目标检测总结整理
目标检测总结整理
接触过图像处理的童鞋,对于目标检测一定不陌生吧。目标检测可一直是计算机视觉和机器学习领域的热点。这篇文章主要是依据小编自己的学习体会,对目标检测的发展历程进行了总结。最初,目标检测算法是基于传统手工特征的;大约在2013年,基于深度学习的目标检测开始逐渐火起来,基于传统的手工特征的目标检测算法被逐渐抛弃;目前随着生成式对抗网络GAN的大热,基于GAN的目标检测也开始火起来了。
基于传统手工特征的目标检测
目标检测在我看来也就是目标提取,它将目标分割与目标识别合二为一。比如,对一幅图像中的猫咪进行检测,可以分为两大步骤,第一步就是将可疑目标从原始图像分割出来;第二步就是对分割出来的目标进行识别,来确定是否是猫咪。
传统的目标检测方法如果再去细分可以分为三个步骤,如图1:
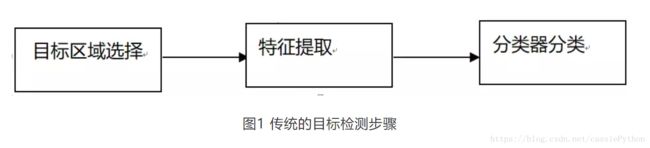
首先对处理的图像进行候选区域选择,之后对候选区域进行特征提取,最后利用分类器进行分类。下面小编将对这三个步骤进行详细的介绍。
(1) 目标区域的选择实际上是对目标的定位。由于目标可能出现在图像的任意位置,而且目标的大小也不确定,因此最初采用滑动窗口策略来遍历图像,并且对滑动窗口设置了不同的尺度以及不同的长宽比。虽然这种方法可以获得众多可疑目标区域,但是也产生了过多的冗余窗口,同时时间复杂度也高。这个方法代价太过昂贵。
(2) 特征提取实际上是对第一步获得的候选区域的分析。由于目标形态的多样性,背景的多样性,光照变化,遮挡等等问题,设计一个具有好的鲁棒性的特征是十分不容易的。这里的特征都是人为设计的,常用的方法有SIFT、HOG、SURF等等。
(3) 分类器分类。利用训练好的分类器,根据对候选区域的特征提取,我们就可以将目标检测出来了。这里常用的分类器有SVM、AdaBoost等等。
介绍到这里,大家一定很好奇,第一个传统的目标检测方法是?小编在这里告诉大家第一个传统的目标检测方法是2001年由Paul Viola和Michael Jones发表的论文《Robust Real-time Object Detection》里面提出的Viola-Jones检测框架。VJ检测器采用了最传统也是最保守的目标检测手段–滑动窗口,即在图像中的每一个尺度和每一个像素位置进行遍历,逐一判断当前窗口是否为人脸目标。这个思路看似简单,实则计算开销巨大。VJ检测之所以能够在有限的计算资源下实现实时检测,其中有三个关键要素:多尺度Haar特征的快速计算、有效的特征选择算法和高效的多阶段处理策略。
在传统的目标检测方法中,HOG行人检测器也占据一席之位。HOG特征的提出是为了解决行人检测的问题。HOG检测器是沿用了最原始的多尺度金字塔和滑动窗口的思想。为了检测不同尺寸的目标,通常会固定检测器窗口的尺寸,并逐次对图像进行缩放构建多尺度图像金字塔。为了兼顾速度和性能,HOG检测器采用的分类器通常为线性分类器或级联决策分类器。
2008年,大神Felzenszwalb在HOG检测器的基础之上提出了可变形部件模型(Deformable Part based Model,DPM),DPM是基于经典手工特征的目标检测算法发展的顶峰,连续获得VOC07、08、09三年的检测冠军。之后DPM由大神Felzenszwalb的博士生R.Girshick改进。DPM的主要思想可简单理解为将传统目标检测算法中对目标整体的检测问题拆分为对模型各个部件的检测问题,然后将各个部件的检测结果进行聚合得到最终的检测结果。DPM具体的检测过程可以参考图2。
例如,对汽车目标的检测问题可以在DPM的思想下分解为分别对车窗、车轮、车身等部件的检测问题;对行人的检测问题也可以类似地被分解为对人头、四肢、躯干等部件的检测问题。
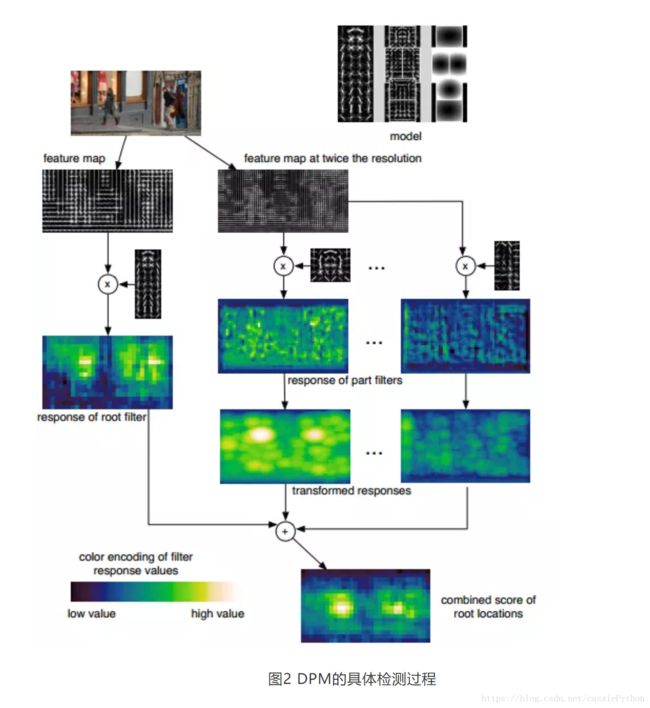
虽然近几年基于深度学习的目标检测模型从精度上来说已经远远超越了DPM,但DPM中的很多思想直到现在依然很重要,例如混合模型、难样本挖掘、包围框回归、上下文信息的利用等等。
虽然,基于传统的手工特征的目标检测方法很成熟了,但是传统的目标检测方法依旧面临着以下两个问题:一是基于滑动窗口的区域选择策略,容易产生窗口冗余;二是手工设计的特征对于目标多样性的问题并没有好的鲁棒性。
基于深度学习的目标检测
对于传统的目标检测面临问题,随着深度学习的崛起,已经很好地被解决了。对于滑动窗口的问题,Region Proposal提供了一个很好的解决方案。Region Proposal是预先在图像中找到目标可能出现的位置。由于 Region Proposal是利用了图像的纹理、边缘、颜色等等信息,可以保证在选取较少窗口的前提下,获得较高的召回率。这样就减少了计算开销,并且获得的候选区域比滑动窗口的质量远远高的多。基于这个思想的目标检测模型最耳熟能详的便是R-CNN系列的目标检测模型。
对于基于深度学习的目标检测模型,最早的模型是在2013年由纽约大学提出的OverFeat模型,改模型使用卷积神经网络(CNNs)来处理多尺度滑窗口。
OverFeat模型提出后不久,加州大学伯克利分校的Ross Girshick及其同事就发表了《Regions with CNN features》,简称R-CNN,该方法在目标识别挑战中有50%的效果提升。R-CNN方法过程如图3,主要包括三个阶段:
(1)使用Selective Search方法提取可能的目标;
(2)使用CNN对每个区域提取特征;
(3)使用SVM分类每个区域。

R-CNN被提出的一年后,Ross Girshick又发表了Fast R-CNN。和R-CNN类似,Fast R-CNN依然采用Selective Search生成候选区域,但是和R-CNN的分别提取出所有的候选区域然后使用SVM分类不同,Fast R-CNN 在完整的图片上使用CNN然后使用集中了特征映射的兴趣区域(Region of Interest, RoI),以及前向传播网络进行分类和回归。这个方法不仅更快,而且有RoI集中层和全连接层,使得模型从头到尾可求导,更容易训练。
在2015年,Shaoqing Ren、Kaiming He以及Girshick等人又提出了Fast R-CNN的升级版本Faster-RCNN算法。Faster-RCNN是第一个真正意义上的端到端的深度学习检测算法,也是第一个准实时的深度学习目标检测算法。Faster-RCNN最大的创新点在于设计了候选区域生成网络(Region Proposal Network,RPN),并设计了anchor的机制。从R-CNN到Fast RCNN再到Faster-RCNN,候选区域生成,特征提取,候选目标确认和边界框坐标回归被逐渐统一到同一个网络框架之中。
R-CNN系列的目标检测方法是基于区域建议的,同样都是基于深度学习的目标检测方法,另一个发展支线是基于回归的目标检测方法。同在2015 年,华盛顿大学的 Joseph Redmon 等人提出的 YOLO 算法就是继承了 OverFeat 算法的基于回归的 one stage 方法思想。它的核心思想就是利用整张图作为网络的输入,直接在输出层回归 bounding box(边界框) 的位置及其所属的类别。之后YOLO经过 Joseph Redmon 等人的改进,YOLOv2 和 YOLO9000 算法在 2017 年 CVPR 上被提出。
针对 YOLO 系列算法的定位精度问题,2016 年 ,Wei Liu 等人提出了 SSD 算法,将 YOLO 的回归思想和 Faster R-CNN 的 anchor box 机制结合。SSD的网络结构如图4:
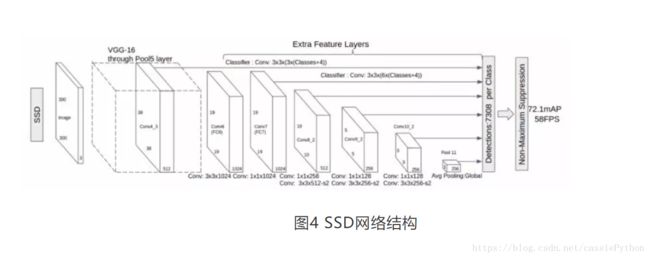
SSD采用金字塔状的网络结构,在不同卷积层上输出不同尺寸的特征图,并在这些不同尺寸的特征图上预测目标区域,输出离散化的多尺度、多比例的 default boxes 坐标。但是由于SSD利用多层次特征分类,导致其对于小目标检测困难。例如,在一幅图像中绵羊的大约是30*30,但是在经过Conv8_2层之后,绵羊大约只有1*1,对于更小的目标,目标的细节表示将会在Conv7层之后缺失。为了解决SSD检测小目标的问题,2017 年, Cheng-Yang Fu 等人提出了 DSSD 算法,将 SSD 算法的基础网络从 VGG-16 更改为 ResNet-101,增强网络特征提取能力,其次参考 FPN 算法思路利用去卷积结构将图像深层特征从高维空间传递出来,与浅层信息融合,联系不同层级之间的图像语义关系,设计预测模块结构,通过不同层级特征之间融合特征输出预测目标类别信息。在基于DSSD的基础之上,2017年,Zuoxin Li, Fuqiang Zhou两人提出了FSSD算法。2018年,Lisha Cui提出了MDSSD算法。这两个算法都是基于不同层级特征之间进行融合的思想。
由于小编目前只接触了R-CNN系列、YOLO系列和SSD系列的目标检测网络,关于深度学习的目标检测方法就介绍到这里。
由于Ian J. Goodfellow等人于2014年10月在Generative Adversarial Networks中提出了一个通过对抗过程估计生成模型的新框架之后,GAN网络越来越火,但是将GAN网络用来做目标检测却是极其少的,前一段时间小编看到一篇利用GAN来做目标检测的文章,下面小编将会介绍给大家。
基于GAN的目标检测
2017年,Jianan Li ,Xiaodan Liang, Yunchao Wei等人提出了《Perceptual generative adversarial networks for small object detection》,在这篇文章中提出了基于GAN的PGAN网络,PGAN网络结构如图5:整个网络可以看成由三个部分组成,其中最重要的是Generator和Discriminator网络。Generator网络的作用是将小目标生成与其对应的大目标尽可能相似的“超分辨率”的特征表示,如果目标的尺寸比较大的话,Generator网络其实没有做任何操作。Gernerator模型生成的“超分辨率”的特征图与经过原始卷积层后的特征图进行Eltwise Sum操作后送到Discriminator模型。Discriminator模型分成两个网络:Adversarial Branch和Perception Branch。Adversarial Branch用来判别生成的“超分辨率”的特征图与原始的大目标特征图的不同。Perception Branch是用来预测小目标的分类和定位的。Gernerator模型要尽可能生成与大目标相似的特征表示,而Adversarial Branch则要尽可能区分生成的特征表示与原始的大目标的特征表示,从而达到一种对抗的状态。
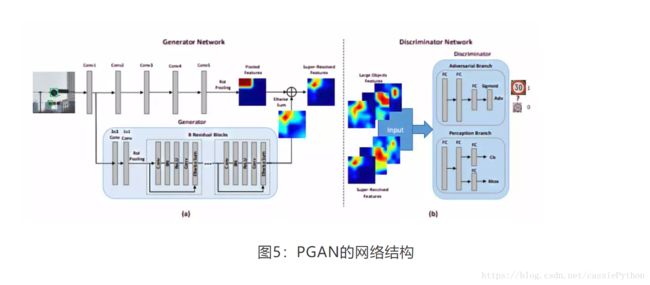
以上都是小编自己对PGAN网络的理解,如果大家有不同的想法可以留言,大家共同探讨,共同进步。
相信到这里,大家对目标检测的发展历程有了一定初步认识。下面是小编整理汇总的在文章中涉及到到的目标检测算法的paper和code共大家学习和参考。后续,小编将会为大家详细介绍这些目标检测算法。
欢迎关注博主的公众号“肥肥IT不爱bug”,在博客左侧也有二维码。
VJ检测框架:
paper:http://zoo.cs.yale.edu/classes/cs457/fall13/RobustReal-timeObjectDetection.pdf
HOG行人检测:
paper:https://ieeexplore.ieee.org/document/1467360/
DPM:
paper:https://dl.acm.org/citation.cfm?id=2494532
R-CNN:
arxiv: http://arxiv.org/abs/1311.2524
github: https://github.com/rbgirshick/rcnn
Fast R-CNN:
arxiv: http://arxiv.org/abs/1504.08083
github: https://github.com/rbgirshick/fast-rcnn
github: https://github.com/zplizzi/tensorflow-fast-rcnn
Faster-RCNN:
arxiv: http://arxiv.org/abs/1506.01497
github(Caffe): https://github.com/rbgirshick/py-faster-rcnn
github(PyTorch–recommend): https://github.com//jwyang/faster-rcnn.pytorch
github(TensorFlow): https://github.com/smallcorgi/Faster-RCNN_TF
github(TensorFlow): https://github.com/CharlesShang/TFFRCNN
github(C++demo): https://github.com/YihangLou/FasterRCNN-Encapsulation-Cplusplus
github(Keras): https://github.com/yhenon/keras-frcnn
YOLO:
arxiv: http://arxiv.org/abs/1506.02640
code: https://pjreddie.com/darknet/yolov1/
github: https://github.com/pjreddie/darknet
github: https://github.com/gliese581gg/YOLO_tensorflow
github: https://github.com/xingwangsfu/caffe-yolo
github: https://github.com/frankzhangrui/Darknet-Yolo
github: https://github.com/BriSkyHekun/py-darknet-yolo
github: https://github.com/nilboy/tensorflow-yolo
YOLOv2:
arxiv: https://arxiv.org/abs/1612.08242
code: http://pjreddie.com/yolo9000/ https://pjreddie.com/darknet/yolov2/
github(Chainer): https://github.com/leetenki/YOLOv2
github(Keras): https://github.com/allanzelener/YAD2K
github(PyTorch): https://github.com/longcw/yolo2-pytorch
github(Tensorflow): https://github.com/hizhangp/yolo_tensorflow
YOLOv3:
arxiv: https://arxiv.org/abs/1804.02767
code: https://pjreddie.com/darknet/yolo/
github(Official): https://github.com/pjreddie/darknet
github: https://github.com/experiencor/keras-yolo3
github: https://github.com/qqwweee/keras-yolo3
github: https://github.com/marvis/pytorch-yolo3
SSD:
arxiv: http://arxiv.org/abs/1512.02325
github(Official): https://github.com/weiliu89/caffe/tree/ssd
github: https://github.com/balancap/SSD-Tensorflow
github: https://github.com/amdegroot/ssd.pytorch
github(Caffe): https://github.com/chuanqi305/MobileNet-SSD
DSSD:
arxiv: https://arxiv.org/abs/1701.06659
github: https://github.com/chengyangfu/caffe/tree/dssd
github: https://github.com/MTCloudVision/mxnet-dssd
FSSD:
arxiv:https://arxiv.org/abs/1712.00960
MDSSD:
arxiv:https://arxiv.org/abs/1805.07009
PGAN:
arxiv:https://arxiv.org/pdf/1706.05274v1.pdf