从声学模型算法总结 2016 年语音识别的重大进步
转自http://www.leiphone.com/news/201701/ZEDsG4fOpI2zr2OA.html
薛少飞,阿里巴巴 iDST 语音识别专家,中国科学技术大学博士。现负责阿里声学模型研究与应用:包括语音识别声学建模和深度学习在业务场景中的应用。博士期间的研究方向为语音识别说话人自适应,提出基于 Speaker Code 的模型域自适应方法,在语音相关的会议和期刊上发表论文十余篇。
本期雷锋网硬创公开课的分享主要包括三大部分:

-
深度神经网络声学模型发展回顾:简单回顾深度神经网络技术在语音识别声学模型中的应用历史;
-
前沿声学模型技术进展:介绍近期几个比较有意思的声学模型技术进展,包括 Deep CNN 技术、Residual/Highway 网络技术和粗粒度建模单元技术。当然这里并没有把所有的新技术进展都囊括进来,比如 Attention 技术。只是以这三条线路为例看看语 音识别声学模型技术的进展和未来的发展趋势。
-
介绍绍阿里巴巴的语音识别声学模型技术。
一、深度神经网络声学模型发展回顾

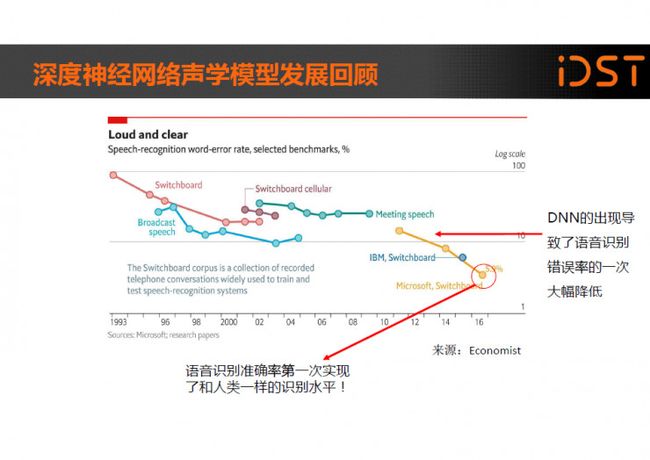
回顾语音识别技术的发展历史可以看到,自从上世纪 90 年代语音识别声学模型的区分性训练准则和模型自适应方法被提出以后,在很长一段内语音识别的 发展是比较缓慢的,语音识别错误率的那条线一直没有明显的下降。直到 2006 年 Hinton 提出深度置信网络(DBN),促使了深度神经网络(DNN)研究的复苏。
2009 年,Hinton 将 DNN 应用于语音的声学建模,在 TIMIT 上获得了当时最好的结果。2011 年底,微软研究院的俞栋、邓力两位老师又把 DNN 技术应用在了大词汇量连续语音识别任务上,大大降低了语音识别错误率。从此以后基于 DNN 声学模型技术的研究变得异常火热。微软去年 10 月发布的 Switchboard 语音识别测试中,更是取得了 5.9%的词错误率,第一次实现了和人类一样的识别水平,这是一个历史性突破。
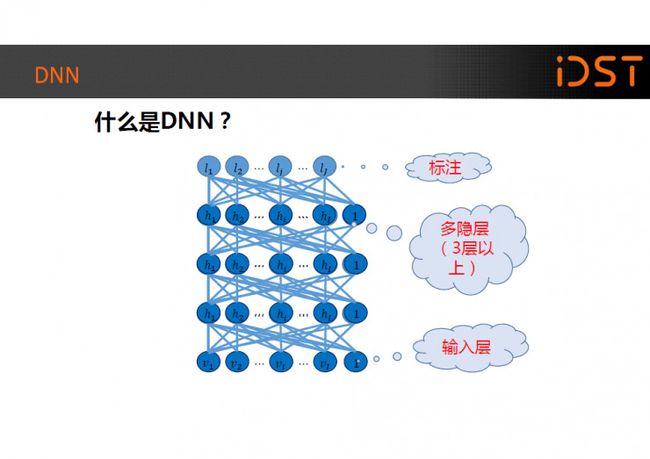
那么什么是 DNN 的?其实标准的 DNN 一点也不神秘,它和传统的人工神经 (ANN)在结构上并没有本质的区别,只是 ANN 通常只包含一个隐层,而 DNN 则是通常包含至少 3 层以上的隐层,通过增加隐层数量来进行多层的非线性变换,大大的提升了模型的建模能力。
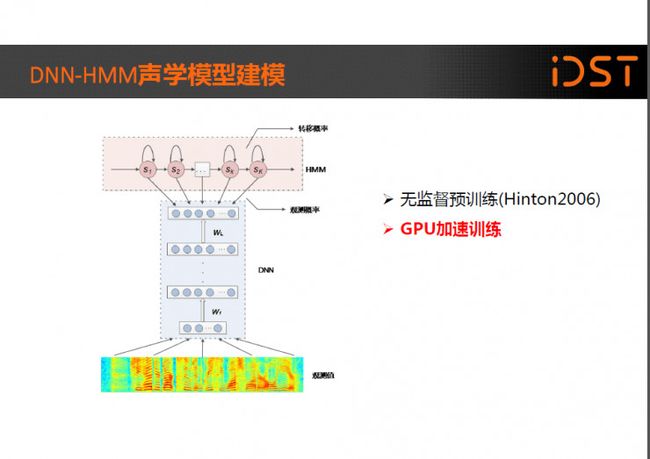
这是基于 DNN 的语音识别系统框架,相比传统的基于 GMM-HMM 的语音识别系统,其最大的改变是采用 DNN 替换 GMM 模型对语音的观察概率进行建模。
相比传统 GMM 模型我觉得有两点是非常重要的:
-
1.使用 DNN 不需要对语 音数据分布进行假设。
-
2. DNN 的输入可以是将相邻语音帧拼接形成的包含时序结构信息的矢量。
当时训练 DNN 的普遍做法是先进行无监督的预训练,而后进行有监督的调整,后来人们发现当数据量非常大的时候无监督的预训练并不是必要的,当然这是后话了。
促使 DNN 的研究在那时重新兴起还有一个非常重要, 并且我个人认为是最核心的因素,就是计算能力的提升。
以前要在 CPU 上训练 DNN 是非常慢的,做一个实验可能需要好几周甚至几个月,这是不能忍受的,随着 GPU 的出现这种情况发生了变化,GPU 非常适合对矩阵运算进行加速,而 DNN 的训练最终都可以被拆解成对矩阵的操作,两者天然和谐。
而今随着 GPU 技术的不断发展和进步,我们能够训练数据量更大、网络更深、结构更复杂的模型,这才有了深度神经网络技术的迅速发展。
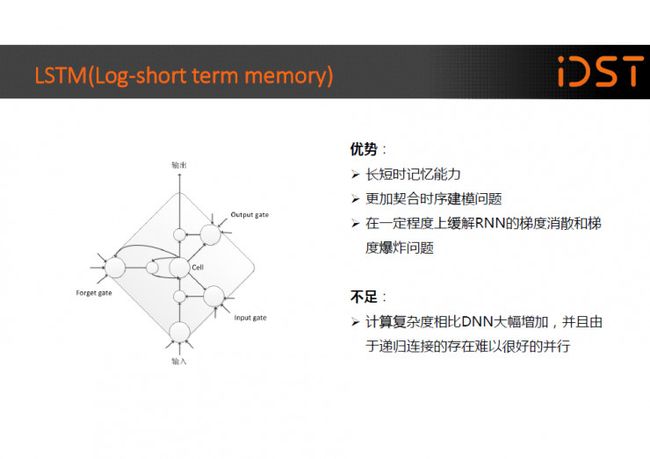
LSTM 模型相信大家都不陌生,它一种特殊的循环神经网络(RNN)。语音识别本来就是一个时序建模问题,所以非常适合用 RNN 来进行建模。
但是简单 的 RNN 受限于梯度爆炸和梯度消散问题,比较难以训练。而 LSTM 通过输入门、 输出门和遗忘门可以更好的控制信息的流动和传递,具有长短时记忆能力,并在一定程度上缓解 RNN 的梯度消散和梯度爆炸问题。当然它也有不足之处,计算复杂度相比 DNN 大幅增加,并且由于递归连接的存在难以很好的并行。

BLSTM 进一步提升了该类模型的建模能力,相比 LSTM 还考虑了反向时序信息的影响,也即“未来”对“现在”的影响,这在语音识别中也是非常重要的。
当然这种能力的代价就是模型计算复杂度进一步加大,并且通常需要整句进行训 练:GPU 显存消耗增大->并行度降低->模型训练更慢,另外在实际应用中还存在实时性问题。
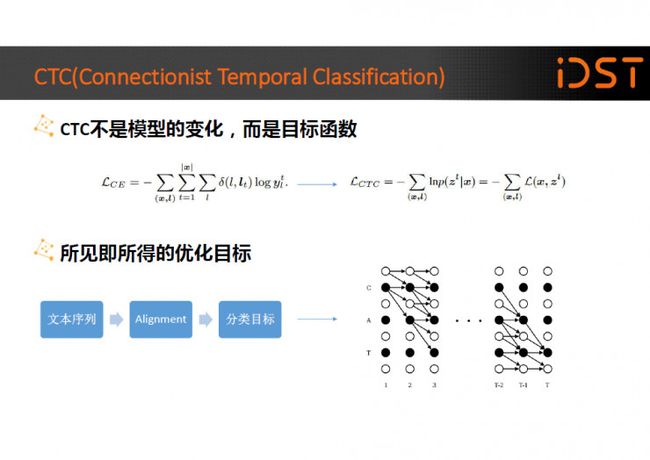
CTC 技术在过去的一段时间内也非常的火热,首先要说明的是 CTC 并不是模型的变化,而是优化的目标函数发生了改变,DNN、LSTM、CNN 都可以和 CTC 相结合。
传统的深度神经网络声学模型的训练过程需要先对训练数据文本序列做 Alignment 得到分类的“硬判决”,之后以这种“硬判决”的分类为目标训练 神经网络,网络优化的目标并不是最终要识别的结果。和传统的深度神经网络声 学模型相比 CTC 的优化目标是一种所见即所得的优化目标,你要训练的目标就 是你想要得到的结果。
传统的深度神经网络声学模型建模单元通常是 state 级的,而 CTC 的建模单元则是 phone 一级甚至是 character 的,state 级反而不好,这种建模粒度的 变化带来一个好处就是语音数据的冗余度增加了,相邻的语音帧本来就会很像并 可能来自于同一个 phone,那么现在就不需要这么多帧数据来建模一个句子。
通过拼帧降采样的方法可以降低数据的总帧数,在不影响识别准确率的情况下加快网络计算的速度。CTC 的另一个非常重要的贡献是引入了“Blank”空白,空白的 引入避免了易混淆帧的“强制”对齐。并且使得训练后的网络输出呈现“尖峰”状 态,大段的 Blank 使得解码时通过 beam 的灵活调整,可以加快解码速度。

语音识别领域有非常多的开源工具,传统的语音识别开源工具像 CMU SPHINX 系统,是基于统计学原理开发的第一个“非特定人连续语音识别系统”; 剑桥语音识别组推出的 HTK 工具包是 GMM-HMM 时代最为流行的语音识别工具,我刚接触语音识别就是从 HTK 开始的。
几年前推出的 kaldi 严格来讲并不十 分“传统”,也是比较新并且在不断更新的开源工具,目前应该也是使用人数最多的语音识别开源工具。
近两年来许多深度学习开源框架涌现了出来,像 Theano、 CNTK、TensorFlow 等,接下来我会对传统的语音识别工具和新的深度学习开源框架做一个对比,那么我就简单从几个我比较关心的维度来抛砖引玉看看 kaldi、CNTK 和 TensorFlow 的异同。
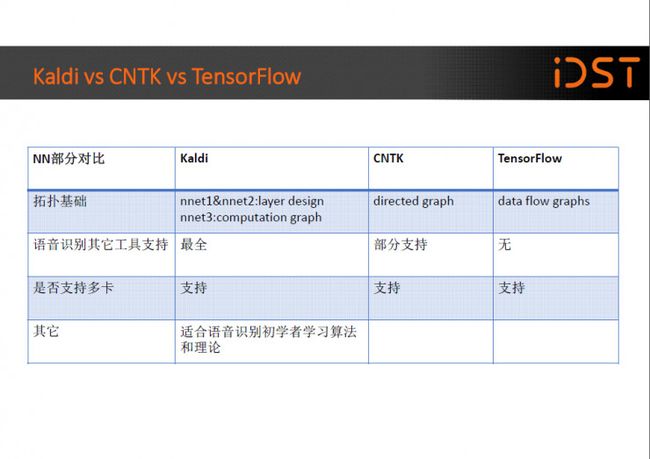
在拓扑基础方面,kaldi 的 nnet1 和 nnet2 是以层设计为基础的,也即当你新增加一种神经网络层时需要自己定义它的结构,都有哪些变量,正向怎么算, 反向误差怎么传播等等,并且过于复杂的连接方式很难支持。
而 kaldi 的 nnet3 和 CNTK 以及 TensorFlow 都是以图结构为基础的,通过配置文件实现对网络连接方式的定义,数据就像流水一样在你定义的网络图中游走,并自己实现误差的 反向传播,它的优点是你可以专注网络拓扑结构的设计,而不用为网络计算的细 节而费心,特别是误差的反向传播。
但这也带来一个问题,尤其是对初学者而言, 会造成只是在设计网络长成什么样子,但并不清楚其中的实现细节。初学者最好多推推公式,对打下一个坚实的基础绝对有好处。
在语音识别其它工具支持方面,kaldi 有全套的语音识别工具,包括解码器、 建立决策树、GMM 训练等等,而 CNTK 和 TensorFlow 在这方面并没有特别的支持,值得一提的是 CNTK 里提供了把 kaldi 数据处理成为 CNTK 数据格式的工具,使的用 kaldi 的人也可以很快上手 CNTK,大家不妨试一下。
最后一个我比较关心的因素就是是否支持多机多卡,因为随着数据量和模型复杂度的不断攀升,仅仅用一个 GPU 很难满足模型训练的需要,必须使用多个 GPU 来加速训练。在这方面目前 kaldi、CNTK、TensorFlow 都已经支持。
最后我的建议是对于语音识别的初学者和低年级的研究生来讲,用 kaldi 入门学习算法和实践理论知识是比较好的选择,对于高年级研究生和具有一定年限的从业人员来讲,就看自己的喜好了,大家都是殊途同归,工具不是决定性的, 数据、算法和模型才是。
二、前沿神学模型的技术进展
接下来介绍一下 Deep CNN 技术、Residual/Highway 网络技术和粗粒度建模 单元技术。去年有多家机构都推出了自己的 Deep CNN 模型,像 IBM、微软等,我这里以 IBM 的 Deep CNN 为例,一起探讨一下到底哪些关键因素使得 Deep CNN 能够取得这么好的效果。

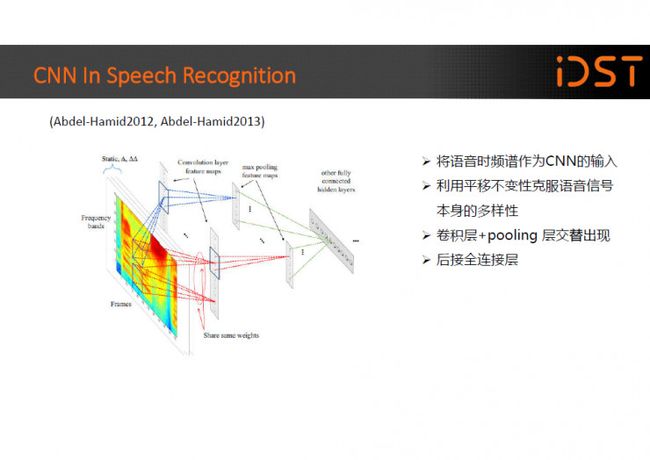
其实 CNN 被用在语音识别中已经不是一天两天了,在 12、13 年的时候 Ossama Abdel-Hamid 就将 CNN 引入了语音识别中。
那时候的卷积层和 pooling 层是交替出现的,并且卷积核的规模是比较大的,CNN 的层数也不是特别的多, 主要是用来对特征进行进一步的加工和处理,使其能更好的被用于 DNN 的分类。
后来随着 CNN 技术在图像领域的发展,情况慢慢出现了变化,人们在图像领域 的研究中发现多层卷积之后再接 pooling 层,减小卷积核的尺寸可以使得我们能够训练更深的、效果更好的 CNN 模型。相应的方法被借鉴到了语音识别中,并 根据语音识别的特点进行了进一步的优化。
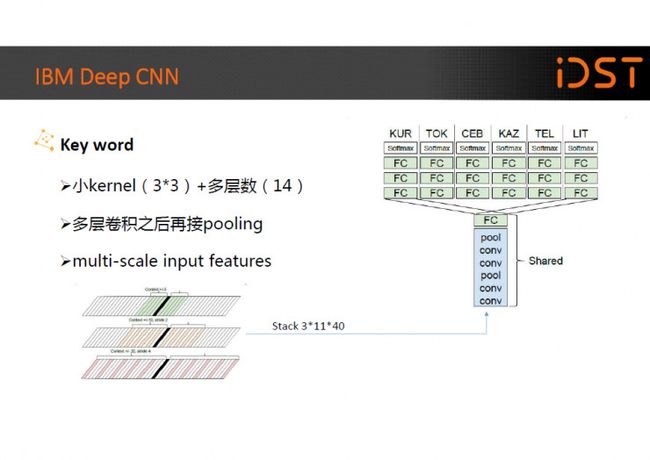
IBM 的研究人员在 16 年的 ICASSP 上发表文章,称使用 3x3 的小卷积核和 多层卷积之后再接 pooling 的技术可以训练出 14 层(包含全连接)Deep CNN 模型。

在 Switchboard 数据集上相比传统的 CNN 使用方法可以带来相对约 10.6%WER 下降。小尺寸的卷积核和多层卷积之后再接 pooling 的技术是使 Deep CNN 能够成功的关键点。
接下来介绍一下 Residual/Highway 网络以及它们目前在语音识别中的应用情况。

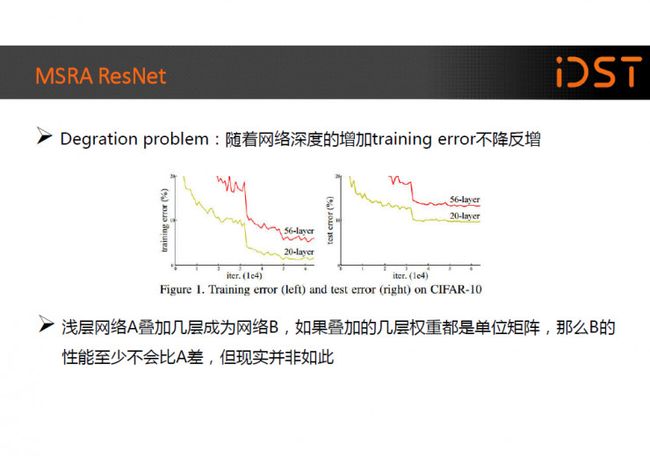
Residual 网络会这么出名得益于 MSRA 的 152 层让人“疯狂”的深度神经网络,凭借着它 MSRA 在 2015 ImageNet 计算机识别挑战赛中以绝对优势获得图像分类、图像定位以及图像检测全部三个主要项目的冠军。
在公开的论文当中, 作者详细解读了他们的“心路历程”。
研究人员发现在深度神经网训练过程中总是会出现”Degration Problem”,即当网络深度达到一定程度以后,随着网络深度的 增加 training error 将不降反增,并且这不是由于过拟合引起的。
一般来讲我们 认为一个浅层网络 A 叠加几层成为网络 B,如果叠加的几层权重都是单位矩阵,那么 B 的性能至少不会比 A 差,但现实并非如此,网络自己很难学习到这种变换。
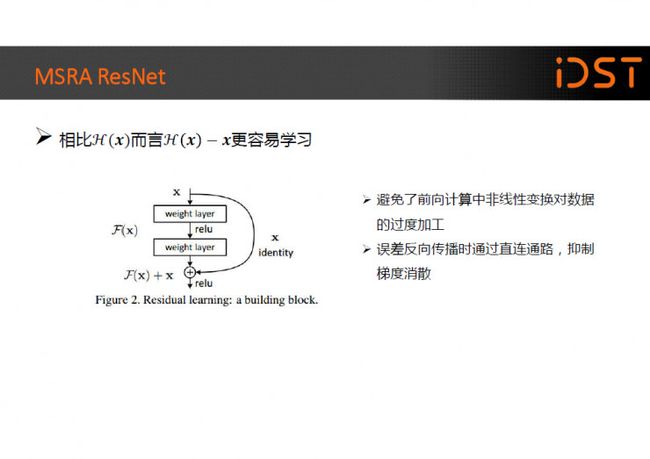
而相比与学习目标函数而言残差更容易学习,于是提出了一种 residual learning 的结构,增加了一个越层的短连接。我的理解是这种短连接一方面避免了前向计算中非线性变换对数据的过度加工,另一方面在误差反向传播时通过直 连通路,可以让误差有路径直接回传,抑制梯度消散。
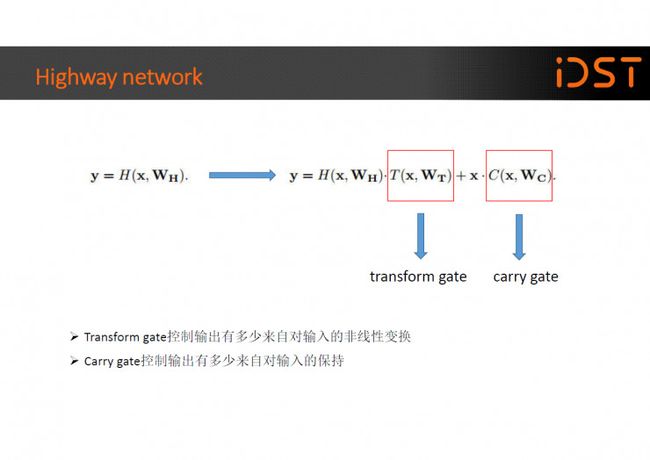
大约稍早,Srivastava 在 arxiv 上传了他的 Highway 网络工作,在 Highway 网络中一个隐层节点的输出不再单单是输入通过非线性变换后的数值,而是变成 了通过 Transform gate 和 Carry gate 对非线性变换后的数值和输入进行加权得到的结果。Residual 网络可以被看成是 Highway 网络的一种不额外增加参数量的特例。
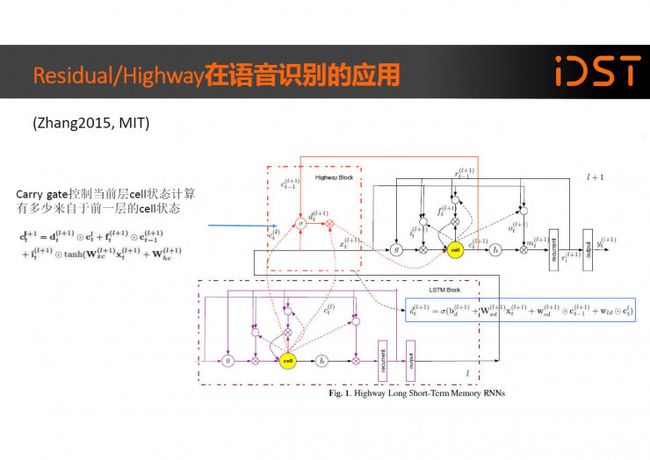
Residual/Highway 网络这么有效果,语音识别领域的研究人员当然也会关注并使用。我来举几个例子,在“Highway Long Short-Term Memory RNNs for Distant Speech Recognition”中作者提出 Highway LSTM 结构,引入了一种 carry gate,Carry gate 控制当前层 cell 状态计算有多少来自于前一层的 cell 状态, carry gate 的计算又取决于当前层的输入、当前层前一时刻的 cell 状态和前一层当前时刻的 cell 状态。通过这种模型结构实现了信息在模型内部更好的跨层流动。
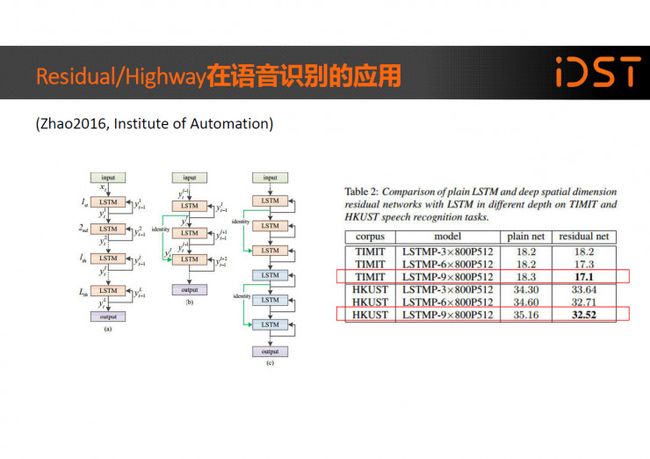
在 ”Multidimensional Residual Learning Based on Recurrent Neural Networks for Acoustic Modeling”中作者将 Residual 的概念应用到 LSTM 模型 中,并在 TIMIT 和 HKUST 两个数据集上验证了实验效果。
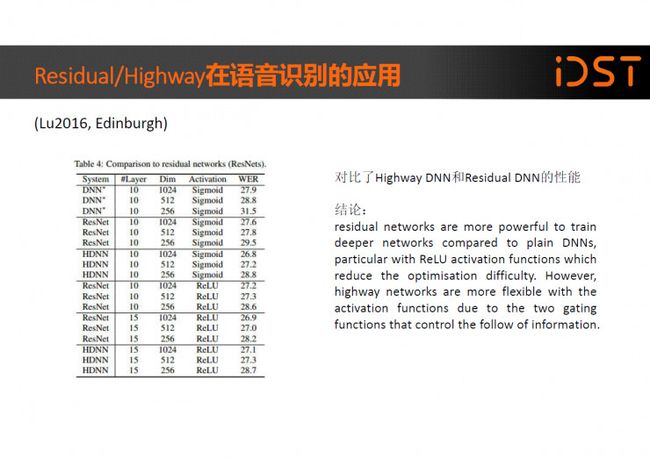
在 ”Renals.Small-footprint Deep Neural Networks with Highway Connections for Speech Recognition”中作者对比了 Residual DNN 和 Highway DNN 在语音识别上的效果,得到的结论是:” residual networks are more powerful to train deeper networks compared to plain DNNs, particular with ReLU activation functions which reduce the optimisation difficulty. However, highway networks are more flexible with the activation functions due to the two gating functions that control the follow of information.”

下面是粗粒度建模单元技术,Low frame rate 技术我会放到后面结合阿里巴巴的声学模型技术进行说明,先来看一下 Chain 模型。Chain 模型是 kaldi 的作者 Daniel Povey 近期力推的工作,它使用的也是 DNN-HMM 架构,表中我列出了 chain 模型和传统的神经网络声学模型建模的不同点。

在建模单元方面,传统神经网络声学模型的建模单元一般是 3 状态或者 5 状态的 CD phone,而 chain 模型的建模单元则是 2 状态,其中 sp 是最主要用来表征该 CD phone 的状态,而 sb 则是该 CD phone 的“Blank”空白,空白的概念 其实和 CTC 中的很相似,只是在 chain 模型中每一个建模单元都有自己的空白。
在训练方法上,传统神经网络声学模型需要先进行 Cross-Entropy 训练,后进行区分性准则训练。而 chain 模型直接进行 Lattice-Free MMI 训练,当然其后还可 以接着进行区分性准则训练,但是从目前的报道来看,这部分的提升是比较小的。
在解码帧率方面由于 chain 模型使用的是拼帧然后降采样的方法,解码的帧率只有传统神经网络声学模型的三分之一,而识别准确率方面相比传统模型会有非常明显的提升。 总结一下我认为未来深度神经网络声学模型主要有三个发展方向。

1.更 Deep 更复杂的网络
类似MSRA152 层 ResNet 的技术,虽然以目前的计算能力在语音识别 的实际应用中这种复杂网络结构的模型暂时还不能落地,但是持续不断 的研究和探索可以为我们明确我们努力的方向和能力所能达到的上界。
2. End to End 的识别系统
End to End 的识别系统一直是近年来比较火的研究方向,如 CTC、 Attention 等都是在这方面非常有意义的工作,在海量规模的语音数据上 建立计算速度快、识别准确率高的 End to End 的识别系统会是未来的 一个重要课题。
3. 粗粒度的建模单元 state->phone->character
粗粒度建模单元的技术对于加快语音识别的解码速度具有非常重要的 意义,而反过来解码速度的提升又可以让使用更深、更复杂神经网络建 模声学模型成为可能。
三、阿里巴巴的语音识别声学模型技术
最后分享一下阿里巴巴团队在语音识别声学模型技术方面的一些工作。

在工业界做语音识别,数据量是非常庞大的,上万小时的语音数据是再正常 不过的,面对如此庞大的数据量,使用单机单 GPU 或者单机多 GPU 进行模型 的训练是远远不能满足需求的,必须具有多机多 GPU 进行模型训练的能力。

我们使用的基于 Middleware 的多机多卡方案。GPU Middleware 提供了 API 接口使得我们可以通过对训练工具(kaldi、caffe 等)的简单修改实现并行训练。并且可以自主管理任务队列、数据分发、通信、同步等,是我们能够更多的专注于算法本身。采用 Master-slave 模式,支持 MA / SGD / ASGD 等。

这是 Model Averaging 的一个示例:
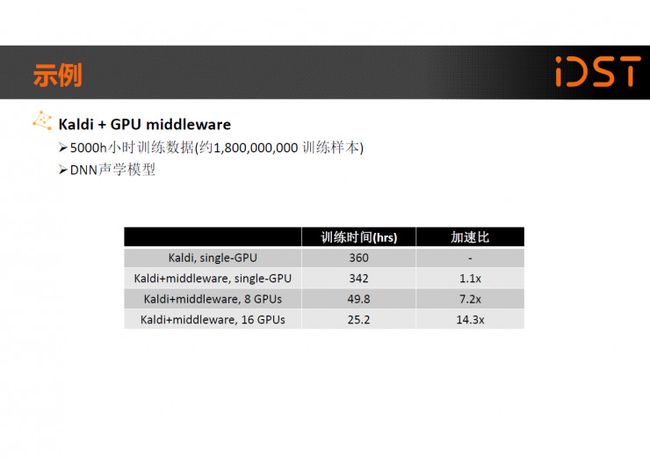
表格里给出的是在 5000h 小时训练数据情况下训练 DNN 模型的加速效果, 可以看到使用 8 个 GPU 的情况下大约可以取得 7.2 倍的加速,使用 16 个 GPU 的情况下大约可以取得 14.3 倍的加速。我们目前使用的是 Latency-control BLSTM 模型,这里面有从 BLSTM 到 CSC-BLSTM 再到 LC-BLSTM 的发展历程。

我们知道 BLSTM 可以有效地提升语音识别的准确率,相比于 DNN 模型,相对性能提升可以达到 15%-20%。
但同时 BLSTM 也存在两个非常重要的问题:
1. 句子级进行更新,模型的收敛速度通常较慢,并且由于存在大量的逐帧计算,无法有效发挥 GPU 等并行计算工具的计算能力,训练会非常耗时;
2. 由于需要用到整句递归计算每一帧的后验概率,解码延迟和实时率无法得到有效保证,很难应用于实际服务。对于这两个问题,前 MSRA lead researcher,目前已经是阿里巴巴 iDST 语 音团队负责人的鄢志杰和他当时在微软的实习生一起首先提出 ContextSensitive-Chunk BLSTM ( CSC-BLSTM)的 方法加 以解决。
而此后文献 (Zhang2015, MIT)又提出了 Latency Controlled BLSTM(LC-BLSTM)这一改进版本,更好、更高效的减轻了这两个问题。我们在此基础上采用 LC-BLSTM-DNN 混合结构配合多机多卡、16bit 量化等训练和优化方法进行声学模型建模。完成了业界第一个上线的 BLSTM-DNN hybrid 语音识别声学模型。

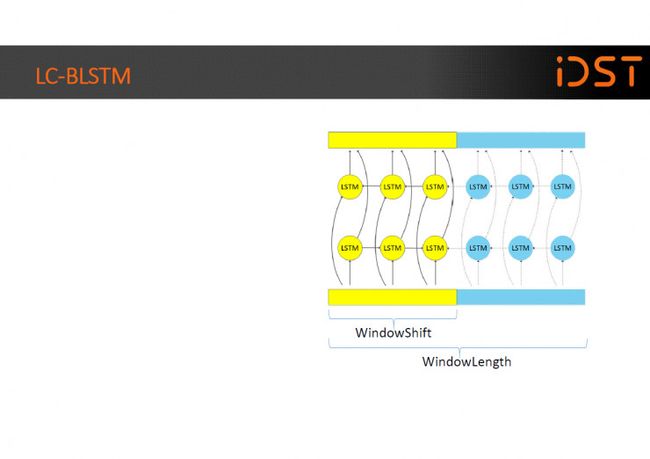
这两张是 LC-BLSTM 的示意图,训练时每次使用一小段数据进行更新,数据由中心 chunk 和右向附加 chunk 构成,其中右向附加 chunk 只用于 cell 中间状态的计算,误差只在中心 chunk 上进行传播。时间轴上正向移动的网络,前一 个数据段在中心 chunk 结束时的 cell 中间状态被用于下一个数据段的初始状态, 时间轴上反向移动的网络,每一个数据段开始时都将 cell 中间状态置为 0。
该方法可以很大程度上加快网络的收敛速度,并有助于得到更好的性能。解码阶段的数据处理与训练时基本相同,不同之处在于中心 chunk 和右向附加 chunk 的维 度可以根据需求进行调节,并不必须与训练采用相同配置。
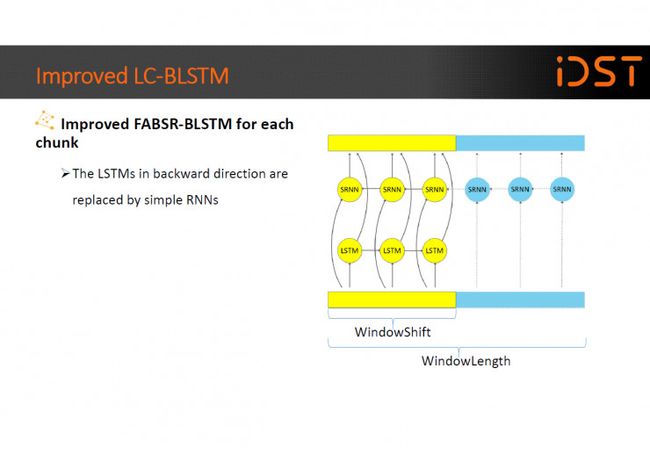
进一步,我们又在 LC-BLSTM 上进行了改进,首先提出一种改进的 FABDIBLSTM 模型,它和 LC-BLSTM 的不同在于时间轴上反向移动的网络,cell 中间状态是由 feed-forward DNN 计算得到的,而不是原来采用的递归方式,这样在 尽可能保证识别准确率的同时,降低了模型的计算量。
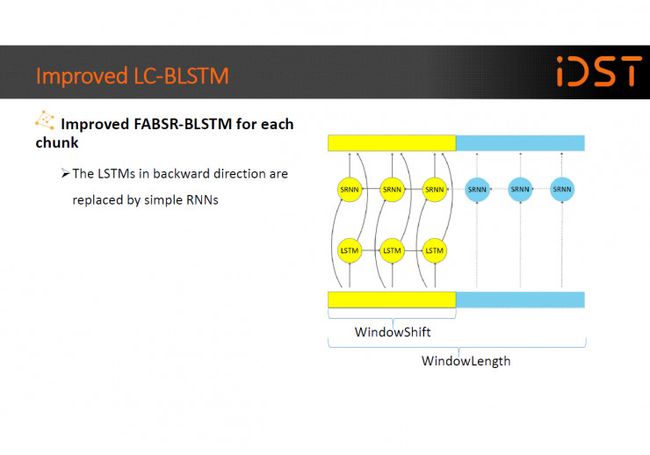
我们还提出一种改进的 FABSR-BLSTM 方法,用简单 RNN 替代时间轴上反向移动的 LSTM,以加快这部分的计算速度。
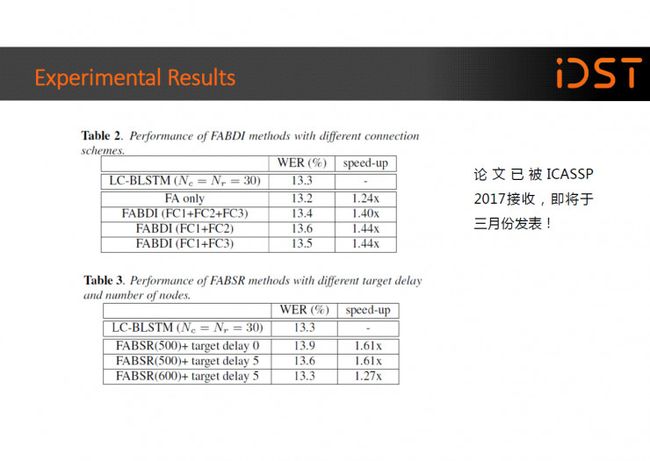
表里面给出的是我们的实验结果,在 Switchboard 数据集上的实验表明在损失少量精度的情况下,我们的改进版模型相比标准的 LC-BLSTM 可以取得 40%- 60%的解码加速。这部分工作已经被 ICASSP 2017 接收,即将于今年三月份发表。

Low frame rate(LFR)是我们上线的又一新技术,LFR 是在 Interspeech 2016 会议上由谷歌的研究人员提出的,在论文中研究人员宣称 CTC 技术只有在 4 万 小时以上的数据量下才有更好的效果,而 LFR 通过使用单状态的 CD-Phone、 拼帧并降帧率、soft label、CE 初始化、Output Delay 等技术可以让传统神经网 络识别模型取得和 CTC 近似或更好的效果。
我们借鉴了论文中的方法并将其成功应用在 LC-BLSTM 上,在我们的一个上万小时数据的任务上。
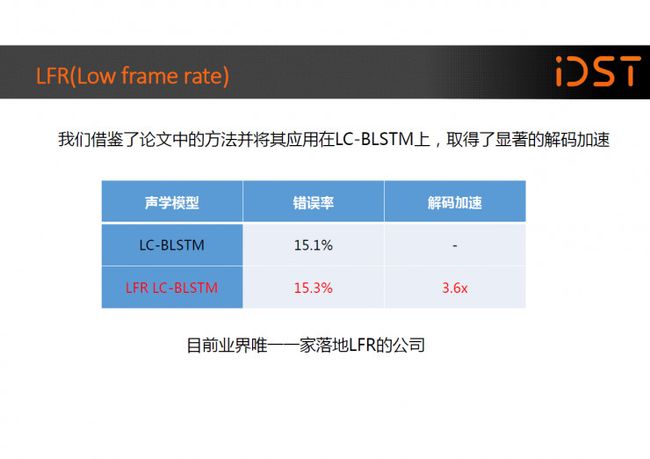
LFR-LC-BLSTM 可以取得和 LC-BLSTM 差不多的识别 错误率,并且有约 3.6 倍的解码加速。据我们所知(to the best of our knowledge), 我们也是目前业界唯一一家落地 LFR 技术的公司。
在模型的鲁棒性方面,我们也做了非常多的工作。模型的鲁棒性一直是困扰 业界和研究人员的一个问题,比如用安静环境下的语音数据训练的模型在噪声环境下识别准确率就很差,用新闻播报的语音数据训练的模型去识别激情的体育解说,识别准确率也会很差。
那么如何克服不同的信道、噪声、应用场景的差异,使声学模型具有更好的鲁棒性呢,最好的办法当然是收集更多真实场景下的语音 数据,但是如果一时之间做不到呢?
怎么利用现有的语音数据去尽可能的提升模 型的噪声鲁棒性?能不能利用现有数据去“造”和目标场景很类似的数据?
这是一个很有意思的研究课题。算法层面的改进这里暂且不提,说一下我们在“造”数 据上的一些工作,我们设计了一套完整的数据分析、数据筛选和数据加工流程。

从应用场景分析开始,我们会去分析信道情况、噪声情况、语境情况等等。然后根据对应用场景的分析自动筛选适合的训练数据。再根据不同的场景情况, 进行加噪、加快语速等处理。最后训练模型进行测试,再根据对结果的分析反馈我们应用场景的分析。
这一整套流程开始时由人为设计的,现在正逐步往自动化流程上推,依托阿里 MaxCompute 高效计算平台我们可以快速的完成海量数据的加工处理,这大大解放我们的算法人员,让大家有更多的经历投入到技术上的优化,而不是为数据烦恼。 最后是我们语音识别技术应用的一些案例,像是内部的智能质检和智能电话 客服,阿里云年会上实时语音识别挑战金牌速记员。
最后是我们语音识别技术应用的一些案例,比如阿里巴巴内部的智能质检和智能电话客服,从去年开始,阿里集团与蚂蚁客服每接听一个电话,都会立刻启动一个叫风语者的系统,它就是自动语音识别技术,将语音转变成文字,千分之三的人工抽检可以瞬间升级为100%的自动质检。除此应用场景之外,阿里YunOS、阿里小蜜以及手淘,现在都已经应用到阿里云的语音识别系统。
阿里云在 2016年 会上公开展示实时语音识别技术,并现场挑战世界速记大赛亚军得主。据现场最终评测,机器人在准确率上以 0.67%的微弱优势战胜第50 届国际速联速记大赛全球速记亚军姜毅。 对外服务上我们开放了智能语音交互的能力(data.aliyun.com),为企业在多种实际应用场景下,赋予产品“能听、会说、懂你”式的智能人机交互体验。 在法庭庭审方面,我们利用语音识别技术,将庭审各方在庭审过程中的语音直接转变为文字,供各方在庭审页面上查看,书记员简单或不用调整即可作为庭审笔录使用。 大家在目睹直播平台上看云栖大会直播时,上面的实时字幕背后用的也是我们自己的语音识别技术。
参考文献

