HDFS的诞生
点击上方“程序员小灰”,选择“置顶公众号”
有趣有内涵的文章第一时间送达!
本文转载自公众号 码农翻身
1牛刀小试
张大胖找了个实习的工作, 第一天上班Bill师傅给他分了个活儿:日志分析。
张大胖拿到了师傅给的日志文件,大概有几十兆,打开一看, 每一行都长得差不多,类似这样:
212.86.142.33 – - [20/Mar/2017:10:21:41 +0800] “GET / HTTP/1.1″ 200 986 “http://www.baidu.com/” “Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; )"
张大胖知道,这些日志都是Web服务器产生的,里边包含了像客户端IP, 访问时间, 请求的URL,请求处理的状态, referer, User Agent等信息。
师傅说,你想个办法统计一天之内每个页面的访问量(PV),独立的IP数, 还有用户最喜欢搜索的前10个关键字。
张大胖心说这简单啊,我用Linux上的cat,awk等小工具就能做出来, 不过还是正式一点,用我最喜欢的Python写个程序吧,把每一行文本分割成一个个字段,然后分分组、计算一下不就得了。
慢着, 这样一来这个程序就只能干这些事儿,不太灵活,扩展性不太好。
要不把分割好的字段写入数据库表?
比如access_log(id,ip,timestamp,url, status,referer, user_agent), 这样就能利用数据库的group 功能和count功能了,sql多强大啊, 想怎么处理就怎么处理。
对,就这么办!
半天以后,张大胖就把这个程序给搞定了,还画了一个架构图,展示给了师傅。
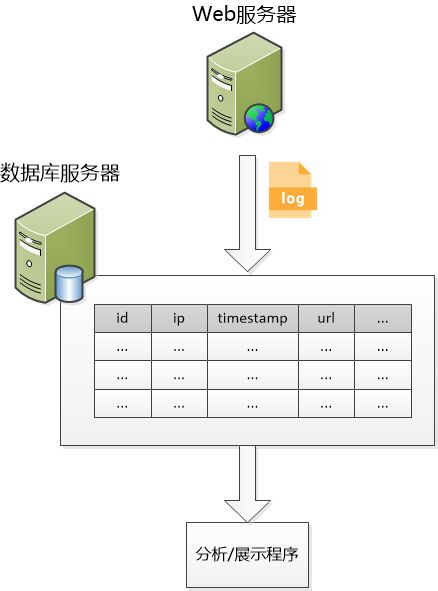
师傅一看:“不错嘛,思路很清晰,还考虑到了扩展性,可以应对以后更多的需求。”
于是这个小工具就这么用了起来。
张大胖毕业以后也顺利地加入了这家公司。
互联网尤其是移动互联网发展得极快,公司网站的用户量暴增,访问量也水涨船高,日志量也很感人,每小时都能产生好几个G,张大胖实习期间“引以为傲”的小程序没法再用了,数据库根本就放不下啊。
不仅数据库放不下,在Web服务器上也放不下了,更不用说去做分析了。
张大胖主动请缨,打算搞定这个问题。 当然他也很聪明地把经验丰富的师傅Bill给拉上了。
两个人来到会议室,开始了讨论。
张大胖先算了一笔账:如果是一台机器,一个硬盘,读取速度是75M/s ,那需要花费10多天才能读取100T的内容。 但是如果是有100个硬盘, 并行的读取速度就能达到75G/s , 几十分钟就可以把100T的数据给读出来了,多快啊。
他对Bill说道:“看来只有分布式存储才能拯救了。多来几台机器吧,把log1, log2,log3...这些文件存放在不同的机器上。”
师傅Bill说道:“你想得太简单了,分布式可不是简单地添加机器, 机器的硬盘坏了怎么办?日志文件是不是就丢失了? 热门文件怎么办? 访问量特别大,那对应的机器负载就特别高, 这样不公平啊!
张大胖说道:“第一个问题好办,我可以做备份啊,把每个文件都存三个备份。这样坏的可能性就大大降低了。你说的第二个问题,我们的日志哪有什么热门文件?”
“要考虑下通用性嘛!将来你这个分布式的文件系统可以处理别的东西啊。”
“好吧, 我可以被文件切成小块,让他们分散在各个机器上,这就行了吧。 备份的时候,把每个小块都备份三份就解决问题了。”

(备注:三份是最低要求)
“那问题就来了,我们该怎么使用呢? 客户端总不能说把文件的第一块从服务器1上取出来,第二块从服务器4上取出来,第三块从服务器2上取出来..... 再说客户端保留这些‘乱七八糟’的信息该多烦人啊。” Bill提出的问题很致命。
“这个......” 张大胖思考了半天, “看来还得做抽象啊,我的分布式文件系统得提供一个抽象层,让文件分块对客户端保持透明, 客户端根本不必知道文件是怎么分块的,分块后存放在什么服务器上。他们只需要知道一个文件的路径/logs/log1,就可以读写了,细节不用操心。”
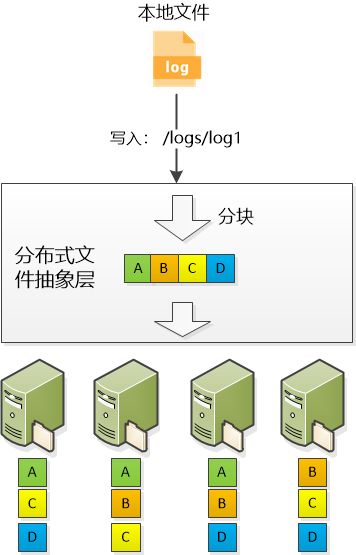
“不错,看来你已经Get到了,一定要通过抽象给客户端提供一个简单的视图,尽可能让他们像访问本地文件一样来使用!” Bill 立刻做了升华。
“不过,”张大胖突然想到一个问题,“这样的分布式文件系统似乎只适合在文件末尾不断地对追加内容,如果是想随机地读写,比如定位到某个位置,然后写入新的数据,就很麻烦了。”
“这也没办法,事物总是有利有弊,现在的系统就是适合一次写入,多次读取的场景。”
“不过, ”Bill 接着说,“文件被分成了哪些块,这些块都放在什么服务器上,系统有哪些服务器,服务器上都多大空间,这些都是Metadata, 你得专门找个服务器存储起来,我们把这个服务器叫做Metadata节点如何?或者简单一点,叫做NameNode吧!类似于整个系统的大管家。 ”
“好, 我们把那些储存数据的服务器叫做Data节点(DataNode)吧,这样就区分开了。我可以写一个客户端让大家使用,这个客户端通过查询NameNode,定位到文件的分块和存储位置,这样大家就可以读写了!”
Bill在白板上画了一张图,展示了当前的设计:
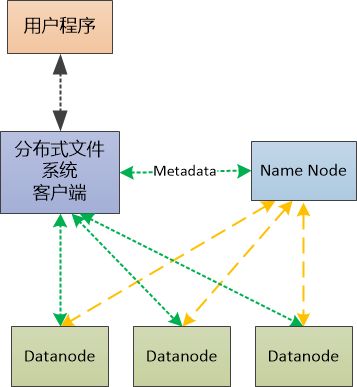
“绿色虚线的意思是数据的读写流, 对吧, 但是橙色的虚线是什么鬼?” 张大胖问道。
“你想想这么一种情况,如果某个Datanode 的机器挂掉了,它上面的所有文件分块都无法读写了,这时候Namenode如何才能知道呢? 还有,如果某个Datanode所在机器的磁盘空间不足了,是不是也得让Namenode这个大管家知道?”
“奥,Datanode和Namenode 之间需要定期的通信, 这就麻烦了,我还得特别为他们设计一个通信协议啊!” 张大胖有点沮丧。
“分布式系统就是这样,有很多挑战,机器坏掉,网络断掉..... 你想在普通的、廉价的机器上实现高可靠性是很难的一件事情。”
4读取文件“我们再细化下读写的流程吧?” Bill 提议。
“我觉得挺简单啊,比如去读取一个文件,客户端只需把文件名告诉Namenode, 让Namenode把所有数据都返回不就行了?这样客户端对Datanode保持透明,不错吧!”
Bill严肃地摇了摇头:“不行, 如果所有的数据流都经过Namenode, 它会成为瓶颈的! 无法支持多个客户端的并发访问, 记住,我们要处理的可是TB, 乃至PB级别的数据啊。”
“对对,我没有深入考虑啊!” 张大胖感慨姜还是老的辣,赶紧换个思路, “要不这样,读取文件的时候,Namenode只返回文件的分块以及该分块所在的Datanode列表, 这样我们的客户端就可以选择一个Datanode来读取文件了。”
“但是一个分块有3个备份,到底选哪个? ” Bill问道
“肯定是最近的那个了,嗯,怎么定义远近呢?” 张大胖犯难了。
“我们可以定义一个‘距离’的概念。 ” Bill 说道。
客户端和Datanode是同一个机器 : 距离为0 ,表示最近
客户端和Datanode是同一个机架的不同机器 : 距离为2 ,稍微远一点
客户端和Datanode位于同一个数据中心的不同机架上 : 距离为4, 更远一点
“没想到分布式系统这么难搞,比我实习做的那个程序难度提高了好几个数量级!”
话虽这么说,张大胖还是画了一个读取文件的流程图:
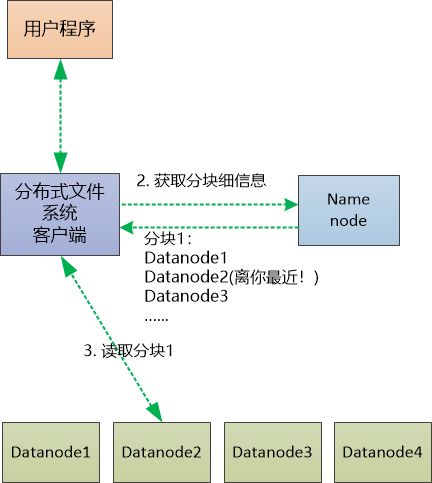
(注:图中只画出了一个分块的读取,对文件其他分块的读取还会持续进行)
5写入文件“写入文件也类似,” 张大胖打算趁热打铁,“让Namenode 找到可以写数据的三个Datanode,返回给我们的客户端,客户端就可以向这三个Datanode 发起写的操作了!”
“假设你有个10G的文件,难道让客户端向Datanode写入3次,使用30G的流量吗?” Bill马上提了一个关键的问题。
“不这么做还能怎么办? 我们要保存多个备份啊!”
“有个解决办法,我们可以把三个Datanode 组成一个Pipline(管道), 我们只把数据发给第一个Datanode, 让数据在这个管道内‘流动’起来, 第一个Datanode发个备份给第二个, 第二个发同样的备份给第三个。”
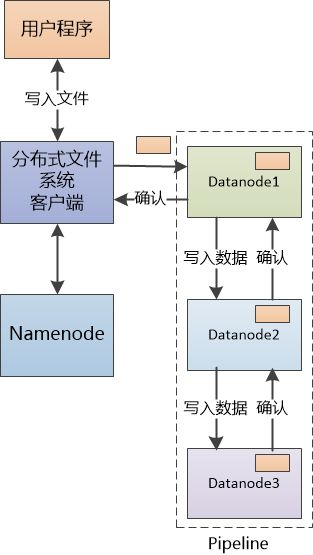
(注:实际的文件写入比较复杂,有更多细节, 这里只是重点展示pipeline)
“有点意思,客户端只发出一次写的请求,数据的复制由我们的Datanode合作搞定。” 张大胖深为佩服,师傅Bill的脑子就是好使啊。
“还有啊,”Bill说道,“咱们的设计中Namenode这个大管家有单点失败的风险,我们最好还是做一个备份的节点。”
张大胖深表赞同。
“我们给这个系统起个名字吧?叫Distrubted File System(简称DFS)怎么样?” 张大胖说。
“俗,太俗,叫Hadoop吧,这是我儿子玩具象的名称。嗯,还是叫Hadoop Distributed File System, HDFS。” Bill 的提议出乎张大胖意料。
“行吧,我们有了HDFS,可以存储海量的日志了,我就可以写个程序,去读取这些文件,统计各种各样的用户访问了。”
“你打算把你的程序放到哪里?”
“自然是放在HDFS之外的某个机器上,然后通过HDFS 客户端去访问数据啊!”
“100T的数据从HDFS的众多机器中读取出来,在一台机器上处理? 这得多慢啊! 我们要考虑把计算也做成分布式的,并且让计算程序尽可能地靠近数据,这样就快了!”
“分布式计算?”
“没错,听说过Mapreduce 没有?”
张大胖摇了摇头:“这是什么鬼?”
“我们下次再聊吧!”
后记:这篇文章介绍了HDFS的一些关键设计理念,已经属于非常简化的情况了,没有考虑数据的完整性,节点失效等更多细节。
—————END—————
喜欢本文的朋友们,欢迎长按下图关注订阅号程序员小灰,收看更多精彩内容
