独家 | 知识图谱技术在司法领域的应用:国双科技的探索与技术分享

[导读] 知识图谱技术日益成为人工智能的基础,它是机器理解自然语言和构建知识网络的重要方法。近年来,知识图谱在司法领域的运用悄然兴起,它帮助从业人员快速地在线检索相关的法务内容,从而提高法院审判工作质量和效率。
本期清华大数据“应用·创新”系列讲座,我们邀请到来自国双科技的专家舒怡和曾祥辉分享知识图谱在司法领域应用的探索。
后台回复关键词“0920”,下载完整版讲座PPT。

国双科技 舒怡
舒怡:很开心能够来到清华进行分享,首先讲一下我对知识图谱的理解和认识。

我认为数据、信息和知识的共享传播已经创造了极大的市场价值,但是在知识的处理上还有很大的挖掘空间。我们认为知识图谱在现阶段要解决的问题就是实现数据和信息的智能化处理,让计算机像人一样用知识处理信息。
知识图谱在司法领域的探索和应用
1、知识图谱的定义
业界普遍使用图作为表示知识的数据结构,因此称为知识图谱。
结点-边-节点组成了表示知识和事实的陈述语句。
知识和事实陈述语句关联起来,可以表达领域的专业知识。
2、知识图谱的特点
知识图谱在语义层面表示客观世界的知识和事实。
集成(空间)。它是一个空间的概念,可以把相关的概念和实体用任何的维度去描述,组成一个整体。
积累(时间)。我们可以逐步增加知识图谱上的知识结点,新的知识结构和知识内容能够自然累积成一个完整的知识结构。
总体来说,我们认为知识图谱最大的作用就是降低了结构化知识的构建和使用难度。
3、司法知识图谱是司法智能应用的必然路径
知识图谱表达的知识方法与人类认知的模式相一致。与自然语言表达语义的方式相一致,对领域的概念分类、分层也一致,可以叠加无限的维度,允许知识与语言相对独立的相关性。这其实跟知识图谱技术、方法的本质有关系。
法律知识体系是多种逻辑的结合。法律的知识体系非常复杂,可以从法律法规自上而下构建体系,也可以从法学概念的相关性去构建体系。
成文法体系。我们国家是一个成文法体系的国家,它跟英美不同,不是遵循先例的角度去看。这就有了一个条件,我们可能用一种比较统一的方法去处理整个中国的法律知识。
专业领域的知识图谱的构建和百科类知识的融合和构建不同,需要非常严格的专家指导和监督。如果说百度类的知识图谱搭建属于起步阶段,那么专业领域内的知识图谱构建更是处于初级阶段,要经历非常长时间的发展。
4、司法知识体系建设思路
我们的思路就是把应用当成知识图谱构建的钥匙,每一种法学领域内的应用都是一把触动不同结点的钥匙,应用的结果都是结点上概念与属性的预算。
司法知识:
法律概念知识
司法实践知识
司法实践涉及的领域知识
一般社会知识
我们对于法律的概念知识对接的是传统的知识库,而司法的实践知识是通过批量的文书处理和专家的干预去构建,以应用为导向,小规模进行突破。司法实践涉及的领域知识是以专家构建为主,以应用为导向,在一定的领域内做,而一般的社会知识对接的是百科的数据库。
5、怎么去对接传统的数据库呢?

我们现在所接触的传统数据库,就是法律类的专业数据库,很多是以树状结构去做。第一,它的构建逻辑单一;第二,分层的随意性大,第三层级之间的关系比较乱。右边红框,它的层级有的之间是父子包含关系,有的之间是并列关系;而左边红框的层级非常多,必须用目录索引才能很好的使用它的知识库。
如果我们把已经做好了的传统知识库去复建知识图谱,成本比较高。我们是以尊重现有的传统知识库为基础,将主要的精力放在两个方面:
第一方面,探索多个不同逻辑传统知识库的知识融合。
第二方面,在弱化层级的概念上。(举例略)
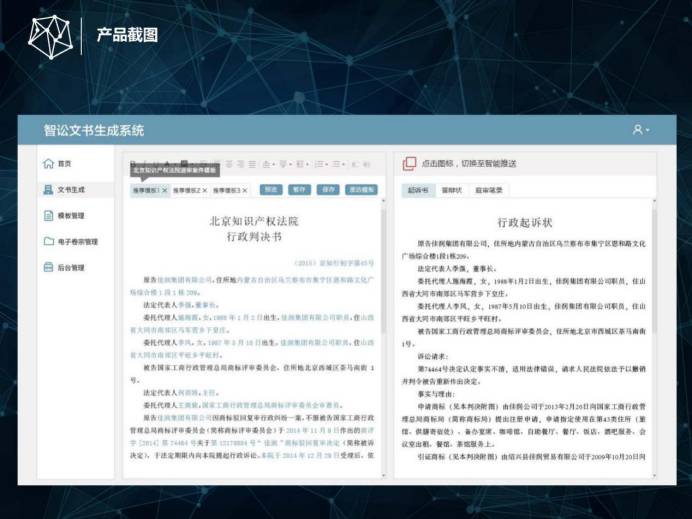
我们把知识图谱用在了很多产品上。举一个例子——文书生成系统。我们先解析前置文书,前置文书指的是起诉书、答辩状,开庭笔录等,我们解析了起诉书、答辩状和开庭笔录之后就会生成一个判决模板,从前置文书中解析出来当事人、法官、适用程序,诉讼请求等数据填充到相应的位置,同时给法院推送适当的焦点和裁判规则,并且我们还对裁判规则适用等进行数据的统计。
事理图谱在司法领域上的尝试
事理图谱是一个比较新的概念,哈工大提出事理图谱的时候就非常明确地认为:事件是人类社会的核心概念之一,人们的社会活动往往是事件驱动的。事件之间在时间上相继发生的演化规律和模式是一种十分有价值的知识,而探索事件和事件之间的演化和演化的概率是事理图谱非常重要的研究方向和研究点。

这是一张出行的事理图谱,结点表示抽象、淡化的事件,有效的边表示事件之间的顺承、因果关系,边上标注有事件间转移概率的信息。事理图谱旨在揭示事件间的逻辑演化规律与模式,由此可作为对人类行为活动的直接刻划。
为什么我们在司法领域去研究事理图谱?是因为我们认为事件不但是事理图谱的研究起点,而且对司法领域有非常大的意义,所有判决的作出都是基于原被告之间在同一时序下的行为及行为形成的客观结果。

这是我们研发事理图谱的主要技术路径,技术核心点就是事实类别识别和识别要素提取。
第一步,人工标注事件,做每句话的标注;
第二步,把人工标注的事件做一个聚合;
第三步,人工标注事件主体和客体。
司法图谱的实践启发
我们认为司法图谱可实现智慧法院的技术底层,事理图谱运用于司法领域具有开创性的意义。短时间内可以做一个文书的摘要,长时间则可以把涉案事实结构化,找到知识图谱中间对应的实体概念,触发知识图谱里的一些推送知识。我们还可以有一些配对的规则,用概率来实现推荐的排名,对类案作出法律事件发生概率及演化路径的分析,还可以广泛运用于要素式的审判,法律行为分析的预测,判决结果的高概率分析等等。知识图谱和事理图谱的搭建,可以支持法官和当事人的语义问答以及探索性地获取答案等等。

我们做的其实都是在模拟人的思维方式,该干什么、怎么干。该干什么,就是事理图谱告诉我们下一步该干什么;怎么干,就是知识图谱的事,通过知识告诉你方法,或者回答你需要的问题。我今天的分享就到这里,谢谢大家。

国双科技 曾祥辉
随后,曾祥辉先生从技术的角度告诉我们知识图谱是如何搭建的。
知识图谱概述
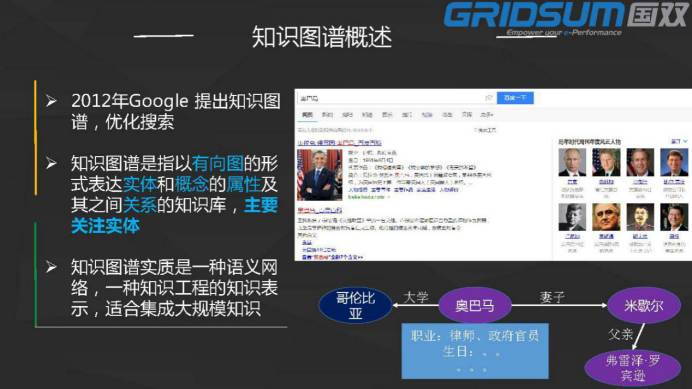
曾祥辉:知识图谱的来源,属于知识工程的一部分。谷歌提出之后,国内的公司也在跟进。
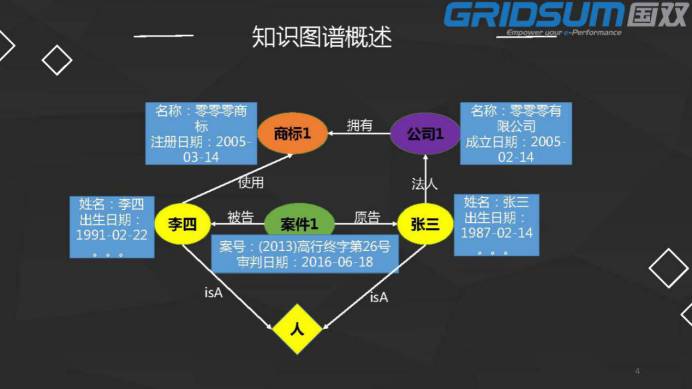
这是在司法领域的案例,我们平常在文书中看到的是一个文本的表述,然后结构化图谱,这是在我们案件中要做的事情。
1、知识表达方式各优缺点

文本是自然语言的表达方式,但是它对机器来说是非常难以理解,现在的NLP还不足以达到理解的程度。
数据库是我们用的最多的数据储存的方式,它的好处就是机器获取信息的效率比较高,技术链比较成熟;它的缺点在于对复杂信息或者复杂关系的表达比较难,因为它的模式是既定的,要演化这种模式所花费的成本会比较高。同时它对复杂关系的多度查询,也就是跨表查询,三个表就达到几十秒的时间,这个对于我们实施系统来说无法接受。
我们现在开始走向非关系型的数据库,图就是其中一种。图的好处就是在于它非常适合复杂关系和信息的表达和查询。它的模式是一种路模式,对于信息的储存非常易氧化,你要增加新的信息或者新的结点进去,可以随时加。那么它对多个以上的查询就无法输出这个结果,但是在图上始终能够保持在秒级的速度,这是我们对实施系统一个非常重要的条件;它的缺点就是对于我们常用的一些数据库,它的技术还没有成熟。
2、应用方向
信息搜索和可视化分析
为自然语言理解提供背景知识库
问答系统、医疗诊断、金融反欺诈、电商搜索推荐
图谱构建及应用技术
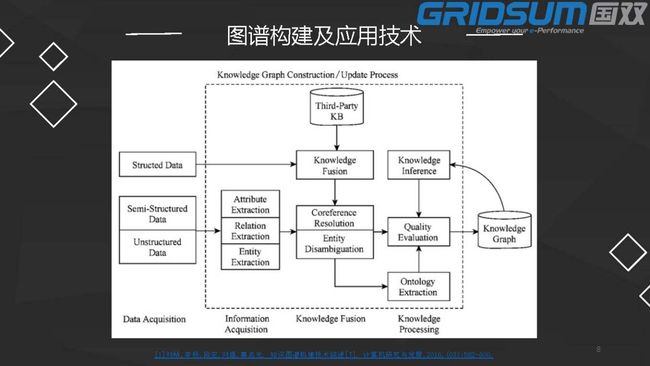
1、整体的构建流程:
1.1 明确需求
通用或垂直领域
业务需求关注的实体类型、关系类型
分类体系
1.2 确定数据来源
通用图谱:百科网站、互联网文本等
领域图谱:垂直网站(法律咨询网站、文书网)、期刊、书籍等。
1.3 知识抽取
实体抽取(NER)及关系(属性)抽取
基于规则和词典的方法:在词法、句法分析基础上,见效快;规则难以穷尽、瓶颈
基于统计的方法:带标语料难以获得,尤其是垂直领域
二者结合的方法:半监督学习,bootstrapping,种子学习+pattern,效果有待优化
神经网络:LSTM+CRF
事件抽取:静态转向动态,将事件作为实体的一种,拓宽实体关系,丰富图谱。事件识别与分类:触发词、机器学习分类。事件要素的抽取,包括实体和属性:语法、语义分析。
概念抽取:将概念识别引入,主要丰富图谱中IsA的关系,建立层级关系。
1.4 知识融合
实体对齐:不同数据同一实体、关系或属性的对齐,基于规则或者统计
关系(属性)对齐:如出生日期与出生时间
知识验证:来源可靠性,概率评估
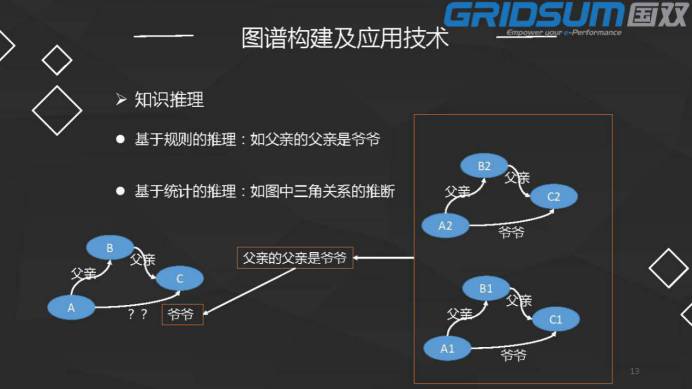
1.5 知识推理
基于规则的推理:如父亲的父亲是爷爷
基于统计的推理:如图中三角关系的推断
基于规则的推理:假设我们承认A的父亲是B,B的父亲是C,但A和C的关系没有储存,或者在已有的信息是没有获取到,怎么办呢?
第一种方法,可以通过人给图谱做一些规则,我们说A的父亲是B,B的父亲C,我们就可以得到这个关系,A的爷爷是C。
第二种方法,基于统计的方法,比如我们现有的图谱中已经存在很多三角关系,通过很多三角关系的实例,让机器学习父亲的父亲是爷爷,得到A和C的关系。
1.6 知识分布式表示

我们可以把知识图谱的关系表示成一个向量,向量之间的相似度可以通过一些方法来计算,可以计算相似度,做一些融合,也可做一些推荐。
2、应用方向:

这是知识图谱应用到的一些方向,大概都差不多,可能会涉及到实体链接、关系识别和路径推理。问答系统,它最重要的一点是意图识别和语义分析。现在百度为什么只能识别某一类型的问题而有些问题就识别不了,因为他们做了一些模板的问题。
总结
第一点,面向业务需求,决定用什么技术。我们做工程或者做项目跟做研究有点不同,知识图谱的确非常有用,但是你的业务或许根本用不到这个技术。
第二点,工程性质及快速迭代,粒度有大到小。我们在构建知识图谱的过程中发现这个度非常难以控制,因为要做到实体层和概念层是非常难的。
第三点,有效果的技术就是最好的技术。不用去拘泥于非得用什么高深的技术和最前沿的技术,这和做学术研究不一样。
第四点,重视人工协作的力量。基于维基百科和百度百科的知识抽取,它们的基础是什么?就是大量的网民朋友们无私的奉献,都是人工编辑出来的。
这是一些参考材料,有兴趣的可以去看:
从语义网到知识图谱——语义技术工程化的回顾与反思
http://www.wtoutiao.com/p/181x8bc.html
降低知识图谱的构造成本
http://weibo.com/p/1001603966996583691220
知识图谱研究进展综述
http://www.360doc.com/content/17/0325/18/99071_64 0071618.shtml
知识图谱与深度学习
http://blog.csdn.net/starzhou/article/details/71169636
后台回复关键词“0920”,下载完整版讲座PPT。
内容整理:陈龙
校对:朱江华峰
编辑:王璇
为保证发文质量、树立口碑,数据派现设立“错别字基金”,鼓励读者积极纠错。
若您在阅读文章过程中发现任何错误,请在文末留言,或到后台反馈,经小编确认后,数据派将向检举读者发8.8元红包。
同一位读者指出同一篇文章多处错误,奖金不变。不同读者指出同一处错误,奖励第一位读者。
感谢一直以来您的关注和支持,希望您能够监督数据派产出更加高质的内容。
转载须知
如需转载文章,请做到 1、正文前标示:转自数据派THU(ID:DatapiTHU);2、文章结尾处附上数据派二维码。
申请转载,请发送邮件至[email protected]
