc
五、MPI(Message Passing Interface)
概述
- 是一种标准或规范的代表,也是一种消息传递编程模型。
- MPI的实现是一个库,而不是一门语言
- MPI属于SPMD,Single Program Multiple Data;MPI属于弗林(Flynn)分类中的MIMD,Multiple Instruction stream Multiple Data stream。
- 六个基本接口(默认通讯域为
MPI_COMM_WORLD)
| 接口 | 说明 |
|---|---|
| MPI_Init | MPI初始化,开始 |
| MPI_Finalize | MPI结束 |
| MPI_Comm_size | 获取通信域内进程数量 |
| MPI_Comm_rank | 获取当前进程的编号 |
| MPI_Send | 发送消息(数据) |
| MPI_Recv | 接收消息(数据) |
点到点通信
- 默认通讯域名称:
MPI_COMM_WORLD
- 可以用
MPI_Comm_split(MPI_Comm comm, int color, int key, MPI_Comm* newcomm)创建一个通信域。color用来划分处理器。
- 可以用
- MPI_Send:发送消息
- MPI_Recv:接收消息
- 消息标签:避免两条消息混淆。情形一:同一进程发出的两条消息,无法区分一条消息是否已经传输完毕;情形二:多个进程向同一进程发送消息,无法区分消息来源。
阻塞通信
| 前缀 | 含义 |
|---|---|
| - | 标准通信模式 |
| B | 缓存通信模式 |
| S | 同步通信模式 |
| R | 就绪通信模式 |
| 通信模式 | 说明 |
|---|---|
| 标准通信模式 | MPI_Send同步发送( → 死锁)、异步发送 |
| 缓存通信模式 | MPI_Bsend,用户自己管理缓冲区 |
| 同步通信模式 | 本身不依赖接收是否已经启动,但MPI_Ssend同步发送必须等到接收进程开始后才能正确返回。返回时说明数据已经全部进入缓冲,刚开始发送 |
| 就绪通信模式 | MPI_Rsend只有当接收进程的接收操作已经启动时,才可以在发送进程启动发送操作 |
非阻塞通信
| 前缀 | 含义 |
|---|---|
| - | 标准通信模式 |
| B | 缓存通信模式 |
| S | 同步通信模式 |
| R | 就绪通信模式 |
| 通信模式 | 发送 | 接收 |
|---|---|---|
| 标准通信模式 | MPI_Isend,立即返回 |
MPI_Irecv |
| 缓存通信模式 | MPI_Ibsend |
- |
| 同步通信模式 | MPI_Issend |
- |
| 就绪通信模式 | MPI_Irsend |
- |
| 重复非阻塞通信模式 | MPI_Send_init MPI_Bsend_init等 |
- |
重复非阻塞通信模式用于需要重复进行通信的情形,如一个for循环内部。
非阻塞通信的完成与检测
- 检测:
MPI_Test、MPI_Testany、MPI_Testsome、MPI_Testall - 完成:
MPI_Wait、MPI_Waitany、MPI_Waitsome、MPI_Waitall
- 检测:
Jacobi迭代
hi,j=hi−1,j+hi+1,j+hi,j−1+hi,j+14
- 使用非阻塞操作,或者捆绑发送接收,
或者虚进程,以避免死锁 - 胡诌的一份伪码(使用非阻塞发送):
int right_rank = rank == max_rank ? 0 : rank + 1;
int left_rank = rank == 0 ? max_rank : rank - 1;
MPI_Issend(data, count, MPI_DOUBLE, right_rank, tag1, MPI_COMM_WORLD);
MPI_Irecv(buffer, count, MPI_DOUBLE, left_rank, tag2, MPI_COMM_WORLD);
MPI_Wait...MPI_Sendrecv捆绑发送和虚进程
- 捆绑发送接收:把发送一个消息到一个目的地和从另一个进程接收一个消息合并到一个调用中,源和目的可以相同
- 语义上等价于一个发送和一个接收操作,但操作由通信系统来实现,系统会优化通讯次序,避免不合理次序,可以有效避免死锁。
- 非对称,一个捆绑发送接收调用发出的消息可以被普通接收操作接收,反之亦然。
- 该操作执行一个阻塞的发送和接收,接收和发送使用同一个通信域
MPI_Sendrecv(
void* sendbuf,
int sendcount,
MPI_Datatype sendtype,
int dest,
int sendtag,
void* recvbuf,
int recvcount,
MPI_Datatype recvtype,
int source,
int recvtag,
MPI_Comm comm,
MPI_Status* status
)- 虚拟进程: MPI_PROC_NULL :为了方便程序的编写。向虚进程发送数据或者从虚进程接收数据时,调用都会立即正确返回,如同执行了一个空操作。
- mpicc v11.1将上述
MPI_PROC_NULL定义为整数-2,不会和正常的编号( ≥0 )产生冲突,因此可以让MPI对其特殊处理。
- mpicc v11.1将上述
if (myrank > 0) {
leftrank = myrank - 1;
} else {
leftrank = MPI_PROC_NULL;
}
//n是最大进程编号
if (myrank < n) {
rightrank = myrank + 1;
} else {
rightrank = MPI_PROC_NULL;
}
//数据向右平移
MPI_Sendrecv(send_data1, send_count, MPI_FLOAT, rightrank, tag1, recv_data1, recv_count, MPI_FLOAT, leftrank, tag1, MPI_COMM_WORLD, status);
//数据向左平移
MPI_Sendrecv(send_data2, send_count, MPI_FLOAT, leftrank, tag1, recv_data2, recv_count, MPI_FLOAT, rightrank, tag1, MPI_COMM_WORLD, status);组通信
| 组通信类型 | |
|---|---|
| 一到多, Broadcast,Scatter | 广播(bcast,发送消息给某一通信域内的所有进程),发散(scatter,向某一通信域内的所有进程发送一个不同的消息) |
| 多到一, Reduce,Gather | root进程接收各个进程(包括自己)的消息,通信连接按rank号进行。Reduce会进一步做归约处理(Max, Min, Sum等) |
| 多到多, Allreduce,Allgather,Alltoall | 每个进程都从其他进程接收消息。Reduce同上。Alltoall接发阵列 |
| 同步 , Barrier | 同步各进程 |
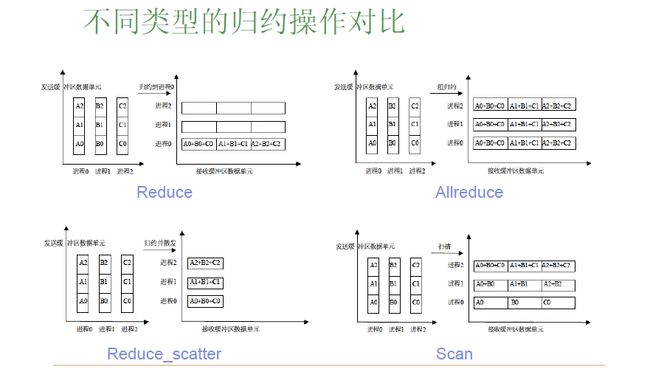
- 不同类型的归约操作对比
| 归约操作 | 功能 |
|---|---|
| Reduce | 归约到某一进程 |
| Reduce_scatter | 归约并散发 |
| Allreduce | 组归约,每个进程的缓冲区都得到相同的归约结果 |
| Scan | 每个进程对排在前面的进程做归约 |
MPI数据类型
| MPI数据类型 | 对应C/C++数据类型 |
|---|---|
| MPI_FLOAT | float |
| … | … |
- 自定义数据类型
- 结构体
- 连续数据
- 向量
虚拟进程拓扑
- 某些应用中,进程的线性排列不能充分反应进程间下逻辑上的通信模型。进程经常被排列成二维或三维网格形式的拓扑模型,而且通常用一个图类描述逻辑进程排列。这种逻辑进程排列成为虚拟拓扑。
- 只能用在组内(inter-communicator)通信域上
- 便于命名
- 简化代码编写
- 辅助运行时系统将进程映射到实际的硬件结构之上
- 便于MPI内部对通信进行优化
.
- 分类
- 笛卡尔拓扑
- 每个进程处于一个虚拟的网格内,与其邻居通信
- 边界可以构成环
- 通过笛卡尔坐标来标识进程
- 任何两个进程也可以通信
- 图拓扑
- 适用于复杂的通信环境
- 笛卡尔拓扑
.
- 相关调用
| MPI调用 | 功能 |
|---|---|
MPI_Cart_create |
创建虚拟拓扑 |
MPI_Cart_coords |
根据进程号返回笛卡尔坐标 |
MPI_Cart_rank |
根据笛卡尔坐标返回进程号 |
MPI_Cart_shift |
数据平移 |
MPI_Cart_sub |
划分子拓扑 |
六、MapReduce
- 特性
- 自动实现分布式并行计算
- 容错
- 提供状态监控工具
- 模型抽象简洁,程序员易用
编程模型
- 使用函数式编程模型。用户只需要实现两个接口:
map和reduce map:(in_key, in_value) -> (out_key, intermediate_value) listreduce:(out_key, intermediate_value list) -> out_value list
- 使用函数式编程模型。用户只需要实现两个接口:
refer to: MapReduce技术的初步了解与学习
七、PCAM并行程序设计方法学
例子:求前缀和
PCAM步骤: 划分→通讯→组合→映射
划分:分解成小的任务,开拓并发性。
- 先进行域分解,再进行功能分解
- 域分解:划分的对象为数据。可以是算法的输入数据、中间处理数据和输出数据。将数据分解成大致相等的小数据片。 → 如果一个任务需要别的任务中的数据,则会产生任务间的通讯。
- 功能分解:划分的对象为计算。划分后,如果不同任务所需数据不想交则划分成功;如果数据有相当的重叠,则需要重新进行域分解和功能分解。
通讯:确定诸任务间的数据交换,检测划分的合理性。
- 划分产生的诸任务,一般不能完全独立执行,需要在任务间进行数据交流,从而产生了通讯。
- 功能分解确定了诸任务之间的数据流
- 诸任务是并发执行的,通讯限制了这种并发性
- 四种通讯模式
- 局部/全局通讯:局部通讯限制在一个邻域内,全局通讯则是非局部的。
- 结构化/非结构化通讯:结构化通讯下每个任务的通讯模式是相同的
- 静态/动态通讯
- 同步/异步通讯
- 组合:依据任务的局部性,组合成更大的任务。
- 合并小尺寸任务,减少任务数。如果任务数恰好等于处理器数,则也完成了映射过程。
- 通过增加任务的粒度和重复计算,可以减少通讯成本。
- 保持映射和扩展的灵活性,降低软件工程成本。
- 表面-容积效应:通讯量和任务子集的表面成正比,计算量和任务子集的体积成正比。增加重复计算有可能减少通讯量 → 重复计算减少了通讯量,但增加了计算量,应保持恰当的平衡,重复计算的目标应当是减少算法的总运算时间。(实例:二叉树求和,碟式结构使用了重复计算,但减少了总时间)
- 映射:将每个任务分配到处理器上,提高算法的性能。
- 每个任务要映射到具体的处理器,定位到运行机器上。
- 任务数大于处理器数时,存在负载均衡和任务调度问题。
- 映射的目标:减少算法的总执行时间
- 基本原则:并发的任务映射到不同的处理器上,存在高通讯的任务则尽量映射到相同的处理器上。
- NPC
- 负载均衡算法?
- 静态的:事先确定
- 概率的:随机确定
- 动态的:执行期间动态负载
- 基于域分解的:
- 递归对剖
- 局部算法
- 概率方法
- 循环映射
- 两种常用的任务调度算法
- 经理/雇员模式
- 非集中模式
OpenMP只需要知道基本的概念和能干什么即可,不用掌握编译制导语句
MPI需要掌握,重点
MapReduce:word count & 倒排索引 要搞清楚,词共现等不需要