R语言关联分析
说明
在进行关联规则挖掘前,我们需要首先将数据转换成事务数据。讨论三种常用数据集,包括链表,矩阵,数据框架。然后将它们转化成事务数据。
操作
导入arulesm创建一个包括三个向量的链表,以存放购买记录
tr_list = list(c("apple","bread","cake"),
c("apple","bread","milk"),
c("bread","cake","milk"))
names(tr_list) = paste("Tr",c(1:3),sep = "")调用as函数,将链表转化成事务类型:
trans = as(tr_list,"transactions")
trans
transactions in sparse format with
3 transactions (rows) and
4 items (columns)
将矩阵格式的数据转换成事务类型:
tr_matrix = matrix(
c(1,1,1,0,
1,1,0,1,
0,1,1,1),ncol = 4)
dimnames(tr_matrix) = list(
paste("Tr",c(1:3),sep = ""),
c("apple","bread","cake","milk")
)
trans2 = as(tr_matrix,"transactions")
trans2
transactions in sparse format with
3 transactions (rows) and
4 items (columns)最后将数据框类型的数据集转换成事务:
Tr_df = data.frame(
TrID = as.factor(c(1,2,1,1,2,3,2,3,2,3)),
Item = as.factor(c("apple","milk","cake","bread","cake","milk","apple","cake","bread","bread"))
)
trans3 = as(split(Tr_df[,"Item"],Tr_df[,"TrID"]),"transactions")
trans3
transactions in sparse format with
3 transactions (rows) and
4 items (columns)原理
讨论了一个数据集从链表,矩阵,数据框转换成事务。
展示事务及关联
R的arule包使用自带的transactions类型来存储事务型数据,因此,我们必须调用arule包提供的各种函数来展示事务及其关联关系规则。
获取事务数据的LIST表示:
LIST(trans)
$Tr1
[1] "apple" "bread" "cake"
$Tr2
[1] "apple" "bread" "milk"
$Tr3
[1] "bread" "cake" "milk"
调用summary函数输出这些事务的统计及详细信息:
summary(trans)
transactions as itemMatrix in sparse format with
3 rows (elements/itemsets/transactions) and
4 columns (items) and a density of 0.75
most frequent items:
bread apple cake milk (Other)
3 2 2 2 0
element (itemset/transaction) length distribution:
sizes
3
3
Min. 1st Qu. Median Mean 3rd Qu. Max.
3 3 3 3 3 3
includes extended item information - examples:
labels
1 apple
2 bread
3 cake
includes extended transaction information - examples:
transactionID
1 Tr1
2 Tr2
3 Tr3
调用inspect函数展示事务:
inspect(trans)
items transactionID
[1] {apple,bread,cake} Tr1
[2] {apple,bread,milk} Tr2
[3] {bread,cake,milk} Tr3 根据事务大小进行筛选:
filter_trains = trans[size(trans) >= 3]
inspect(filter_trains)
items transactionID
[1] {apple,bread,cake} Tr1
[2] {apple,bread,milk} Tr2
[3] {bread,cake,milk} Tr3 调用image函数可视化检查事务数据:
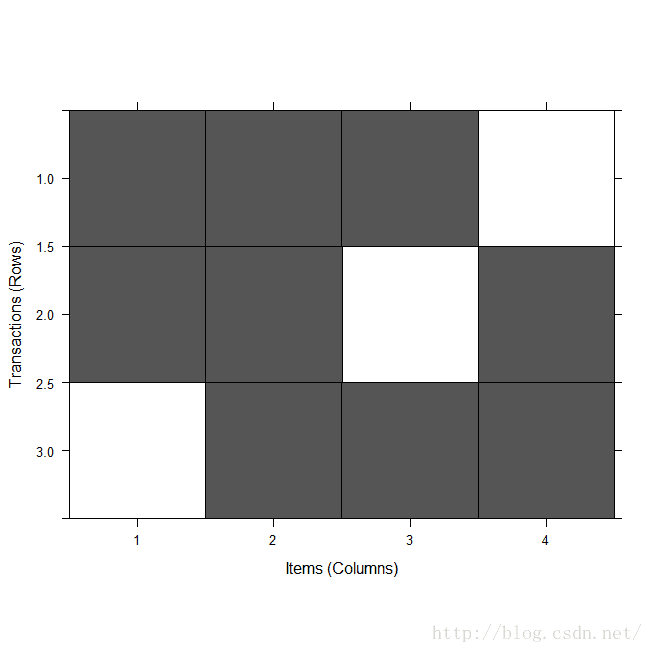
对事务可视化
调用itemFrequentPlot函数绘制频繁度/支持度条形图
itemFrequencyPlot(trans)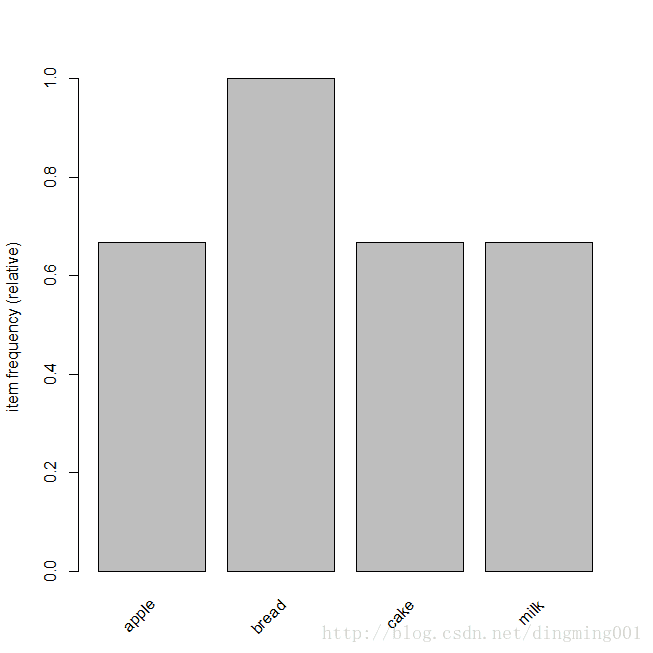
事物的项频繁度条形图
交易数据是挖掘关联和频繁模式的基础。arules包提供了多种检查交易数据的方法,我们首先使用LIST函数以及链表形式来展示交易数据,然后调用summary函数来获取包括基本属性描述,最频繁项集以及事务长度分布的信息。
接下来用inspect函数来显示这些交易数据,读者还可以通过交易数据大小来对 数据进行筛选,并使用inspect函数显示数据之间的关联,还可以调用image函数对检查的数据进行可视化处理。最后通过条形图显示各项集之间的相关项集成度。