常用图像分类网络
想对图像分类网络写个简要的概括,如有介绍不当之处,还望指出。
一、VGG网络
更新于2018年10月20日
参考博客:深度学习经典卷积神经网络之VGGNet
论文地址:VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
VGG是牛津大学计算机视觉组(VisualGeometry Group)和GoogleDeepMind公司的研究员一起研发的的深度卷积神经网络。
VGG标签:“三个臭皮匠赛过诸葛亮”
三个臭皮匠赛过诸葛亮:使用多个3*3的卷积核代替5*5的卷积核
在ILSVRC 2014比赛分类项目的第2名,分类错误率7.3%
网络结构:
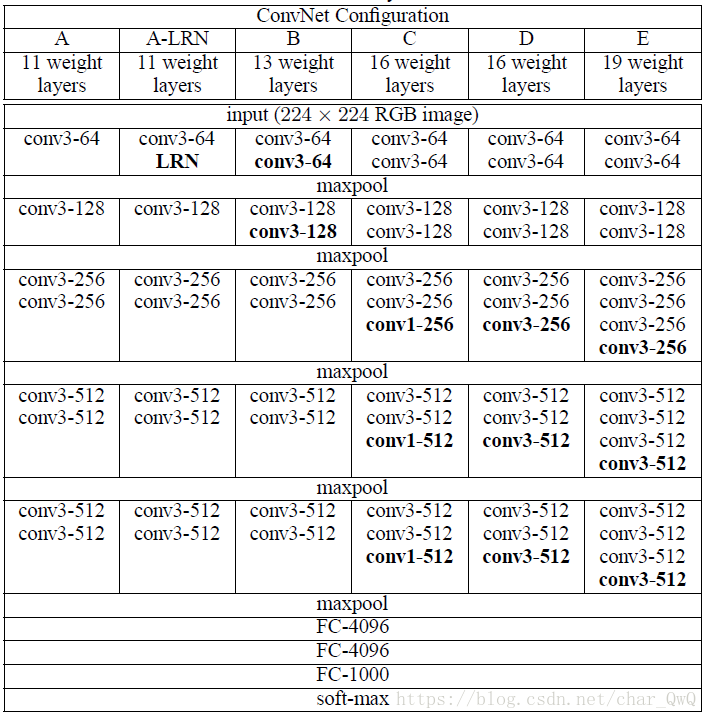
其中,D列是常用的VGG16,E列是VGG19。
特点:使用3*3的小卷积核代替5*5或7*7的卷积核。原因如下:
(1)3x3是最小的能够捕获像素八邻域信息的尺寸。
(2)两个3x3的堆叠卷基层的有限感受野是5x5;三个3x3的堆叠卷基层的感受野是7x7,故可以通过小尺寸卷积层的堆叠替代大尺寸卷积层,并且感受野大小不变。
(3)多个3x3的卷基层比一个大尺寸filter卷基层有更多的非线性(更多层的非线性函数),使得判决函数更加具有判决性。
(4)多个3x3的卷积层比一个大尺寸的filter有更少的参数,假设卷基层的输入和输出的特征图大小相同为C,那么三个3x3的卷积层参数个数3x(3x3xCxC)=27C2;一个7x7的卷积层参数为49C2;所以可以把三个3x3的filter看成是一个7x7filter的分解(中间层有非线性的分解, 并且起到隐式正则化的作用。
二、Inception网络
参考博客:Google InceptionNet介绍
论文地址:Rethinking the Inception Architecture for Computer Vision
刚才讲的VGG是14年ILSVR分类比赛的老二,Inception是老大,分类错误率6.67%
Inception标签:“分而治之”,BatchNormalization。
分而治之:采用分支的方式增大网络的宽度和深度能够很好的提高网络的性能,避免过拟合。
BatchNormalization:就是在每一层输出后再对输出结果进行规范化,这样使得网络更容易收敛,且分类准确率有提升。
三种Inception基本网络结构:
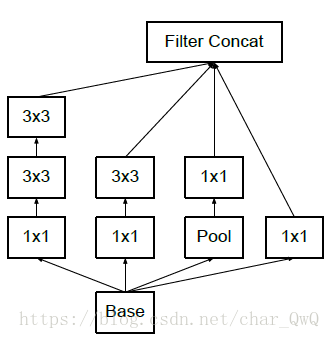
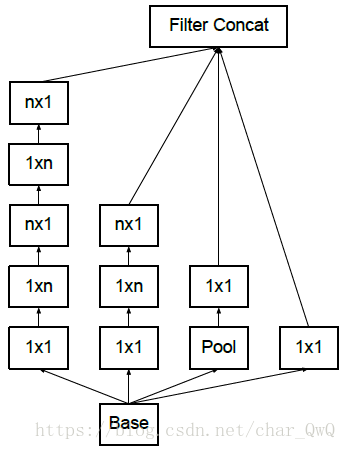

特点:InceptionNet采用分支网络堆叠在一起产生较大通道的输出。原因如下:
每个分支都采用了1*1的卷积网络,因为这是一个优秀的网络,可以跨通道组织信息,提高网络的表达能力,提供更多的非线性变换,性价比很高。同时网络中的卷积和大小也不一样,可以增加网络对不同尺度的适应性。所以,InceptionNet通过分支的方式增大网络的宽度和深度能够很好的提高网络的性能,避免过拟合。
InceptionNet还可以将一个较大的卷积网络拆分成两个小的卷积网络。比如将7*7网络拆分成1*7和7*1的卷积网络,这样可以节约大量参数,加速运算并减轻过拟合,同时增加了一层非线性变换拓展了模型的表达能力。如上图中的后面两种Inception结构。
Inception网络结构:

figure 5/6/7分别对应着上图中的三种Inception结构
三、ResNet
参考博客:ResNet解析
论文地址:Deep Residual Learning for Image Recognition
ResNet全名Residual Net,残差网络。是ImageNet 2015年的分类冠军模型。
ResNet标签:“越级上报”
越级上报:即跨层连接,第n层的输出结果不仅输入给第n+1层,还跨两层输出给第n+3层(ResNet34),
跨三层的是ResNet50/101/152
ResNet常见的有ResNet 50、ResNet 101和ResNet 152
ResNet网络结构:

其他特点:
跨三层的ResNet先使用1*1的卷积降维,然后进行3*3的卷积之后,再用1*1的卷积升维。减少了参数数量,防止过拟合。
ResNet网络结构的特性使得即使网络层数加深,也不会导致梯度消失或者梯度爆炸的现象(链式求导)
四、DenseNet
更新于2018年10月30日
参考博客:DenseNet算法详解
论文地址:Densely Connected Convolutional Networks
DenseNet和ResNet有点像,恰巧看DenseNet的这几天听了一位长江学者的讲座,在此借用该学者的话:
“现在的人工智能(指深度学习)用的理论仍然是很多年前的人工智能的理论,像什么求梯度啊激活函数啊,没有任何理论方面的创新,有的只是框架方面的更新。”
在我看来,现在AI的发展很大方面得力于工业届的宣传,工业的热潮影响到学术界,所以现在有更多的人去研究AI。虽然现在的AI的确缺乏理论创新,但是work就行啊!管他黑猫白猫,能抓到老鼠的就是好猫!
哦该大佬说的另一句话我觉得也很有道理:
现在的学术论文,千分之一的论文是有直接价值的,剩下的千分之九九九,不能说是没有价值,它们是有潜在价值的。这些潜在价值可能在很多年后才会有人发现它们的价值所在。
好了,回归正题~
DenseNet,顾名思义,就是很紧密、稠密的网络,是CVPR2017的best paper。
DenseNet标签:太平洋警察——管的宽
太平洋警察——管的宽:某一层网络的输入不仅来自于它前面的那一层,它前面所有层的输出都要传递给该层。
DenseNet网络结构:
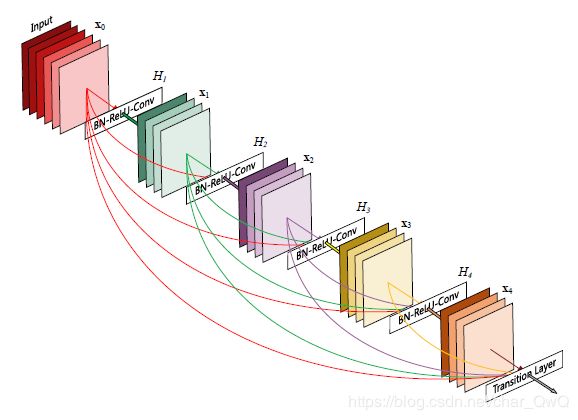

其他特点:
由于每一层的输出都传递到了后面的每一层,所以Dense connection能够有效的减轻梯度消失现象;
Dense connection还有一个好处是能够充分利用feature;
DenseNet用的卷积核数量很小,一般是32或者48;
1*1卷积(文章中叫bottleneck layer或Translation layer)的作用是降维减少参数+融合各个通道的信息。因为在对前面所有层进行concat后,拼接后的通道会很大,因此需要1*1的卷积来降维。
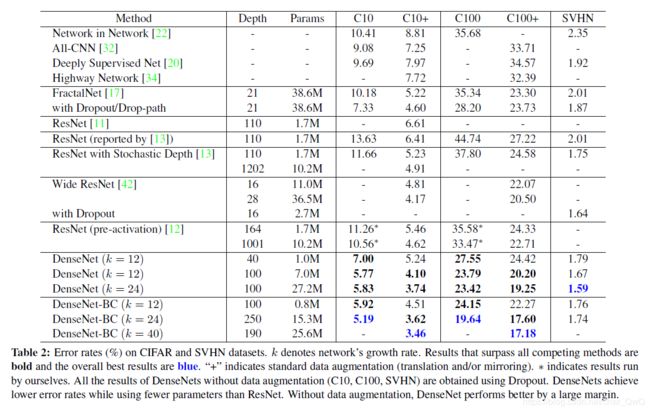
实验结果:
五、InceptionResNet
待续