darknet训练yolo_v3
使用官方darknet来训练YOLO-v3
官方darknet地址:https://github.com/pjreddie/darknet
1.基本环境的配置及安装:opencv、cuda、nvidia驱动、cudnn、darknet
参考教程:https://blog.csdn.net/gzj_1101/article/details/78651650
官方教程:https://pjreddie.com/darknet/install/
2.使用darknet训练voc2007和voc2012
2.1下载voc2007和voc2012数据集,下载三个文件:
VOCtest_06-Nov-2007.tar
VOCtrainval_06-Nov-2007.tar
VOCtrainval_11-May-2012.tar
2.2生成标签数据文件。这个地方主要生成两个文件,darknet提供了一个python脚本,运行这个脚本,将会生成图片路径的位置txt文件和数据标签txt文件这两个文件。
生成的数据标签是这样的形式:
这个地方需要注意的是,需要把VOCtrainval_06-Nov-2007和VOCtest_06-Nov-2007两个文件合并在一个voc2007文件中,最后voc2007和voc2012需要在同一个文件夹下VOCdevkit,在VOCdevkit这个当前路径下运行python脚本,才会处理所有的文件,生成所有需要的文件,不会因为路径报错。

图一 生成的图片路径TXT文件
比如打开2007_train.txt,内容如下:

图二 生成的文件路径格式
生成的标签文件分别在VOCdevkit/VOC2007/labels和VOCdevkit/VOC2012/labels这两个路径下,所有的标签文件都是以图片名命名的TXT文件,比如打开000010.txt:
12 0.484463276836 0.54375 0.483050847458 0.6875
14 0.531073446328 0.36875 0.316384180791 0.441666666667
其中12和14代表000010这张图片中有两个不同物体(object),后面四个归一化的值代表的object的位置。
2.3 修改源码下data/voc.data,设置自己训练集和测试集的路径
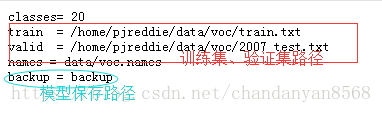
2.4 修改源码下cfg/yolov3-voc.cfg文件下训练的batch和subdivisions
2.5 下载darknet-53的模型文件,作为yolo_v3的预训练文件。终端中运行:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg weights/darknet53.conv.74
训练记录如下

图三 yolo_v3的训练记录
从训练记录中可以看到在网络的82层、94层、106层进行了检测。IOU代表的是交并比,指的是模型预测的框和标签文件中的框(ground truth)重合程度,重合程度越大,预测的越准。Class代表的预测物体的置信度。Obj和No obj代表的是object还是背景。.5R和075R代表的是召回率(也有的喜欢叫查全率,recall)。
这里需要注意的是:
- 为了充分使用显卡内存,适当调整batch和subdivisions,源码中是这样计算的:
int subdivs = option_find_int(options, "subdivisions",1);
net->time_steps = option_find_int_quiet(options, "time_steps",1);
net->batch /= subdivs;
net->batch *= net->time_steps;
因此net的batch为cfg中的batch/subdivisions*time_steps,默认time_steps为1。
2.显存不是很大的情况,可以把yolov3-voc.cfg中的random设置为0
