带你理解CycleGAN,并用TensorFlow轻松实现
把一张图像的特征转移到另一张图像,是个非常一颗赛艇的想法。把照片瞬间变成梵高、毕加索画作风格,想想就很酷。

图1:星空版小狗
文末有风格迁移小demo
或者,你可以用目前很流行的Faceapp让下面这位严肃的大叔露出笑容

图2:一个笑容灿烂的杀手
要实现这样的图像风格转换,通常需要一个包含成对图片的训练集。CycleGAN打破了这个限制。CycleGAN是加州大学伯克利分校的一项研究成果,可以在没有成对训练数据的情况下,实现图像风格的转换。
以下是CycleGAN完成的一些例子:

图3:CycleGAN实现的一些例子
详情见CycleGAN的论文
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks:
https://arxiv.org/abs/1703.10593
如果你觉得论文读起来太枯燥,那么,最近GitHub上发布的一份教程可能比较适合你,作者Hardik Bansal和Archit Rathore。
以下是这份教程对CycleGAN的解读:量子位编译:
简介
如果你对生成对抗网络(GAN)还不太了解,可以查看Ian Goodfellow在NIPS 2016的研讨会视频,地址见文末。
这篇文章是一份简化版教程,将带你了解CycleGAN的核心理念,并介绍如何在Tensorflow中实现CycleGAN网络。
非配对的图像到图像转换
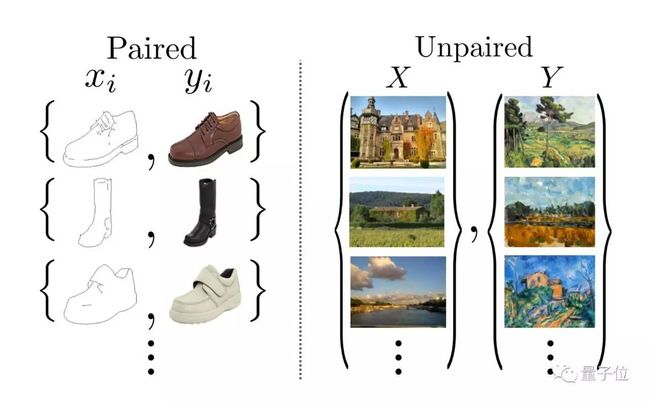
图4:配对与非配对图像转换(图来自论文)
上面也提到过,无须提供从源域到目标域的配对转换例子,CycleGAN就能工作。
最近提出的Pix to Pix方法的关键是提供了在这两个域中有相同数据的训练样本。CycleGAN的创新点在于能够在源域和目标域之间,无须建立训练数据间一对一的映射,就可实现这种迁移。
这种方法通过对源域图像进行两步变换:首先尝试将其映射到目标域,然后返回源域得到二次生成图像,从而消除了在目标域中图像配对的要求。使用生成器(generator)网络将图像映射到目标域,并且通过匹配生成器与鉴别器(discriminator),能提高该生成图像的质量。
对抗网络
我们使用了一个生成器网络和一个鉴别器网络,进行相互对抗。生成器尝试从期望分布中产生样本,鉴别器试图预测样本是否为原始图像或生成图像。
利用生成器和鉴别器联合训练,最终生成器学习后完全逼近实际分布,并且鉴别器处于随机猜测状态。
循环一致
上述对抗方法的训练存在一个问题。引用原文的一段话:
从理论上讲,对抗训练可以学习和产生与目标域Y和X相同分布的输出,即映射G和F。然而,在足够大的样本容量下,网络可以将相同的输入图像集合映射到目标域中图像的任何随机排列,其中任何学习的映射可以归纳出与目标分布匹配的输出分布。因此,单独的对抗损失Loss不能保证学习函数可以将单个输入Xi映射到期望的输出Yi。
为了规范模型,作者介绍了循环一致性的约束条件:如果我们从源分布转换为目标分布,然后再次转换回源分布,那么应该可以从源分布中获取样本。
网络架构
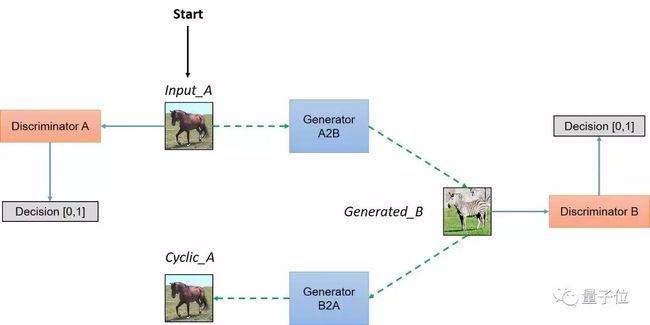
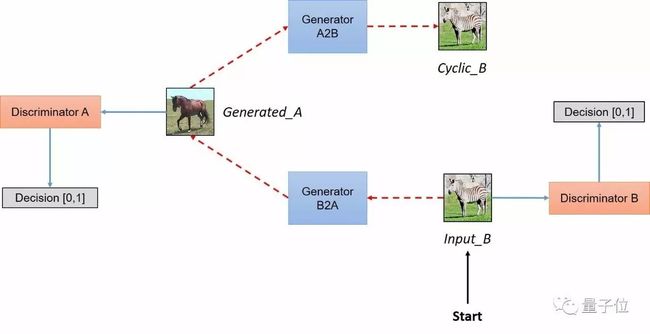
图5:CycleGAN结构示意图
在一个配对数据集中,每张图像,如imgA,人为地映射到目标域中的某个图像,如imgB,以便两者共享各种特征。
从imgA到imgB的特征可用于其相对应的映射过程中,即从imgB到imgA的特征。配对一般是为了使输入和输出共享一些共同的特征。当一张图像从一个域到另一个域时,该映射定义了一种有意义的变换。因此,当我们配对数据集时,生成器必须从域DA中获得一个输入,例如inputA,并将该图像映射到输出图像,即genB,原始图像必须与其映射对象相近。
但是,我们在不配对的数据集中没有这个对象,也没有预先定义好的用于学习的有意义转换,所以我们将要创建它。我们需要确保输入图像和生成图像之间存在一些有意义的关联。
所以,作者试图通过生成器将输入图像(inputA)从域DA映射到目标域DB中,转换成对应图像。但是为了确保这些图像之间存在有意义的关系,它们必须共享一些特征,这些特征可用于将此输出图像映射回输入图像,因此必须有另一个生成器能将此输出图像映射回原始域。因此,我们需要定义inputA和genB之间有意义的映射。
简而言之,该模型通过从域DA获取输入图像,该输入图像被传递到第一个生成器GeneratorA→B,其任务是将来自域DA的给定图像转换到目标域DB中的图像。然后这个新生成的图像被传递到另一个生成器GeneratorB→A,其任务是在原始域DA转换回图像CyclicA,这里可与自动编码器作对比。
正如上面讨论的,这个输出图像必须与原始输入图像相似,用来定义非配对数据集中原来不存在的有意义映射。
如图5所示,两个输入被传递到对应的鉴别器(一个是对应于该域的原始图像,另一个是通过生成器产生的图像),并且鉴别器的任务是区分它们,识别出生成器输出的生成图像,并拒绝此生成图像。生成器想要确保这些图像被鉴别器接受,所以它将尝试生成与DB类中原始图像非常接近的新图像。事实上,在生成器分布与所需分布相同时,生成器和鉴别器之间实现了纳什均衡(Nash equilibrium)。
我们可以通过TensorFlow轻松实现CycleGAN,下面将介绍CycleGAN各部分的实现细节,可在GitHub上找到完整代码。
构建生成器
生成器的结构已在下图列出。
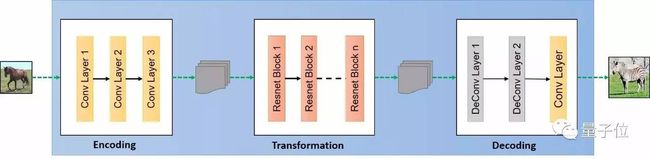
图6:生成器结构
生成器由三个部分组成:编码器、转换器和解码器。
该生成器的超参数定义如下,包括卷积核个数、批数量、池化大小和输入图像的格式:
ngf = 32# Number of filters in first layer of generatorndf = 64# Number of filters in first layer of discriminatorbatch_size = 1# batch_sizepool_size = 50# pool_sizeimg_width = 256# Imput image will of width 256img_height = 256# Input image will be of height 256img_depth = 3# RGB format
前三个参数简单易懂,我们将在生成图像库部分中解释pool_size的含义。
编码
为了简单起见,在此文章中我们把输入大小固定设置为[256,256,3]。第一步是利用卷积网络从输入图像中提取特征。要了解有关卷积网络的基础知识,你可以查看文末的CNN介绍链接。卷积网络将一张图像作为输入,不同大小的卷积核能在输入图像上移动并提取特征,步幅(stride)大小能决定在图像中卷积核窗口的数量。所以编码器的第一层定义如下:
o_c1 = general_conv2d(input_gen, num_features=ngf, window_width= 7, window_height= 7, stride_width= 1, stride_height= 1)
其中,input_gen是生成器的输入图像,num_features是在卷积层中卷积得到的特征图谱数量,也可以看作是提取不同特征的滤波器数量。window_width和window_height表示在输入图像上滑动来提取特征的滤波器窗口大小。类似地,stride_width和stride_height定义了每次迭代后滤波器的移位方式。输出Oc1是尺寸为[256,256,64]的张量,继续传输给下个卷积层。这里,鉴别器第一层的滤波器个数设置为64,完成对general_conv2d函数的定义。当然可以添加其他层,如ReLU层或批归一化层(BN层),在本教程中跳过这些层的介绍。
defgeneral_conv2d(inputconv, o_d=64, f_h=7, f_w=7, s_h=1, s_w=1):withtf.variable_scope(name): conv = tf.contrib.layers.conv2d(inputconv, num_features, [window_width, window_height], [stride_width, stride_height], padding, activation_fn= None, weights_initializer=tf.truncated_normal_initializer(stddev=stddev), biases_initializer=tf.constant_initializer( 0.0))
接下来:
o_c2 = general_conv2d(o_c1, num_features= 64* 2, window_width= 3, window_height= 3, stride_width= 2, stride_height= 2) # o_c2.shape = (128, 128, 128)o_enc_A = general_conv2d(o_c2, num_features= 64* 4, window_width= 3, window_height= 3, stride_width= 2, stride_height= 2) # o_enc_A.shape = (64, 64, 256)
卷积层越往上,需要增加高层特征的数量。我们将图像压缩成256个尺寸大小64×64的特征向量,接着将DA域中图像的特征向量转换为DB域中图像的特征向量。
总而言之,我们将DA域中一个尺寸为[256,256,3]的图像,输入到设计的编码器中,获得了尺寸为[64,64,256]的输出OAenc。
转换
这些网络层的作用是组合图像的不同相近特征,然后基于这些特征,确定如何将图像的特征向量OAenc从DA域转换为DB域的特征向量。因此,作者使用了6层Resnet模块:
o_r1 = build_resnet_block(o_enc_A, num_features= 64* 4)o_r2 = build_resnet_block(o_r1, num_features= 64* 4)o_r3 = build_resnet_block(o_r2, num_features= 64* 4)o_r4 = build_resnet_block(o_r3, num_features= 64* 4)o_r5 = build_resnet_block(o_r4, num_features= 64* 4)o_enc_B = build_resnet_block(o_r5, num_features= 64* 4) # o_enc_B.shape = (64, 64, 256)
这里OBenc表示该层的最终输出,尺寸为[64,64,256],这可以看作是DB域中图像的特征向量。
你一定很想知道build_resnet_block函数的内容及作用。build_resnet_block是一个由两个卷积层组成的神经网络层,其中部分输入数据直接添加到输出。这样做是为了确保先前网络层的输入数据信息直接作用于后面的网络层,使得相应输出与原始输入的偏差缩小,否则原始图像的特征将不会保留在输出中且输出结果会偏离目标轮廓。在上面也提到,这个任务的一个主要目标是保留原始图像的特征,如目标的大小和形状,因此残差网络非常适合完成这些转换。Resnet模块的结构如下所示:
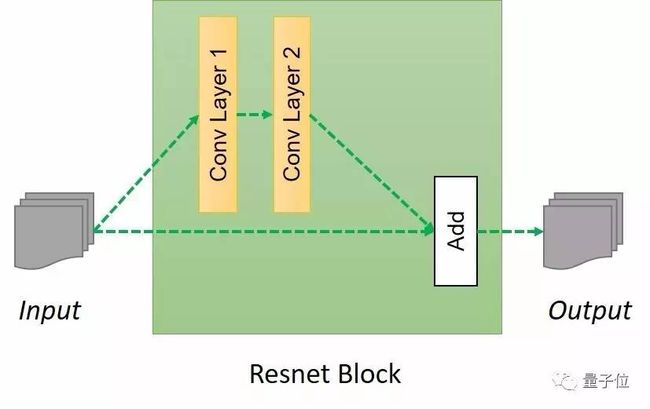
图7:Resnet模块的结构
Resnet模块的代码如下:
defresnet_blocks(input_res, num_features):out_res_1 = general_conv2d(input_res, num_features, window_width= 3, window_heigth= 3, stride_width= 1, stride_heigth= 1) out_res_2 = general_conv2d(out_res_1, num_features, window_width= 3, window_heigth= 3, stride_width= 1, stride_heigth= 1) return(out_res_2 + input_res) 解码
到目前为止,我们已经将特征向量OAenc传递到转换层,得到了另一个大小为[64,64,256]的特征向量OBenc。
解码过程与编码方式完全相反,从特征向量中还原出低级特征,这是利用了反卷积层(deconvolution)来完成的。
o_d1 = general_deconv2d(o_enc_B, num_features=ngf* 2window_width= 3, window_height= 3, stride_width= 2, stride_height= 2)o_d2 = general_deconv2d(o_d1, num_features=ngf, window_width= 3, window_height= 3, stride_width= 2, stride_height= 2)
最后,我们将这些低级特征转换得到一张在DB域中的图像,代码如下所示:
gen_B = general_conv2d(o_d2, num_features= 3, window_width= 7, window_height= 7, stride_width= 1, stride_height= 1)
最后,我们得到了一个大小为[256,256,3]的生成图像genB,构建生成器的代码可以用如下函数实现:
defbuild_generator(input_gen):o_c1 = general_conv2d(input_gen, num_features=ngf, window_width= 7, window_height= 7, stride_width= 1, stride_height= 1) o_c2 = general_conv2d(o_c1, num_features=ngf* 2, window_width= 3, window_height= 3, stride_width= 2, stride_height= 2) o_enc_A = general_conv2d(o_c2, num_features=ngf* 4, window_width= 3, window_height= 3, stride_width= 2, stride_height= 2) # Transformationo_r1 = build_resnet_block(o_enc_A, num_features= 64* 4) o_r2 = build_resnet_block(o_r1, num_features= 64* 4) o_r3 = build_resnet_block(o_r2, num_features= 64* 4) o_r4 = build_resnet_block(o_r3, num_features= 64* 4) o_r5 = build_resnet_block(o_r4, num_features= 64* 4) o_enc_B = build_resnet_block(o_r5, num_features= 64* 4) #Decodingo_d1 = general_deconv2d(o_enc_B, num_features=ngf* 2window_width= 3, window_height= 3, stride_width= 2, stride_height= 2) o_d2 = general_deconv2d(o_d1, num_features=ngf, window_width= 3, window_height= 3, stride_width= 2, stride_height= 2) gen_B = general_conv2d(o_d2, num_features= 3, window_width= 7, window_height= 7, stride_width= 1, stride_height= 1) returngen_B 构建鉴别器
我们讨论了如何构建生成器,但是为了完成网络的对抗训练部分,还需要构建鉴别器。鉴别器将一张图像作为输入,并尝试预测其为原始图像或是生成器的输出图像。生成器的结构如下所示:
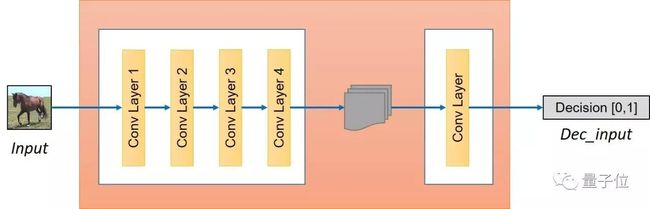
图8:生成器的结构
鉴别器本身就属于卷积网络,需要从图像中提取特征。
o_c1 = general_conv2d(input_disc, ndf, f, f, 2, 2)o_c2 = general_conv2d(o_c1, ndf* 2, f, f, 2, 2)o_enc_A = general_conv2d(o_c2, ndf* 4, f, f, 2, 2)o_c4 = general_conv2d(o_enc_A, ndf* 8, f, f, 2, 2)
下一步是确定这些特征是否属于该特定类别,添加一个产生1维输出的卷积层来完成这个任务。这里,ndf表示鉴别器初始层的特征个数,可以尝试调整来获得最佳效果。
decision = general_conv2d(o_c4, 1, f, f, 1, 1, 0.02)
我们已经完成该模型的两个主要组成部分,即生成器和鉴别器。由于要使这个模型既可以从A→B和B→A两个方向工作,我们设置了两个生成器,即生成器A→B和生成器B→A,以及两个鉴别器,即鉴别器A和鉴别器B。
建立模型
在定义损失函数前,先定义基础输入变量,来构建模型。
input_A = tf.placeholder(tf.float32, [batch_size, img_width, img_height, img_layer], name= "input_A")input_B = tf.placeholder(tf.float32, [batch_size, img_width, img_height, img_layer], name= "input_B")
这些占位符将作为输入,同时定义模型如下:
gen_B = build_generator(input_A, name= "generator_AtoB")gen_A = build_generator(input_B, name= "generator_BtoA")dec_A = build_discriminator(input_A, name= "discriminator_A")dec_B = build_discriminator(input_B, name= "discriminator_B")dec_gen_A = build_discriminator(gen_A, "discriminator_A")dec_gen_B = build_discriminator(gen_B, "discriminator_B")cyc_A = build_generator(gen_B, "generator_BtoA")cyc_B = build_generator(gen_A, "generator_AtoB")
上面的变量名在本质上是非常直观的。gen表示使用相应的生成器后生成的图像,dec表示在将相应输入传递到鉴别器后做出的判断。
损失函数
现在我们有两个生成器和两个鉴别器。我们要按照实际目的来设计损失函数。损失函数应该包括如下四个部分:
-
鉴别器必须允许所有相应类别的原始图像,即对应输出置1;
-
鉴别器必须拒绝所有想要愚弄过关的生成图像,即对应输出置0;
-
生成器必须使鉴别器允许通过所有的生成图像,来实现愚弄操作;
-
所生成的图像必须保留有原始图像的特性,所以如果我们使用生成器GeneratorA→B生成一张假图像,那么要能够使用另一个生成器GeneratorB→A来努力恢复成原始图像。此过程必须满足循环一致性。
鉴别器损失
第1部分
我们通过训练鉴别器,使其对A类图像的输出接近于1,鉴别器B也是如此。鉴别器A的训练目标为最小化“(DiscriminatorA(a)−1)2”的值,鉴别器B也是如此。对应代码如下:
D_A_loss_1 = tf.reduce_mean(tf.squared_difference(dec_A, 1))D_B_loss_1 = tf.reduce_mean(tf.squared_difference(dec_B, 1))
第2部分
由于鉴别器应该能够区分生成图像和原始图像,所以在处理生成图像时期望输出为0,即鉴别器A要最小化“(DiscriminatorA(GeneratorB→A(b)))2”的值。对应代码如下:
D_A_loss_2 = tf.reduce_mean(tf.square(dec_gen_A))D_B_loss_2 = tf.reduce_mean(tf.square(dec_gen_B))D_A_loss = (D_A_loss_1 + D_A_loss_2)/ 2D_B_loss = (D_B_loss_1 + D_B_loss_2)/ 2
生成器损失
最终生成器应该能够提高鉴别器对生成图像的输出值。如果鉴别器对生成图像的输出值尽可能接近1,则生成器的作用达到。故生成器想要最小化“(DiscriminatorB(GeneratorA→B(a))−1)2”,因此损失为:
g_loss_B_1 = tf.reduce_mean(tf.squared_difference(dec_gen_A, 1))g_loss_A_1 = tf.reduce_mean(tf.squared_difference(dec_gen_A, 1))
循环损失
最后一个重要参数为循环丢失(cyclic loss),能判断用另一个生成器得到的生成图像与原始图像的差别。因此原始图像和循环图像之间的差异应该尽可能小。
cyc_loss = tf.reduce_mean(tf.abs(input_A-cyc_A)) + tf.reduce_mean(tf.abs(input_B-cyc_B))
所以完整的生成器损失为:
g_loss_A = g_loss_A_1 + 10*cyc_lossg_loss_B = g_loss_B_1 + 10*cyc_loss
cyc_loss的乘法因子设置为10,说明循环损失比鉴别损失更重要。
混合参数
定义好损失函数,接下来只需要训练模型来最小化损失函数。
d_A_trainer = optimizer.minimize(d_loss_A, var_list=d_A_vars)d_B_trainer = optimizer.minimize(d_loss_B, var_list=d_B_vars)g_A_trainer = optimizer.minimize(g_loss_A, var_list=g_A_vars)g_B_trainer = optimizer.minimize(g_loss_B, var_list=g_B_vars) 训练模型 forepoch inrange( 0, 100): # Define the learning rate schedule. The learning rate is kept# constant upto 100 epochs and then slowly decayedif(epoch < 100) : curr_lr = 0.0002else: curr_lr = 0.0002- 0.0002*(epoch- 100)/ 100# Running the training loop for all batchesforptr inrange( 0,num_images): # Train generator G_A->B_, gen_B_temp = sess.run([g_A_trainer, gen_B], feed_dict={input_A:A_input[ptr], input_B:B_input[ptr], lr:curr_lr}) # We need gen_B_temp because to calculate the error in training D_B_ = sess.run([d_B_trainer], feed_dict={input_A:A_input[ptr], input_B:B_input[ptr], lr:curr_lr}) # Same for G_B->A and D_A as follow_, gen_A_temp = sess.run([g_B_trainer, gen_A], feed_dict={input_A:A_input[ptr], input_B:B_input[ptr], lr:curr_lr}) _ = sess.run([d_A_trainer], feed_dict={input_A:A_input[ptr], input_B:B_input[ptr], lr:curr_lr})
你可以在训练函数中看到,在训练时需要不断调用不同鉴别器和生成器。为了训练模型,需要输入训练图像和选择优化器的学习率。由于batch_size设置为1,所以num_batches等于num_images。
我们已经完成了模型构建,下面是模型中一些默认超参数。
生成图像库
计算每个生成图像的鉴别器损失是不可能的,因为会耗费大量的计算资源。为了加快训练,我们存储了之前每个域的所有生成图像,并且每次仅使用一张图像来计算误差。首先,逐个填充图像库使其完整,然后随机将某个库中的图像替换为最新的生成图像,并使用这个替换图像来作为该步的训练。
defimage_pool(self, num_gen, gen_img, gen_pool):if(num_gen < pool_size): gen_img_pool[num_gen] = gen_img returngen_img else: p = random.random() ifp > 0.5: # Randomly selecting an id to return for calculating the discriminator lossrandom_id = random.randint( 0,pool_size- 1) temp = gen_img_pool[random_id] gen_pool[random_id] = gen_img returntemp else: returngen_img gen_image_pool_A = tf.placeholder(tf.float32, [batch_size, img_width, img_height, img_layer], name= "gen_img_pool_A")gen_image_pool_B = tf.placeholder(tf.float32, [batch_size, img_width, img_height, img_layer], name= "gen_img_pool_B")gen_pool_rec_A = build_gen_discriminator(gen_image_pool_A, "d_A")gen_pool_rec_B = build_gen_discriminator(gen_image_pool_B, "d_B") # Also the discriminator loss will change as followD_A_loss_2 = tf.reduce_mean(tf.square(gen_pool_rec_A))D_A_loss_2 = tf.reduce_mean(tf.square(gen_pool_rec_A))
图像库代码仍需要微小的修改,完整代码见文末。
结果
我们运行了野马转斑马的模型,但是由于缺乏图像库,该模型只运行了100步,得到以下结果。
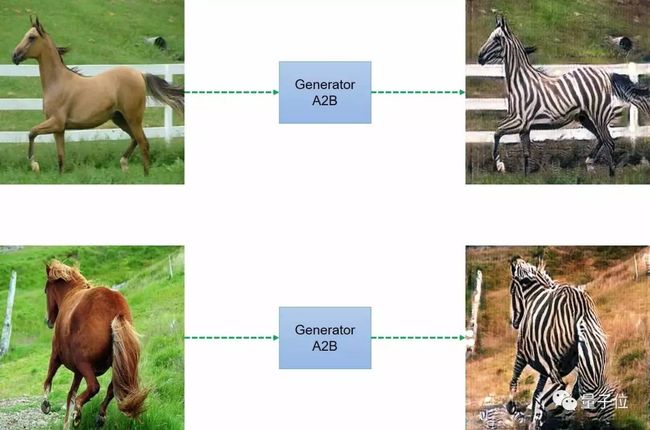
图9:野马转斑马的实际效果 讨论
1.在训练时,我们发现初始化很大程度影响了输出结果,因此通过多次训练来获得最佳效果。你会发现图10中特殊的背景颜色,这个效果只有在10-20步的训练时才能观察到,你可以再运行代码试试。

图10:该模型出现失真效果
2.我们也认为当改变物体形状时,该模型不大适用。我们试图用该模型把男人的脸转化为一个看起来像女人的脸。为此,我们使用了人脸标注数据集celebA,但效果不好且生成图像失真严重。
相关链接
卷积神经网络:https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/
CycleGAN代码:https://github.com/architrathore/CycleGAN/
风格迁移小demo:https://dmitryulyanov.github.io/feed-forward-neural-doodle/
NIPS 2016研讨会视频:https://www.youtube.com/watch?v=RvgYvHyT15E
【完】
招聘
量子位正在招募编辑记者、运营、产品等岗位,工作地点在北京中关村。相关细节,请在公众号对话界面,回复:“招聘”。