TensorRT的集成加速TensorFlow的推理
TensorRT的集成加速TensorFlow的推理
NVIDIA宣布了TensorRT推理优化工具与TensorFlow的集成。TensorRT集成将可用于TensorFlow 1.7分支。TensorFlow是当今最受欢迎的深度学习框架,而NVIDIA TensorRT通过优化和高性能运行时方法加速了基于GPU平台的深度学习推理。我们希望在使用TensorRT的情况下,给TensorFlow的用户使用尽可能高的推理性能和接近透明的工作流程。新的集成提供了一个简单的API,它可以在TensorFlow内使用TensorRT应用强大的FP16和INT8优化。TensorRT在ResNet-50基准测试的低延迟运行中加快了8倍的TensorFlow推理速度。
TensorRT下载地址:https://developer.nvidia.com/nvidia-tensorrt-download
TesnsoRT的介绍文档:https://devblogs.nvidia.com/tensorrt-3-faster-tensorflow-inference/
TensorRT的开发者指南:http://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html
TensorRT的样例代码:http://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html#samples
TensorFlow中的子图优化:
集成优化TensorRT的TensorFlow执行兼容的子图,让TensorFlow执行剩余的图。虽然您仍然可以使用TensorFlow的丰富且灵活的特性集,但TensorRT将尽可能地解析模型并对图的部分应用优化。您的TensorFlow程序只需要几行新代码就可以促进集成。您是准备好使用TensorRT和TensorFlow模型了吗? 接下来,您将了解如何使用TensorRT优化TensorFlow模型需要导出的图表。您可能需要手动导入某些不受支持的TensorFlow层,这在某些情况下可能需要多花点时间。
接下来,让我们逐步了解工作流程。
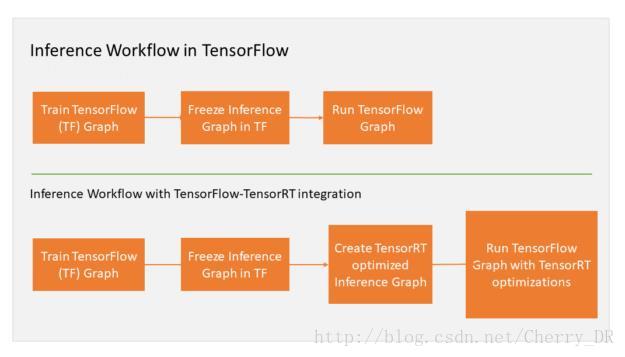
如上图所示,您可以在Freeze Inference Graph in TF 之后,使用TensorRT来优化推理的图。TensorRT会使用优化后的节点来替代每一个可以优化的TensorFlow中的子图。并且,他会产生一个新的Freeze Inference Graph在TensorFlow中执行推理。
TensorFlow会执行所有的流程图,并且会调用TensorRT来执行它优化过的节点。举个例子,假设你的图有三个片段A, B和C。B被TensorRT优化,并且替换成一个优化过的节点。那么TensorFlow在执行完A之后,会调用TensorRT来执行优化过的B,然后才执行C。
从用户的角度来看,您可以像之前一样继续在TensorFlow中工作。接下来,我们来看看应用这个工作流程的一个例子。
新的TensorFlow的API:
让我们看看如何使用新的TensorFlow API将TensorRT优化应用到TensorFlow图表。在现有的TensorFlow GPU代码中添加几行代码:
- 指定TensorFlow使用的GPU内存,TensorRT使用剩余的GPU内存
- 让TensorRT分析TensorFlow的图,优化并用TensorRT的节点替换子图
使用GPUOptions函数新的per_process_gpu_memory_fraction参数指定TensorRT可以使用的剩余内存。该参数应在TensorFlow-TensorRT过程第一次启动时设置。举例来说,如果您将它设为0.67,那么将为TensorFlow分配67%的GPU内存,使剩下的33%可用于TensorRT引擎。
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction = number_between_0_and_1)使用新的create_inference_graph函数将TensorRT的优化应用于冻结图。然后TensorRT将冻结的TensorFlow图作为输入,并返回带有TensorRT节点的优化图。请参阅下面的示例代码片段:
trt_graph = trt.create_inference_graph(
input_graph_def=frozen_graph_def,
outputs=output_node_name,
max_batch_size=batch_size,
max_workspace_size_bytes=workspace_size,
precision_mode=precision)我们来看看函数的参数:
• frozen_graph_def: 冻结TensorFlow的输出图
• put_node_name: 具有输出节点名称的字符串列表例如:“resnet_v1_50/predictions/Reshape_1”
• max_batch_size: 整型变量,输入批次的大小
• max_workspace_size_bytes: 整型变量,TensorRT使用的最大GPU内存
• precision_mode: 字符串,可以使用“FP32”, “FP16” or “INT8”
您应该同时使用per_process_gpu_memory_fraction和max_workspace_size_bytes参数来获得最佳性能。例如,将per_process_gpu_memory_fraction参数设置为(12 - 4)/ 12 = 0.67,将max_workspace_size_bytes参数设置为4000000000,用于12GB的GPU,以便为TensorRT引擎分配4GB的GPU。
在TensorBoard中可视化优化的图形:
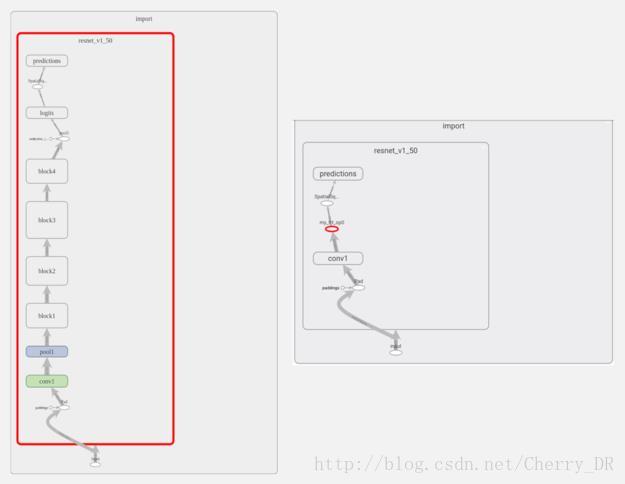
让我们在TensorBoard中应用TensorRT,对ResNet-50节点图的更改可视化。正如您在上图中看到的,TensorRT优化了几乎完整的图,用一个名为“my_trt_op0”的节点替换它(用红色突出显示)。根据您的模型中的层和操作,TensorRT优化过的节点替换了模型的部分内容。
注意:在TensorRT节点下面的名为“conv1”的节点。这实际上不是一个卷积层,而是从NHWC到NCHW的转置操作,它显示为conv1。这是因为TensorBoard只显示层次结构中顶部节点的名称,而不是默认的单个操作。
自动使用Tensor Cores:
与FP32或FP64相比,使用半精度(也称为FP16)算法减少了神经网络的内存使用量。这允许部署更大的网络,并且花费比FP32或FP64传输更少的时间。
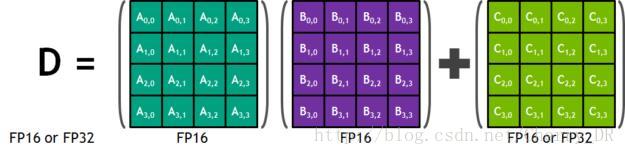
NVIDIA Volta Tensor Cores提供了一个4x4x4矩阵处理数组执行操作D = a * B + C。其中a,B,C,D是4×4矩阵如下图所示。矩阵乘以输入A和B是FP16矩阵,而积累矩阵C和D可以是FP16或FP32矩阵。
在使用半精度算法时,TensorRT会自动在Volta GPU中使用Tensor Cores进行推理。NVIDIA Tesla V100上的Tensor Cores峰值性能比双精度(FP64)快大约10倍,比单精度(FP32)快4倍。只需使用“FP16”作为precision_mode函数中的create_inference_graph参数的值即可启用半精度,如下所示。
trt_graph = trt.create_inference_graph(getNetwork(network_file_name), outputs,
max_batch_size=batch_size, max_workspace_size_bytes=workspace_size, precision_mode="<strong>FP16strong>")如下图所示,使用NVIDIA Volta Tensor Cores与仅运行TensorFlow的TensorFlow-TensorRT集成,ResNet-50在7 ms延迟下执行速度提高了8倍。

优化过的INT8的推理性能
使用INT8精度执行推理可进一步提高计算速度并降低对带宽的要求。降低的动态范围使得表示神经网络的权重和激活成为一项挑战。下面的表说明了动态范围:

TensorRT提供了以完整(FP32)和一半(FP16)精度进行训练的模型,并将它们转换为用于INT8量化的部署,同时将精度损失降至最低。
要将模型转换为使用INT8进行部署,您需要在应用TensorRT的前面章节中介绍的优化之前校准经过训练的FP32模型。剩下的工作流程保持不变。
下图显示了更新过得工作流程:
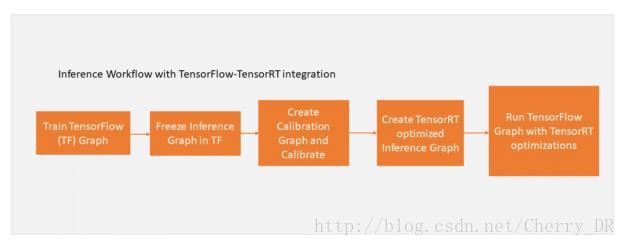
首先使用create_inference_graph函数,并将precision_mode参数设置为“INT8”来校准模型。此功能的输出是一个准备好校准的冻结TensorFlow图。
trt_graph = trt.create_inference_graph(getNetwork(network_file_name), outputs,
max_batch_size=batch_size, max_workspace_size_bytes=workspace_size, precision_mode="<strong>INT8strong>")接下来,用校准数据执行校准图。TensorRT使用节点数据的分布来量化节点的权重。使用校准数据来密切反映生产中问题数据集的分布是很重要的。我们建议在第一次使用与INT8校准的模型时检查错误积累。
在校准数据上执行图形后,使用calib_graph_to_infer_graph函数将TensorRT优化应用于校准图形。该功能还可以用为INT8优化的TensorRT节点替换TensorFlow子图。该函数的输出是一个冻结的TensorFlow图表,可以像往常一样用于推理。
trt_graph=trt.calib_graph_to_infer_graph(calibGraph)就这样,这两个命令启用了TensorFlow模型的INT8精度推断。
您还可以在这里下载全部的代码!!!