yolo升级版
YOLO升级版:YOLOv2和YOLO9000解析
评论:YOLO是基于深度学习方法的端到端实时目标检测系统(YOLO:实时快速目标检测)。YOLO的升级版有两种:YOLOv2和YOLO9000。作者采用了一系列的方法优化了YOLO的模型结构,产生了YOLOv2,在快速的同时准确率达到state of the art。然后作者采用wordtree的方法,综合ImageNet数据集和COCO数据集训练YOLO9000,使之可以实时识别超过9000种物品。本文有以下几点非常值得参考:
一,对模型的一系列分析和改进非常值得参考;
二,采用多尺度训练方法,使模型可以适应不同的输入尺寸,非常值得参考。
三,综合不同数据集的方法非常值得参考;
四,联合训练方法也是非常值得参考;
五,YOLO端到端实时检测和识别的思路非常值得参考。
总体说,本文很值得参考。
简介
YOLO9000是可以检测超过9000种类别的实时检测系统。首先,作者在YOLO基础上进行了一系列的改进,产生了YOLOv2。YOLOv2在PASCAL VOC和COCO数据集上获得了目前最好的结果(state of the art)。然后,采用多尺度训练方法,YOLOv2可以根据速度和精确度需求调整输入尺寸。67FPS时,YOLOv2在VOC2007数据集上可以达到76.8mAP;40FPS,可以达到78.6mAP,比目前最好的Faster R-CNN和SSD精确度更高,检测速度更快。最后提出了目标检测和分类的共训练方法。采用该方法,作者分别在COCO目标检测数据集和ImageNet分类数据集上训练了YOLO9000。联合训练使YOLO9000可以预测没有labelled的目标检测数据。YOLO9000在ImageNet验证集(200类)上获得了19.7mAP。其中,156类没有出现在COCO训练集中,YOLO9000获得了16.0mAP。YOLO9000可以实时识别超过9000类别。
1 前言
目标检测系统要求快速,准确以及能识别大范围种类数量。但是,目前基于深度神经网络方法的目前检测系统能识别的物品种类较少。其原因在于:相对于物品分类数据集,目标检测数据集中的物品种类较少。标记目标识别数据集所耗费的精力远大于标记物品分类数据集。物品分类数据集包含成千上万种超过数百万张图片,而目标识别数据集就很小了。
本文中,作者提出了一种结合不同类型数据集的方法。基于该方法,作者提出了一种新的联合训练方法,结合目前物品分类数据集的优点,将其应用于训练目标检测模型。模型可以从目标检测数据集中学会准确定位目标,同时从物品分类数据集中学会识别更多的种类,增强模型的鲁棒性。
采用该方法,作者训练了可以识别超过9000种物品的实时目标检测与识别系统-YOLO9000。首先,作者在YOLO的基础上进行了改进,产生了YOLOv2(获得了state of the art)。然后,作者采用数据集结合方法和联合训练方法,采用ImageNet和COCO数据集训练该模型,使该模型可以识别和检测 超过9000种类别。
2 改进-YOLOv2
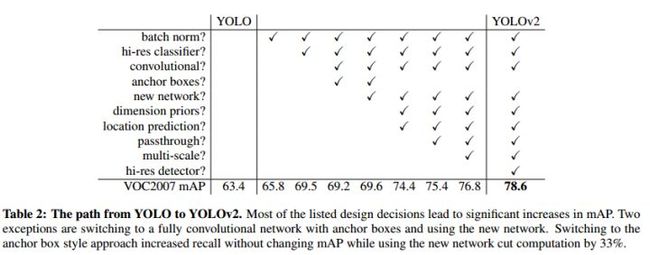
YOLO相对于目前最好的目标检测系统存在的问题是精确度不够。错误项目分析显示,相对于Fast R-CNN,YOLO在目标定位方面错误率较高。因此,对于YOLO的改进集中于在保持分类准确率的基础上增强定位精确度。改进的项目如表2-1所示。
表2-1 YOLOv2的改进
2.1 Batch Normalization
Batch Normalization可以提高模型收敛速度,减少过拟合。作者在所有卷积层应用了Batch Normalization,使结果提升了2%。同时,Batch Normalization的应用,去除了dropout,而不会过拟合。
2.2 High Resolution Classifier
目前最好的图像分类器采用基于ImageNet数据集预训练模型。大部分类器输入图像尺寸小于256×256。原始YOLO接受图像尺寸为224×224。在YOLOv2中,作者首先采用448×448分辨率的ImageNet数据finetune使网络适应高分辨率输入;然后将该网络用于目标检测任务finetune。高分辨率输入使结果提升了4%mAP。
2.3 Convolutional With Anchor Boxes
YOLO采用全连接层来直接预测bounding boxes,而Fast R-CNN采用人工选择的bounding boxes。Fast R-CNN中的 region proposal network仅采用卷积层来预测固定的boxes(anchor boxes)的偏移和置信度。
作者去除了YOLO的全连接层,采用固定框(anchor boxes)来预测bounding boxes。首先,去除了一个pooling层来提高卷积层输出分辨率。然后,修改网络输入尺寸:由448×448改为416,使特征图只有一个中心。物品(特别是大的物品)更有可能出现在图像中心。YOLO的卷积层下采样率为32,因此输入尺寸变为416,输出尺寸为13×13。
采用anchor boxes,提升了精确度。YOLO每张图片预测98个boxes,但是采用anchor boxes,每张图片可以预测超过1000个boxes。YOLO模型精确度为69.5mAP,recall为81%;采用anchor boxes方法后,结果为69.2mAP,recall为88%。
2.4 Dimension Clusters
在YOLO模型上采用anchor boxes有两个关键。第一,box维度为人工选择。模型可以学会适应boxes,但是如果人工选择更好的boxes,可以让模型更加容易学习。我们采用K-means聚类方法来自动选择最佳的初始boxes。我们希望的是人工选择的boxes提高IOU分数,因此,我们公式定义为:。k-means结果如图2-1所示,作者选择了k=5.
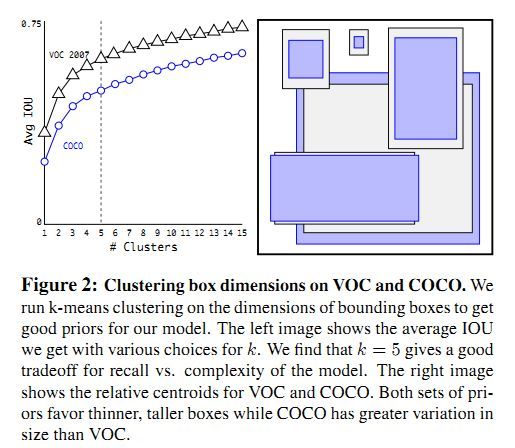 图2-1 k-means结果
图2-1 k-means结果
2.5 Direct location prediction
在YOLO模型上采用anchor boxes的第二个关键是模型不稳定性,特别是在前面几轮训练。大部分不稳定因素来源于预测boxes位置(x,y)。作者将预测偏移量改变为YOLO的预测grid cell的位置匹配性(location coordinate),将预测值限定在0-1范围内,增强稳定性。网络对feature map中的每个cell预测5个bounding boxes。对每一个bounding boxes,模型预测5个匹配性值()。采用聚类方法选择boxes维度和直接预测bounding boxes中心位置提高YOLO将近5%准确率。
2.6 Fine-Grained Features
改进后的YOLO对13×13的feature map进行目标检测。更精确的特征(finer grained features)可以提高对于小目标的检测。作者向网络加入passtrough层以增加特征。passthrough类似于ResNet,将高分辨率特征和低分辨率特征结合,使26×26×512的特征图转化为13×13×2048的特征图。该改进增加了1%的性能。
2.7 Multi-Scale Training(多尺度训练,很有参考价值)
最初的YOLO输入尺寸为448×448,加入anchor boxes后,输入尺寸为416×416。模型只包含卷积层和pooling 层,因此可以随时改变输入尺寸。
作者在训练时,每隔几轮便改变模型输入尺寸,以使模型对不同尺寸图像具有鲁棒性。每个10batches,模型随机选择一种新的输入图像尺寸(320,352,...608,32的倍数,因为模型下采样因子为32),改变模型输入尺寸,继续训练。
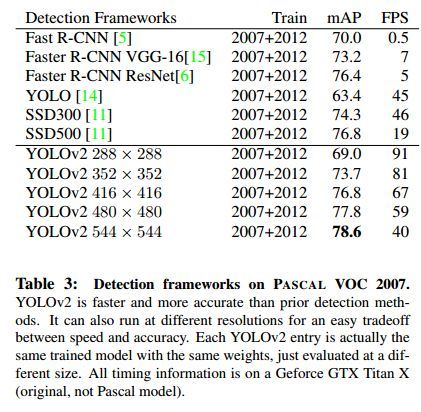
该训练规则强迫模型取适应不同的输入分辨率。模型对于小尺寸的输入处理速度更快,因此YOLOv2可以按照需求调节速度和准确率。在低分辨率情况下(288×288),YOLOv2可以在保持和Fast R-CNN持平的准确率的情况下,处理速度可以达到90FPS。在高分辨率情况下,YOLOv2在VOC2007数据集上准确率可以达到state of the art(78.6mAP),如表2-2所示。
表2-2 多尺度训练结果
2.8 其它实验
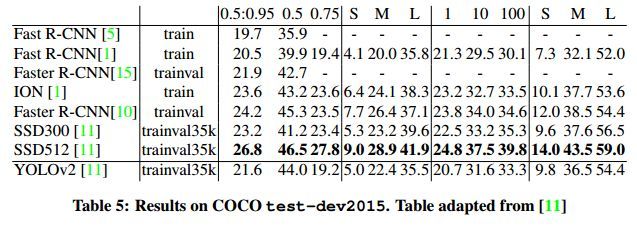
作者在VOC2012数据集和COCO数据集上进行了实验,结果如表2-3和表2-4所示。
表2-3 VOC2012测试结果
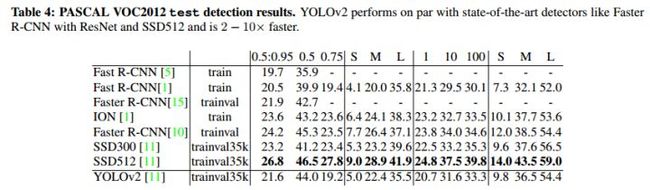
表2-4 COCO测试结果
3 检测更加快速(faster)
大部分检测框架是基于VGG-16作为特征提取网络,但是VGG-16比较复杂,耗费计算量大。YOLO框架使用了类似googlenet的网络结构,计算量比VGG-16小,准确率比VGG16略低。
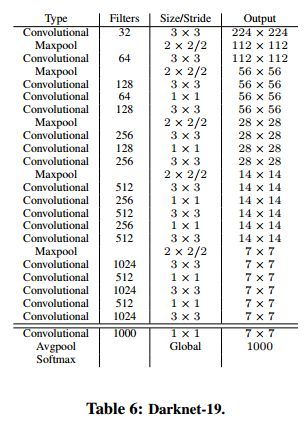
3.1 Darknet-19
作者设计了一个新的分类网络(Darknet-19)来作为YOLOv2的基础模型。Darknet-19模型结构如表3-1所示。
表3-1 Darknet-19网络参数
3.2 分类任务训练
作者采用ImageNet1000类数据集来训练分类模型。训练过程中,采用了 random crops, rotations, and hue, saturation, and exposure shifts等data augmentation方法。预训练后,作者采用高分辨率图像(448×448)对模型进行finetune。
3.3 检测任务训练
作者将分类模型的最后一层卷积层去除,替换为三层卷积层(3×3,1024 filters),最后一层为1×1卷积层,filters数目为需要检测的数目。对于VOC数据集,我们需要预测5个boxes,每个boxes包含5个适应度值,每个boxes预测20类别。因此,输出为125(5*20+5*5) filters。最后还加入了passthough 层。
4 stronger
作者提出了将分类数据和检测数据综合的联合训练机制。该机制使用目标检测标签的数据训练模型学习定位目标和检测部分类别的目标;再使用分类标签的数据取扩展模型对多类别的识别能力。在训练的过程中,混合目标检测和分类的数据集。当网络接受目标检测的训练数据,反馈网络采用YOLOv2 loss函数;当网络接受分类训练数据,反馈网络只更新部分网络参数。
这类训练方法有一定的难度。目标识别数据集仅包含常见目标和标签(比如狗,船);分类数据集包含更广和更深的标签。比如狗,ImageNet上包含超过100种的狗的类别。如果要联合训练,需要将这些标签进行合并。
大部分分类方法采用softmax输出所有类别的概率。采用softmax的前提假设是类别之间不相互包含(比如,犬和牧羊犬就是相互包含)。因此,我们需要一个多标签的模型来综合数据集,使类别之间不相互包含。
4.1 Hierarchical classification(多层分类)
ImageNet的数据标签来源于WordNet,具有一定层次结构。作者根据WordNet建立了ImageNet标签的树(WordTree)。作者采用标签树训练了Darknet-19,结果如图4-1所示。
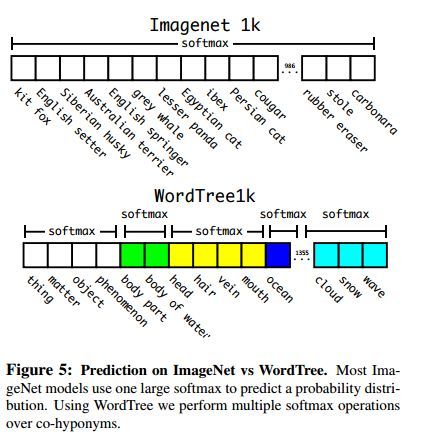 图4-1 采用WordTree训练结果
图4-1 采用WordTree训练结果
4.2 采用Wordtree综合数据集
作者采用wordtree综合ImageNet和COCO数据集,如图4-2所示。
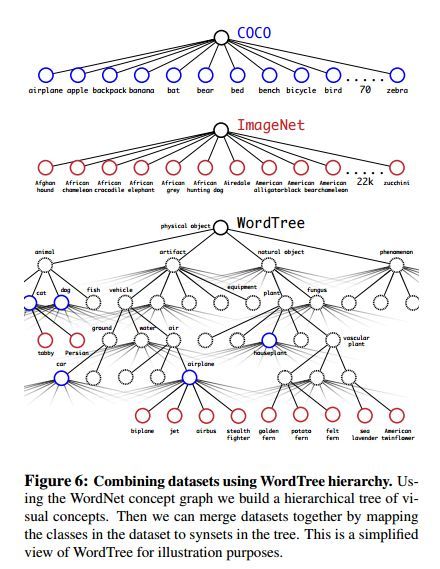
图4-2 Wordtree层次
4.3 联合分类和检测
作者采用综合数据集训练了YOLO9000,结果如图4-3所示.
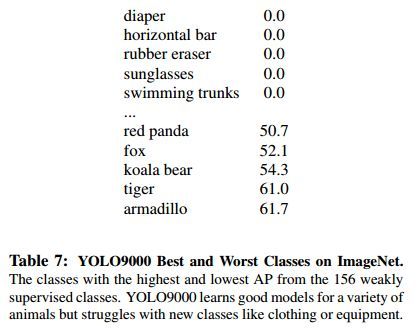 图4-3 YOLO9000测试结果
图4-3 YOLO9000测试结果
5 结论
作者通过对YOLO网络结构和训练方法的改进,提出了YOLOv2和YOLO9000两种实时目标检测系统。YOLOv2在YOLO的基础上进行了一系列的改进,在快速的同时达到state of the art。同时,YOLOv2可以适应不同的输入尺寸,根据需要调整检测准确率和检测速度(值得参考)。作者综合了ImageNet数据集和COCO数据集,采用联合训练的方式训练,使该系统可以识别超过9000种物品。除此之外,作者提出的WordTree