深度学习与计算机视觉系列(中)--GAN
深度学习与计算机视觉入门系列(中)
数据嗨客最近发布了一个深度学习系列,觉得还不错,主要对深度学习与计算机视觉相关内容做了系统的介绍,看了一遍,在这里做一下笔记。
目录
-
- 深度学习与计算机视觉入门系列(中)
- 目录
- 深度学习第6期:循环神经网络RNN
- 深度学习第7期:生成对抗网络GAN
- 判别模型与生成模型
- 自回归类的方法,例如Pixel CNN等。
- 自编码类的方法,例如VAE等;
- 对抗生成模型(GAN)
- GAN的变体
- 总结
- 深度学习与计算机视觉入门系列(中)
深度学习第6期:循环神经网络RNN
CNN适用于图片类型的数据,RNN适用于时间序列型的数据。
LSTM相关内容。
深度学习第7期:生成对抗网络GAN
判别模型与生成模型
机器学习的模型大体分为两类,判别模型(Discriminative Model)与生成模型(Generative Model)。判别模型是用来预测或判断输入的类别的。例如给我们一张动物的图片,让我们的分类器判断这个图片里的动物是不是牛,或者判断图片里的动物是什么,这都属于判别模型;而生成模型则是用来随机产生观测数据(或者根据某些随机生成的噪声来生成观测数据)。例如当我们给定一系列牛的图片,然后让我们的生成器根据这类图片再生成一张牛的图片。如果从数学的角度看,判别模型相当于学习一个条件分布P(y|x),而生成模型则相当于在学习一个概率分布P(x)。

对于图片判断类别(Classification)、检测物体的位置与分类(Object Detection)或是分割(Segmentation),都是针对输入的图片进行某些信息的判断的,属于判别模型。
生成模型的损失函数相对难以定义,定位输出的是图片,而不是一张图片的label或者一些像素的label。
目前,能够利用深度学习相关技术实现较好的生成模型的主要方法有三种:
自回归类的方法,例如Pixel CNN等。
自回归类的算法基于一个基本的假设——我们要生成的数据在因果关系上是顺序的。在这个顺序的结构中,前面的元素决定了后面元素的概率分布。也就是说,对于所有的i,我们由模型得到P(xi|x1,x2,…,xi−1),并从中生成出xi。然后,我们再根据x1,x2,…,xi去生成xi+1,并以此类推生成整个序列。
在目前的自然语言处理领域,例如“生成讲话”、“生成同人文”等一类应用中,最常见的生成模型都相当于在使用RNN(例如LSTM或GRU等)进行自回归。其首先学习给定数据集,学习语言的条件概率分布。然后再在随机初始化之后,根据学到的语言概率分布去生成序列。
在图片生成的领域,我们可以假定各个像素之间也是根据一定顺序排列而成的,并且像素之间也有因果的决定关系。例如,我们可以将图片中最左上角的像素命名为1号像素,将它紧邻右边的一个像素命名为2号像素,剩下的根据先从左到右,再从上到下的顺序排列好。然后,我们可以先随机初始化1号像素,接着根据1号像素生成2号像素,根据1、2号像素生成3号,根据1、2、3号像素生成4号。以此类推,生成整个图片。
Pixel-CNN大体上就是根据这种原理设计而成的。
除了图像与自然语言的领域外,还有类似的自回归结构运用在别的领域也取得了成功。例如WaveNet在音频生成上取得了重大成功等。不过要注意的是,与语言、语音这种天然具有序列型的结构相比,将图像中的像素强行组织成这种顺序结构,从逻辑上是有一定不足的。这也导致虽然Pixel-CNN与WaveNet结构几乎差不多,但是目前Pixel-CNN在图片生成的领域远远不具有WaveNet在音频生成领域那样的地位。
自编码类的方法,例如VAE等;
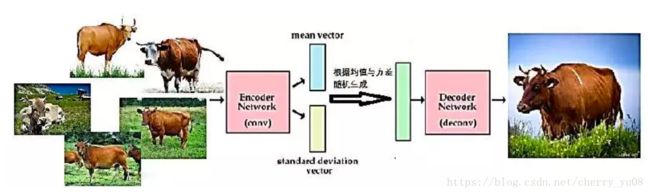
变分自编码(Variational AutoEncoder,简称VAE)的方法,也是利用自编码技术做生成模型的主流。它与一般的自编码稍有不同。我们在使用VAE建立编码器与解码器的时候,不但像一般的自编码器一样考虑让解码后的重建损失尽量小,我们同时还要考虑让编码尽量接近正态分布。在VAE中,我们一般用交叉熵(KL散度)来衡量z的分布与正态分布的差异,KL散度越大则意味着z与正态分布的差异越大,反之则z越接近正态分布。故而在VAE中,我们要优化的损失是一个重建损失与KL散度的和。当VAE优化完成后,我们就得到了一个编码器,可以将我们手头的图片都编码成某个正态分布。而当我们根据该正态分布生成一个新的z时,将其放入我们的解码器进行解码,即可得到生成的图片。如下图所示:
总结:
我们已经介绍了自回归与VAE这两种常见的生成模型的思想。我们想象图片是一个高维数据(x1,x2,…,xn),我们要求的是其联合分布P(x1,x2,…,xn)。自回归的方法相当于将这个联合分布分解为一系列条件分布的连乘,即:
![]()
而VAE的方法则相当于将这个联合分布分解为隐变量的分布与关于隐变量的条件分布的乘积,即:

而GAN与上述二者不同。它相当于是“直接”解出联合分布P(x1,x2,…,xn)。与上述二者相比,它在数学上的含义是更加模糊的。但是目前,它的效果是最好的。
对抗生成模型(GAN)
我们有许多牛的图片,而我们希望利用深度学习技术来造这样一个生成模型——当我们输入一个随机产生的噪声图片,它通过我们的网络后,就能够变成一个“像模像样”的牛。 然而,深度学习技术本身是一种优化的技术。如果我们有一个“标准图片”,我们可以衡量输出与标准图片的距离,作为需要优化的损失。这样,经过多次训练之后,我们网络就可以把噪声输入给变得接近于标准图片一样输出。但是,在前面我们也已经说过了,上述的“标准图片”是不存在的。我们不知道何种损失才能衡量“是否像一头牛”。 GAN的想法是,既然我们不明白如何定义一个损失去衡量“是否像一头牛”,我们不妨将其想象成一个极其复杂的函数。既然是一个复杂的函数,则我们就可以用另外一个神经网络去拟合它。如果我们有一个完美的神经网络,判断一个图片“是否像一头牛”,则我们就可以根据这个网络提供的损失优化我们的生成网络。这事实上就是GAN的主要思想。 GAN的设计如下:它同时训练一个生成网络G与一个判别网络D。G的作用是接受随机的高维噪音作为输入,输出一个尽量像牛的图片。而我们将G网络输出的、企图伪装为牛的图片,增加一个“假”的标签,而将训练集里的牛的图片增加一个“真”的标签。将这一组混合了“真牛”与“假牛”的图片交给D网络,令其学习如何分别一个图片是否是真的牛。训练的过程就好像是一个对抗的过程,D是“火眼金睛”的警察,努力想辨别出G“造假”的图片;而G则是“以假乱真”的骗子,努力打磨自己的技术,企图有一天能够骗过D的眼睛,造出和训练集一模一样的图片。其示意图如下:

对于D而言,其训练是相对简单的。它的训练集是许多有标记的数据集,包括被标记为“真”的现实中牛的图片与被标记为“假”的G造出来的图片。我们可以建立一个CNN,其输入为图片,输出为一个经过压缩函数(Sigmoid或tanh)压缩到0与1之间的数,表示其为真的概率;也可以让其输出两个数,经过softmax之后,得到其为真的概率与为假的概率。总之,这可以做为一个二分类问题,或是一个回归问题,比较简单。
而对于G而言,其训练相对复杂。它的输入是高维噪声z,输出是造假的图片G(z)。在监督学习问题中,我们有一个标签L,我们的目的是让损失(L−G(z))2尽量接近0。而这里,我们没有标签L,我们只有判断输出是否为真的函数D。所以此处我们的目的是让D(G(z))尽量接近1。通过回传损失log(1-D(G(z)))可以达到目的。
Goodfellow创立GAN的第一篇论文《Generative Adversarial Nets》中明确了其严格的数学定义:

理论上而言,GAN的训练是一个min-max的过程,即训练最终要优化的目标是:
![]()
这意味着,我们要在D做到最好的情况下,来优化G。
这意味着,我们要在D做到最好的情况下,来优化G——这是合乎情理的——因为我们对G的训练是为了让它能够迎合D的判断。如果D的判断能力完全和人眼一模一样,而你让G去努力迎合D的判断,就是让G往正确的方向学习;而如果D完全是瞎判断,则你让G去迎合D的判断,起不到任何效果。一般来说,D越好的时候你让G去学习迎合它的判断就越有意义。这就仿佛是面对强大的对手时候,才能有效地提升自己。而面对太弱小的对手时,即使熟练地学会了击败他的方法,也毫无意义。
但是另一方面,如果D太强大而G太弱,也是无法训练的。因为D会将G(z)及其邻域都判断为0,导致G找不到更新的方向。这就好像遇到了强大的对手,你如何微调自己的技巧,都没有使得自己获胜的希望增加一点。这也是对于提升自己不利的。
所以,在GAN的训练过程中,为了求出上述的min-max点,我们一般同时、交替地训练两个网络。对D网络进行梯度上升,对G网络进行梯度下降。这样一来,两个网络就可以同时成长、同时提高。每个阶段他们都可以从与自己同等水平的对手进行对抗。训练初期,不太强大的G在努力学习造假,以骗过不太强大的D的眼睛;而不太强大的D则在努力学习辨认,企图找出不太强大的G造的赝品;等到了训练末期,强大的G已经可以造出以假乱真的图片,而强大的D也火眼金睛地能够察觉赝品中不起眼的细节。由于训练的过程充满了对抗性,所以被称为Generative Adversarial Nets,这也是GAN名字的由来。
GAN的变体
CGAN(Conditional Generative Adversarial Nets):
同样对于MINIST数据集的数字字体生成,CGAN尝试比普通的GAN更进一步。它希望能够接受一个人为指定的数字作为输入,然后输出对应的字体。
在CGAN中,人们实现了人为调整输入,以获得所需输出这样的功能。但是,这毕竟还是一个有监督学习的过程,我们需要人为地对训练数据加上标签,才能实现这一点。
Info-GAN:
一个无监督学习过程,让GAN自己学习特征。
在Goodfellow发明了基础版的GAN之后,许多人对其进行了改进。其中比较有代表性的改进除了CGAN、Info-GAN外,还有LAPGAN、DCGAN、GRAN、VAEGAN等等。
这里我们再展示几个用GAN及其变体可以达到的神奇效果。例如生成的卧室图片:

例如用包含戴眼镜的男人、不带眼镜的男人,以及不戴眼镜的女人,生成戴眼镜的女人的图片:

例如根据客户给的涂鸦,生成一张风景图:

总结
本文中,我们主要介绍了生成模型。生成模型是为了学习一个分布,而判别模型是为了学习一个条件分布;生成模型一般接受低维输入,输出高维的结果,而判别模型一般接受高维输入,输出低维的结果。从各个角度来看,生成模型都比判别模型要更难。这也是目前针对生成模型的研究少于判别模型的主要原因。但是随着技术的发展,越来越多研究者开始将目光聚焦于生成模型的领域。
目前主要有三种利用深度学习的生成模型。第一种是自回归的模型,例如生成文字的LSTM、生成图片的Pixel-CNN,以及生成音频的WaveNet等等。它试图将一个联合分布拆开成为一系列条件分布的乘积,加以学习;第二种是VAE,它企图将联合分布拆开为隐含变量的分布以及数据关于隐含变量的分布,利用自编码的技术加以学习;第三种即是我们重点介绍的GAN,它企图直接学习整个数据的联合分布,是一种最接近于深度学习思维的算法。具体而言,它用一个D网络来学习数据联合分布的密度,用一个G网络来学习将低维噪声往数据联合分布的映射方式。它让二者同时训练、相互对抗、共同进步,使得最后G网络能够很好地生成以假乱真的数据。
GAN有许多变体,而我们主要介绍了CGAN与Info-GAN两种。它们都试图让输入的数据具有一定的意义,以实现通过人为调节输入来控制输出。具体而言,CGAN采取的是有监督学习的策略,需要将数据人为标注上人们能够理解的的数据特性;而Info-GAN则采取的是无监督学习的策略,希望网络可以自己学习到数据的一些特性。当Info-GAN学习完毕后,我们也常常能够看得出来其自主学习到的数据特性是什么,这正是其神奇之处。如果同学们想了解更多有关GAN的内容,可以自行查阅有关资料。