老赵谈IL(3):IL可以看到的东西,其实大都也可以用C#来发现
2009-06-06 00:04 Jeffrey Zhao 阅读(...) 评论(...) 编辑 收藏在上一篇文章中,我们通过一些示例谈论了IL与CLR中的一些特性。IL与C#等高级语言的作用类似,主要用于表示程序的逻辑。由于它同样了解太多CLR中的高级特性,因此它在大部分情况下依旧无法展现出比那些高级语言更多的CLR细节。因此,如果您想要通过学习IL来了解CLR,那么这个过程很可能会“事倍功半”。因此,从这个角度来说,我并不倾向于学习IL。不过严格说来,即使IL无法看出CLR的细节,也不足以说明“IL无用”——这里说“无用”自然有些夸张。但是,如果我们还发现,那些原本被认为需要通过IL挖掘到的东西,现在都可以使用更好的方法来获得,并且可以起到“事半功倍”的效果,那么似乎我们真的没有太多理由去追逐IL了。
在这篇文章中,我们使用最多的工具便是.NET Reflector,从.NET 1.x开始,.NET Reflector就是一个探究.NET框架(主要是BCL)内部实现的有力工具,它可以把一个程序集高度还原成C#等高级语言的代码。在它的帮助下,几乎所有程序集实现都变得一目了然,这大大方便了我们的工作。我对此深有感触,因为在某段不算短的时间内,我使用.NET Reflector阅读过的代码数量远远超过了自己编写的代码。与此相反的是,我几乎没有使用IL探索过.NET框架下的任何问题。这可能还涉及到方式方法和个人做事方式,但是如果这真有效果的话,为什么要舍近求远呢?希望您看过了这篇文章,也可以像我一样摆脱IL,投入.NET Reflector的怀抱。
示例一:探究语言细节
C#语言从1.0到3.0版本的进化过程中,大部分新特性都是依靠编译器的魔法。就拿C#3.0的各种新特性来说,Lambda表达式,LINQ,自动属性等等,完全都是基于CLR 2.0中已有的功能,再配合新的C#编译器而产生的各种神奇效果。有些朋友认为,掌握IL之后便把握了.NET的根本,以不变应万变,只要读懂IL,那么这些新特性都不会对您形成困扰。这话说的并没有错,只是我认为,“掌握IL”在这里只是一个“充分条件”而不是一个“必要条件”,我们完全可以使用.NET Reflector将程序集反编译成C#代码来观察这些。
这里我们使用.NET Reflector来观察最最常见,最最普通的foreach关键字的功能。我们都知道foreach是遍历一个IEnumerble对象内元素的方式,我们也都知道foreach其实是GoF Iterator模式的实现,通过MoveNext方法和Current属性进行配合共同完成。不过大部分朋友似乎都是从IL进行观察,或是“听别人说”而了解这些的。事实上,.NET Reflector也可以很容易地证实这一点,只是这中间还有些“特别”的地方。那么首先,我们还是来准备一个最简单的foreach语句:
static void DoEnumerable(IEnumerable<int> source) { foreach (int i in source) { Console.WriteLine(i); } }
如果观察它的IL代码,即使不了解IL的朋友也一定可以看出,其中涉及到了GetEnumerator,MoveNext和Current等成员的访问:
.method private hidebysig static void DoEnumerable(
class [mscorlib]System.Collections.Generic.IEnumerable`1
source) cil managed
{
.maxstack 1
.locals init (
[0] int32 i,
[1] class [mscorlib]System.Collections.Generic.IEnumerator`1
CS$5$0000)
L_0000: ldarg.0
L_0001: callvirt instance class [mscorlib]System.Collections.Generic.IEnumerator`1
[mscorlib]System.Collections.Generic.IEnumerable`1
::GetEnumerator()
L_0006: stloc.1
L_0007: br.s L_0016
L_0009: ldloc.1
L_000a: callvirt instance !0 [mscorlib]System.Collections.Generic.IEnumerator`1
::get_Current()
L_000f: stloc.0
L_0010: ldloc.0
L_0011: call void [mscorlib]System.Console::WriteLine(int32)
L_0016: ldloc.1
L_0017: callvirt instance bool [mscorlib]System.Collections.IEnumerator::MoveNext()
L_001c: brtrue.s L_0009
L_001e: leave.s L_002a
L_0020: ldloc.1
L_0021: brfalse.s L_0029
L_0023: ldloc.1
L_0024: callvirt instance void [mscorlib]System.IDisposable::Dispose()
L_0029: endfinally
L_002a: ret
.try L_0007 to L_0020 finally handler L_0020 to L_002a
}
但是,如果使用.NET Reflector观察它的C#代码又会如何呢?
private static void DoEnumerable(IEnumerable
source)
{
foreach (int i in source)
{
Console.WriteLine(i);
}
}
请注意,以上这段是由.NET Reflector从IL反编译后得到的C#代码,这简直……不是简直,是完完全全真真正正地和我们刚才写的代码一模一样!这就是.NET Reflector的强大之处,由于它意识到IL调用了IEnumerable
刚才我提到,.NET Reflector在判断IL代码时发现一些标准的模式时会进行代码“优化”。那么我们能否让.NET Reflector不要做这种“优化”呢?答案是肯定的,只是需要您在.NET Reflector中进行一些简单的设置:
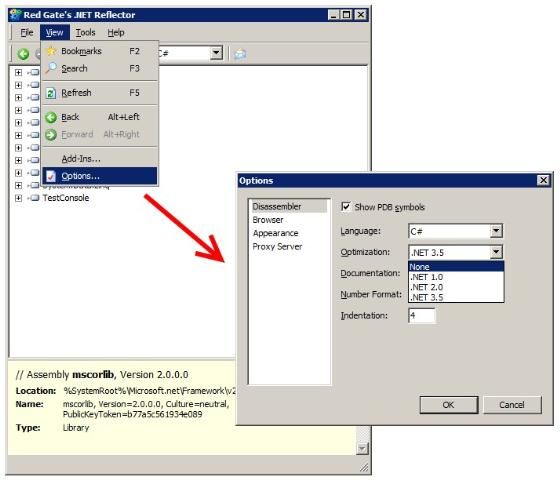
打开View菜单中的Options对话框,在左侧Disassembler选项卡中修改Optimization级别,默认很可能是.NET 3.5,而现在我们要将其修改为None。这么做会让.NET Reflector最大程度地“直接”翻译IL代码,而不做一些额外优化。将Optimization级别设为None以后,DoEnumerable方法的代码就变为了:
static void DoEnumerable(IEnumerable<int> source) { int num; IEnumerator<int> enumerator; enumerator = source.GetEnumerator(); Label_0007: try { goto Label_0016; Label_0009: num = enumerator.Current; Console.WriteLine(num); Label_0016: if (enumerator.MoveNext() != null) { goto Label_0009; } goto Label_002A; } finally { Label_0020: if (enumerator == null) { goto Label_0029; } enumerator.Dispose(); Label_0029: ; } Label_002A: return; }
这是C#代码吗?为什么会有那么多的goto?为什么MoveNext方法返回的布尔值可以和null进行比较?其实您把这段代码复制粘贴后会发现,它能够正常编译通过,效果也和刚才的foreach语句完全一样。这就是去除“优化”的效果。我在上一篇文章中谈到说:IL和C#一样,都是用于表现程序逻辑。C#使用if...else、while、for等等丰富语法,而在IL中就会变成判断+跳转语句。上面的C#代码便直接保留了IL的这个“特性”。不过还好,我们还是可以看出try...finally,可以看出MoveNext方法和Current属性的访问,可以看到程序使用Console.WriteLine输出数据。至此,我们便发现了foreach语句的真面目。从现在开始,在您准备深入IL之前,我也建议您可以尝试一下使用None Optimization来观察C#代码。
实事求是地说,上面的C#代码的“转向逻辑”并不那么清晰,因此您在理解的时候可以把它复制到编辑器中,进行一些简单调整。但是从我的经验上来看,需要使用None Optimization进行探索的地方非常少见。foreach是一个,还有便是C#中的其他一些“别名”,如使用using关键字管理IDisposable对象,以及lock关键字。而且,其实这段逻辑也只是没有优化IL中的跳转语句而已,已经比IL本身要直观许多了。此外,关于对象创建,变量声明,方法调用,属性访问,事件加载……一切的一切都还是最常用的C#代码。因为还是那个原因:从大部分情况上来看,IL也只是表现了程序逻辑,并没有比C#等语言体现出更多的细节。
我在这里举了一个较为极端的例子,因为我发现不少朋友并没有尝试过使用None Optimization来观察过代码。这里也可以看出,.NET Reflector的“优化级别”还不够“细致”。不过这应该是一个“产品设计”的正常结果,因为foreach/using/lock的关键字都是从.NET 1.0诞生伊始就存在的,也就是说,即使.NET Reflector选择将IL编译为C# 1.0,它的表现形式依旧是“标准模式”,这方面可能就不能过于强求了吧。至于其他一些探索,例如C#中的自动属性,Lambda表达式构建表达式树或匿名委托,乃至C# 4.0中的dynamic关键字,都是使用.NET 3.5 Optimization进行探索便可得知的结果。您可以回忆一下自己看过的文章,其中有多少是使用IL解释问题的呢?
示例二:学习.NET平台上的其他语言
在.NET平台上,任何语言都会先编译为IL,然后再运行时由JIT转化为机器码。因此有种说法是,只要把握了IL,.NET平台上各种语言之间的迁移都会变得容易。对此我有不同看法。在以前讨论语言是否重要的时候,我提到,语言它并不仅仅是一种文字表现形式,而是一种“思维方式”的改变,这可能会影响到您程序的编码风格,API设计乃至架构(这个链接可能打不开,因为……)。实际上,如果您只是在C#与VB.NET之间进行迁移,原本就是一件相当容易的事情,因为它们之间“语言”的各种概念和特性都非常接近。而一种改变您思维的语言,才是真正有价值,而且值得进行比较和探索的。如果一味地追求“把握本源”,那么甚至还有比IL更低抽象的事务,但这些就已经违背了“创造一门语言”,以及您学习它的目的了,不是吗?
当然,探索也是需要的,尤其是.NET平台上的各种语言,他们被统一在同样的平台上,这本身就是一种很好的资源。这种资源就是所谓的“比较学习”。您可以把新的语言和您熟悉的语言进行对比,吸收其中的长处(如优秀的思维方式),这样便可以更好地使用旧有语言。例如,您把F#类库转化为C#代码进行观察之后,发现其中大量函数式编程风格的API是使用“委托”来实现的,您可能就会想到是否可以设计出函数式编程风格的C# API,是否可以把F#中List或Seq模块中的各种高阶函数移植到您自己的项目中来。这就有了更好的价值,这价值也不仅仅只是您“学会了新的语言”。
例如,我们现在使用尾递归来计算斐波那契数列。在之前的文章中,我们的作法是:
private static int FibTail(int n, int acc1, int acc2) { if (n == 0) return acc1; return FibTail(n - 1, acc2, acc1 + acc2); } public static int Fib(int n) { return FibTail(n, 0, 1); }
为了“尾递归”,我们必须定义一个私有的FibTail方法,接收三个参数。而对外的接口还是一个公有的Fib方法,它返回斐波那契数列第n项的结果。这个示例很简单,作法也没有任何问题。但是我有时候会觉得,我们为什么非要定义一个额外的“辅助方法”,然后在现有的方法里只是进行一个简单的转发?如果这个辅助方法会在其他地方得到调用也就罢了(我们遵守了DRY原则),但是现在却有点“平白无故”地在代码里增加了一个方法,这样在VS的Class View或编辑器上方的下拉列表中也会多出一项。此外,为了表示两个方法的关系,您可能还会使用region把它们包裹起来……
不过在F#中,上面的尾递归就可以这样写:
let fib n = let rec fibTail x acc1 acc2 = match x with | 0 -> acc1; | _ -> fibTail (x - 1) acc2 (acc1 + acc2) fibTail n 0 1
在fib方法内部,我们可以重新定义一个fibTail方法,其中实现了尾递归。对于外部来说,只有fib方法是公开的,外界丝毫不知道fibTail方法的存在,这种定义内部函数的作法在F#中非常常见。而编译后,我们在.NET Reflector中便可看到与之对应的C#实现:
public static int fib(int n) { switch (n) { case 0: return 0; } return fibTail@7@7(n - 1, 1, 1); } internal static int fibTail@7@7(int x, int acc1, int acc2) { ... }
在F#中没有internal的访问级别,您可以认为这里internal便是private。于是我们得知(可能您本身也猜得到):由于.NET本身并没有“嵌套方法”特性,因此在这里编译器会重新生成一个特殊的私有方法,并且在fib方法里进行调用。于是我们想到,这个“自动生成方法”的特性,在C#中也有体现啊。例如,IEnmuerable
public static int Fib(int n) { Func<int, int, int, int> fibTail = null; fibTail = (x, acc1, acc2) => { if (x == 0) return acc1; return fibTail(x - 1, acc2, acc1 + acc2); }; return fibTail(n, 0, 1); }
如果没有F#的“提示”,可能我们只能想到list.Where(i => i % 2 == 0)这种形式的用法,我们平时不会在方法内部额外地“创建一个委托”,然后加以调用,而且还用到了“递归”——甚至还是“尾递归”(虽然C#编译器在这里没有进行优化,而且这里其实也只是个“伪递归”,因为fibTail其实是个可改变的“函数指针”)。不过,由于我们刚才通过C#来观察F#的编译结果,联想到它和我们以前观察到的C#中“某个特性”非常相似,再加上合理的尝试,最终同样得出了一个还算“令人满意”的使用方式。
这只是一个示例,我并不是说这种作法是所谓的“最佳实践”。任何办法一旦遭到滥用也肯定不会有好处,您要根据当前情况判断是否应该采取某种作法。刚才的演示只是为了说明,我们应该如何从其他语言中吸取优势思想,改进我们的编程工作。当然,您使用IL来探索新的语言也没有太大问题,C#能看到的东西用IL也可以看到。但是请您回想一下,即使您平时学习IL,您想过直接使用IL来写程序吗?您学习和探索新语言的目的,只是为了搞清楚它的IL表现形式吗?为什么您不使用简单易懂的C#,却要纠缠于IL中那些纷繁复杂的指令呢?
示例三:性能相关
学习IL对写出高性能的.NET程序有帮助吗?
记得以前在学习“计算机系统概论”课程时,有一个实验就是为几段C程序进行优化。当时的手段可谓无所不用其极,例如内联一个子过程以避免call指令的消耗,或把一段C代码使用汇编进行替换等等。从结果上看,它们都能对性能有“明显”的提高。不过,那些都是为了加深概念而进行的练习,并不是说在现代程序中应该使用这种方式进行优化。现在早已不是在“指令级别”进行性能优化的时期了,连操作系统内核也只是在一些对性能要求非常高的地方,如内存管理,线程调度中的细微方面使用汇编来编写,其余部分也都是用C语言来完成。这并不是仅仅是因为“可维护性”等考虑,也有部分原因是因为在目前编译技术的发展下,一些极端的做法已经很难产生有效的优化效果了(例如一般来说来,程序员写出的C代码的性能会优于他写的汇编代码)。
此外,在您不知道JIT究竟作了什么事情的情况下,观察IL这样一种高度抽象的语言,您还是无法真正判断出一个程序从微观上的性能如何。不过这并不是说,现代程序不应该“主动”追究性能,而是说,现代程序在性能优化问题上并非如此简单,它涉及到的东西会更多,需要更加合适的手段。例如,即使您内联了一个子过程,也只是减少了call指令的所带来的消耗,但是这与这个子过程本身“一长串”指令相比,所带来的提高是微乎其微的。而如果您一旦破坏了Locality或造成了False Sharing,或造成了资源竞争等等,这可能就会造成数倍甚至更多的性能损耗。换句话说,影响现代应用程序的性能的因素大都是“宏观”的,用通俗的话来说,一般都是“写法”上造成的问题。
这也是为什么说“Make clean code fast”远比“Make fast code clean”来的容易,现代程序更注重的是“清晰”而并非是“性能”。因为程序清晰,更容易让人发现性能瓶颈究竟在何处,可以进行有针对性地优化(即使是那种在极端性能要求下故意进行的“丑陋”写法,也是为了高性能而“丑陋”,而不是因为“丑陋”而高性能,分清这一点很重要)。换句话说,如果我们有一种更清晰地方式来查看同样的程序实现,不也降低了探索程序性能瓶颈的难度吗?那么,同样一段程序,您会通过C#进行观察,还是使用IL呢?
有朋友可能会说:即使无法把握JIT对于IL的优化,但是从IL中可以看出高级语言,如C#的编译器的优化效果啊。这话本没有错,但问题还是在于,C#的编译器优化效果,是否在“反编译”回来之后就无法观察到了呢?“优化过程”往往都是不可逆的,它会造成信息丢失,导致我们很难从“优化结果”中看出“原始模样”,这一点在上一篇文章中也有过论述。换句话说,我们通过C# => IL => C#这一系列“转化”之后,几乎都可以清楚地发现C#编译器做过哪些优化。这里还是使用经典的foreach作为示例,您知道以下两个方法的性能高低如何?
static void DoArray(int[] source) { foreach (int i in source) { Console.WriteLine(i); } } static void DoEnumerable(IEnumerable<int> source) { foreach (int i in source) { Console.WriteLine(i); } }
经过了C#编译器的优化,再使用.NET Reflector查看IL反编译成C#(None Optimization)的结果,就会发现它们变成了此般模样:
private static void DoArray(int[] source) { int num; int[] numArray; int num2; numArray = source; num2 = 0; goto Label_0014; Label_0006: num = numArray[num2]; Console.WriteLine(num); num2 += 1; Label_0014: if (num2 < ((int)numArray.Length)) { goto Label_0006; } return; } private static void DoEnumerable(IEnumerable<int> source) { int num; IEnumerator<int> enumerator; enumerator = source.GetEnumerator(); Label_0007: try { goto Label_0016; Label_0009: num = enumerator.Current; Console.WriteLine(num); Label_0016: if (enumerator.MoveNext() != null) { goto Label_0009; } goto Label_002A; } finally { Label_0020: if (enumerator == null) { goto Label_0029; } enumerator.Dispose(); Label_0029: ; } Label_002A: return; }
C#编译器的优化效果表露无遗:对于int数组的foreach其实是被转化为类似于for的下标访问遍历,而对于IEnumerable
不过,判断两者性能高低,最简单,也最直接的方式还是进行性能测试。例如您可以使用CodeTimer来比较DoArray和DoEnumerable方法的性能,一目了然。
值得一提的是,如果要进行性能优化,需要做的事情有很多,而“阅读代码”在其中的重要性其实并不高,而且它也最容易误入歧途的一种。“阅读代码”充其量是一种人工的“静态分析”,而程序的运行效果是“动态”的。这篇文章解释了为什么使用foreach对ArrayList进行遍历的性能会比List
其实我对于性能方面说的这些,可以大致归纳为以下三点:
- 关注IL,对于从微观角度观察程序性能很难有太大帮助,因为您很难具体指出JIT对IL的编译方式。
- 关注IL,对于从宏观角度观察程序性能同样很难有太大帮助,因为它的表述能力不会比C#来的直观清晰。
- 性能优化,最关键的一点是使用Profiler来找出性能瓶颈,有的放矢。
所以,如果您问我:“学习IL,对写出高性能的.NET程序有帮助吗?”我会回答:“有,肯定有啊”。
但是,如果您问我:“我想写出高性能的.NET程序,应该学习IL吗?”我会回答:“别,别学IL”。
总结
feilng在前文留下的一些评论,我认为说得非常有道理:
IL只是在CLR的抽象级别上说明干什么,而不是怎么干……重要的是要清楚在现实条件下,需要进入那个层次才能获取足够的信息,掌握接口的完整语义和潜在副作用。
IL的确比C#等高级语言来的所谓“底层”,但是很明显,IL本身也是一种高级抽象。而即使是机器码,它也可以说是基于CPU的抽象,CPU上如流水线,并行,内存模型,Cache Lock等东西对于汇编/机器码来说也可以说是一种“封装”。从不同层次可以获得不同信息,我们追求“底层”的目的肯定也不是“底层”这两个字,而是一种收获。了解自身需要什么,然后能够选择一个合理的层次进入,并得到更好的收益,这本身也是一种能力。追求IL的做法,本身并没有错,只是追求IL一定是当前情况下的最优选择吗?这是一个值得不断讨论的问题,我的这篇文章也只是表达了我个人对某些问题的看法。
相关文章
- 老赵谈IL(1):IL是什么,它又不是什么?那么汇编呢?
- 老赵谈IL(2):CLR内部有太多太多IL看不到的东西,包括您平时必须了解的那些
- 老赵谈IL(3):IL可以看到的东西,其实大都也可以用C#来发现
- 老赵谈IL(4):什么时候应该学IL,该怎么学IL