基于IC设计的实用ISP介绍
基于IC设计的实用ISP介绍
前言:
这篇文章是我从事ISP研究数年来的一些经验总结,没有用到深奥的理论知识,有的只是根据实际状况来处理的一些常规方法,以及曾经犯过的错误总结。我想把ISP function的原理用简单浅显的语言描述出来,希望对初学者有所帮助。这里的ISP主要是指从CMOS sensor输出的bayer pattern,到转换成通用的YUV或者YCbCr格式的过程,通常用于USB摄像头/监控摄像头/手机/平板等芯片设计中。
在IC设计中,受限于处理速度,像素级的ISP算法都相对简单,只会用到加/减/乘/比较等基本运算,通常不会用到除法、指数、对数、平方根、三角函数等复杂运算。以1080p30fps的视频为例,像素处理速度为1080*1920*30=62M pixel/s,每个pixel都需要非常多的基本运算,用pipeline的方式实现连续高速计算。像除法,指数运算或者三角函数,则较多的时钟周期才能完成一次计算,因此不适用于ISP的像素级处理,在算法设计中要尽量避免这些复杂运算。ISP中也有针对整幅图像处理的运算(非像素级),例如白平衡AWB,自动曝光AE和自动对焦AF,这些算法比较灵活,处理速度要求不高,通常由CPU来处理的,任何复杂运算都可以用,只要CPU性能足够。
研究ISP算法是一件充满乐趣的事情,原因在于ISP算法没有标准答案,任何ISP算法都没有一个标准协议,每个人都可以自由发挥自己的想象力,目的只有一个,让人眼看得舒服,大家看着好,才是真的好。每个人的想象力各不相同,算法复杂度也是无穷尽,评价ISP算法的优劣,主要就是一个性价比:在一定复杂度要求的条件下,达到最好的图像质量。在学习ISP相关的paper的时候,要关注的重点是算法的原理,或者说出发点,而不是计算公式,因为公式中通常都是复杂运算,难以实际用起来,在理解了原理之后,可以找近似的替代算法来达到相近的效果。
从视觉感受来分,我把ISP大致分成亮度,色彩和细节三个部分。亮度是指对图像整体的亮度调整,涉及到的算法有自动曝光Auto Exposure,黑电平校正Black Level Correction,镜头阴影校正Lens Shading Correction,Gamma,High Dynamic Ranger等。涉及到色彩的有白平衡Auto WhiteBalance,色彩校正Color Correction Matrix,饱和度Saturation,色相Hue等。细节的算法主要的去噪Denoise,插值interpolation,缩放zoom,边缘增强edge enhance等。还有一些其他相对特殊的算法,例如自动对焦Auto Focus,防闪烁anti-flick等。一个简化的ISP算法框架如下图。
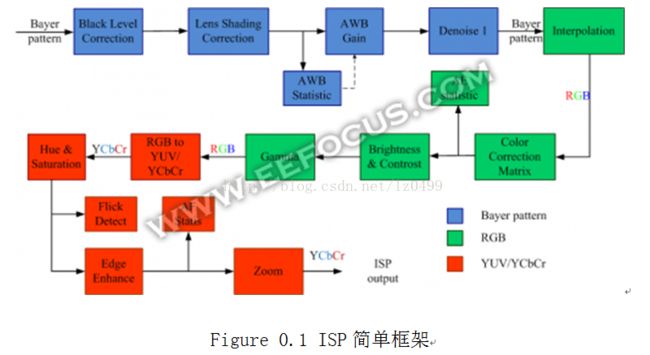
ISP各个基本算法是相对独立的,但是在整体效果呈现上,又是相互关联的。举例来说,Lens Shading Correction这个算法把要图像四周的拉亮,这就导致图像四周的Noise比较大, 而Noise较大的话,edge enhance就要对四周的像素做特殊处理,使得Noise不会被放大,这会导致图像中心相对清晰,四周相对模糊。经常调校ISP的人,对此可能深有体会。诸多ISP算法模块,内在是有一些确定的逻辑关系的,上图中的框架结构,有些顺序是可以改变,有些则不可以改变,有些改变会导致算法复杂度提升。ISP算法中有不少特性是相互对立矛盾的,例如清晰度和噪声,AWB中的稳定度和精确度,AE中的收敛稳定性和收敛速度等,这些对立的特性,就像天平的两端,需要根据客户需求或者实际应用场景去做平衡。
对ISP的研究学习过程,既有符合构想预期的情况,也有充满意外的时候,同时感叹一下人眼或者说人脑的高复杂度和高灵敏度。ISP的各种数学运算,最终是要让CMOS sensor感应到的图像,转化模拟成人眼/人脑感受到的图像,通过不断的学习和尝试,让各种ISP模块中的数学计算,能够得出期望的图像效果,或者从图像效果反推出算法中的原因所在。一个有经验的ISP算法研究工程师,就是建立起数学计算和图像效果之间的映射关系。
接下来,我将从图像亮度,色彩和细节三个方面来一一介绍ISP中各个function。
图像亮度
ISP算法的目的是要让CMOS成像接近人眼的感受效果,所以首先要比较人眼成像和CMOS成像的差异。从图像亮度这方面来看,最重要的就是曝光,其次有针对显示器特性的Gamma映射,针对CMOS sensor 特性的Black Level Correction,针对镜头透光性的Lens shading Correction,以及anti-flick等,下面逐一介绍。
1.1曝光
影响CMOS Sensor 成像亮度的因素有光圈大小,曝光时间以及Sensor像素本身的感光特性。光圈越大,进光量越大,图像亮度和光圈大小成正比。曝光时间越长,接收到的光子数量越多,图像亮度和曝光时间也成正比。Sensor本身像素敏感度则和pixel size大小,以及CMOS process(FSI/BSI)相关。在Sensor内部,完成光电转化之后的电位,还需要通过一个模拟/数字增益电路,增益越大,图像越亮,同时Noise也会被放大,在sensor的参数设定中有这个analog/digital gain,即通常说的ISO。
对于人眼来说,瞳孔是人眼的口径;虹膜是光圈,像是孔径内的档板。在角膜的折射造成有效孔径 (入射瞳)。入射瞳的直径通常是4mm,但是它的范围可以从在明亮地方的2mm变化至黑暗地方的8mm。
Sensor和人眼的对比如下表格:
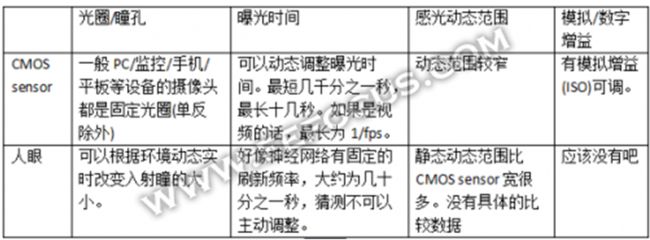
从以上表格内容可以看出,人眼是靠调整光圈来适应环境亮度,而一般的摄像头则是调整曝光时间和增益来适应环境亮度。相比而言,人眼在同一场景下所能感受的亮度动态范围要比CMOS sensor大很多倍,在很多户外场景中,摄像头拍出的照片局部过曝,或者局部太黑,因此摄像头很需要HDR技术:同一场景下拍摄不同曝光时间的多张图片(扩大动态范围),来合成一张图像。另一方面CMOS sensor的曝光时间理论上可以无限长,因此摄像头可以拍下和人眼平常所见不同的美景,例如夜晚的星空和城市夜景(通常曝光时间要好几十秒)。不过对于视频拍摄来说,较长的曝光时间意味着运动物体会变模糊,所以一般都要求帧速率在15fps以上,即曝光时间最大只有1/15s。在这个约束条件下,一般的Sensor感光效果相比人眼差很多,在暗光下为了使图像可见,必须要用很大的模拟或者数字增益,很多sensor会到64倍增益,这带来了很大的Noise,人眼是没有Noise这一说法的哦。
在ISP中,自动曝光AE有相对成熟的算法。首先以人的视觉主观感觉确定一个目标亮度,这个亮度要让用户看着合适,具体数值看用户喜好和真实环境可以调整。然后统计当前图像的实际亮度。统计的方法常见的有两种。
一种是基于亮度均值的方法,例如把整幅图像分割成若干个矩形框,分别统计矩形框中像素平均亮度,不同位置的矩形框有不同的权重系数,然后加权平均得到整幅图像的亮度均值。下图为两种常见的权重设置方式:中间优先(适用于人像拍摄)和下方优先(适用于行车记录仪)。
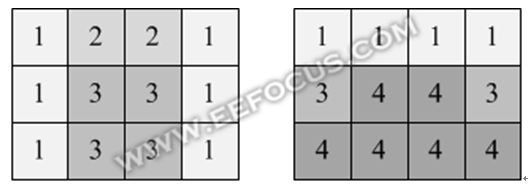
人像拍摄的时候,有时并不知道人脸的位置在哪里,如果此时背景比较明亮,那么人脸可能会拍得比较暗。假如上层应用中有人脸检测功能,那么就可以告诉ISP人脸的位置在哪里,ISP对人脸所在的位置进行亮度统计,把得到人脸的亮度和整幅图像的均值做加权平均,重新得到当前亮度。
对于平板和手机而言,还有touch AE,拍摄视频/照片的时候,在屏幕上点击感兴趣的位置,那么AE 和AF 都会跟着有变化。在ISP中,就是对着touch的区域做亮度统计,把touch区域的亮度和整幅图像的均值再做加权平均,重新得到当前亮度。
还有一种方法是基于直方图统计的,力争让图像的灰阶分布比较好,特别是在高反差的情况下,像素主要分布在直方图的两端,亮度均值的算法不太适用。直方图数据可以明显的反映出这种状况,从而选择暗光优先模式或者亮光优先模式。
以上介绍了当前图像的几种亮度统计方法,得出当前亮度,接着要计算当前亮度和目标亮度的比例关系,根据这个比例关系来调整Sensor的曝光时间和增益。我们已经知道图像亮度是和曝光时间及增益成线性比例关系,有如下公式:
目标亮度/当前亮度 = (期望曝光时间×期望增益)/(当前曝光时间×当前增益)
AE算法要在期望曝光时间和期望增益之间做一定的平衡,增益较大的话会有Noise,曝光时间长的话会导致帧速率fps下降。此外,AE控制算法还需要注意两点:一是给sensor下的曝光参数并不是实时生效的,往往会有几个Frame的延迟,要小心避免AE来回震荡;二是要切换AE参数要平稳一些,渐进的方式达到目标亮度,一步到位的视觉感受并不好,AE收敛速度和AE稳定性需要平衡。
2.2Black Level Correction
黑电位校正是由于CMOS sensor 本身由于暗电流的存在,导致在没有光线照射的时候,像素单位也有一定的输出电压。需要把这个电位减去,让输出的数据呈现出随亮度线性变化的规律。一般的Sensor都有BLC参数,sensor厂商会给出已经调校好的参数,在ISP中也还有进一步的BLC存在。但ISP的BLC 一般只是微调数据,有些sensor在不同色温或者环境亮度条件下需要调整。如下图:

右侧的图像在一定环境下,呈现偏红色,因此需要对R分量减去一个较小的幅度。同时为了对整幅图像数据不造成大的影响,R分量还要保持0~255的取值范围,所以BLC 计算公式如下:
f(x, Δ)=(x-Δ)*255/(255-Δ)
其中Δ为BLC校正的数值, x可以是R/G/B中的任意一个分量,取值范围在0~255. BLC的映射关系图如下,水平方向表示物体亮度,垂直方向表示Sensor像素的输出值,蓝色为BLC之前的数据,红色为BLC之后的数据。
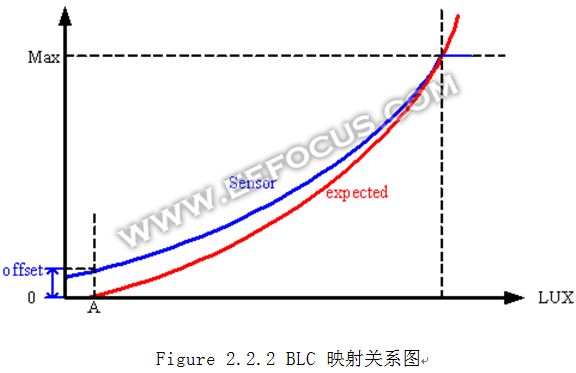
BLC参数Δ不宜设置过大,Δ越大,则感光动态范围越小。一般要求在图像效果可接受的范围内,Δ越小越好。判断Δ设置是否到位的一个简单方法是把sensor完全遮黑,看看输出数据是否逼近0值。
2.3 Lens ShadingCorrection
由于Lens的不同区域透光性能不一致,导致图像中心区域较亮,图像四周较暗。如下图:

一般来说,物体到lens中心的距离越远,图像越暗,呈圆形中性对称的方式递减。在算法中很容易想到用曲线映射的方式来补偿亮度。假设像素到lens 中心的距离为d, 那么根据d映射一个lens shading gain,映射曲线类似抛物线的形状,每个像素根据自己的d,乘以相应的gain。
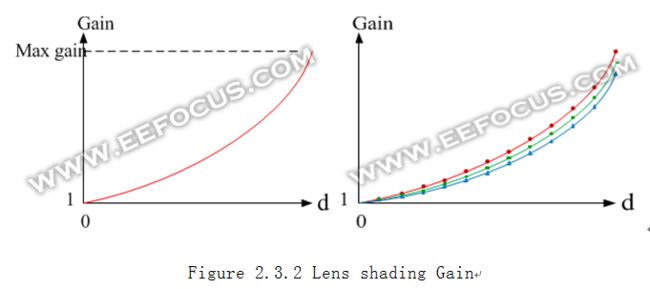
这个Gain在lens中心点(d=0)为1,d越大gain也越大,有些lens在最远的角落可能达到3倍。正是有些Lens shadinggain很大,导致了整幅图像中四周的Noise明显比中心大很多。这条曲线的形状受lens和sensor特性不同而差异很大,对不同波长的光线衰减程度也不一样,R/G/B三个分量分别需要各自的映射曲线,我们一般采用分段线性插值的方式来模拟这三条曲线,如figure2.3.2(右)。
要进行LSC运算,需要知道三个信息:一是lens 中心坐标(Cx,Cy),二是三条曲线形状,三是像素到(Cx,Cy)的距离d。首先我们回顾一下ISP 构架图figure0.1,可以看到LSC的位置很靠前,仅在BLC之后,在bayer pattern domain。我们先要拍摄一张bayer pattern的图片,要保证整幅画面的亮度是一致的:一种方法是拍摄内容为纯白色或者灰色,这需要绝对的光照均匀;另一种方法是用亚克力板遮住sensor拍白色光源。然后对这张图片进行用一定的方法计算,找到最亮的位置就是lens中心坐标(Cx,Cy), 然后找出到lens中心距离相同距离d(i)的点的集合,计算这个集合内像素平均亮度和中心像素亮度的比例关系r(i),取r(i)的倒数就是LSC gain曲线上d=d(i)的gain值。在ISP中(Cx,Cy)和LSC gain curve是预先由tool计算好,作为参数写入到register中的。对于从左往右自上而下逐行传输的图像,任意一个pixel到lens 中心的距离d是需要计算的,如果用距离计算公式则用到平方根,计算速度较慢。不过任意两个相邻像素到lens中心的距离是有相互关联的,知道了左边像素的距离,可以通过简单的几步加法运算递推出右边像素的距离,有兴趣的同学可以尝试推导一下。
![]()
在实际使用中,由于周边Noise实在较大,我们不得不在四周亮度和Noise之间取一个平衡。在低光照条件下,通常会让四周的亮度达到中心亮度的70%~90%就可以了。环境色温的差异,也会导致计算出LSC gain curve有所差异,在调校IQ的过程中,会计算多种色温的LSC gain curve,然后在实际使用过程中动态的调整curve形状。
除了上述圆形的LSC以外,还有一种网格状(grid)的LSC方式。这种方式早期是用于纠正CMOS sensor由于制程漂移导致的局部色偏问题。Sesnor不同区域的像素滤光片性能不一致,导致图像局部偏色,这种偏色没有规律性,于是只好用grid的方式来补偿。每个网格内需要有一组rgb gain,Grid数量越多,所消耗的资源也越大。对任意一个像素,找出其四周的4组rgb gain,用双线性插值可以计算出自身的gain。当grid足够密集的话,就可以取代圆形的补偿方法,代价是成本较高。

2.4Gamma
Gamma这一特性源自于传统的CRT显示器,电子射线打出的屏幕亮度和电压是一种gamma曲线的关系,基本映射波形曲线如下:

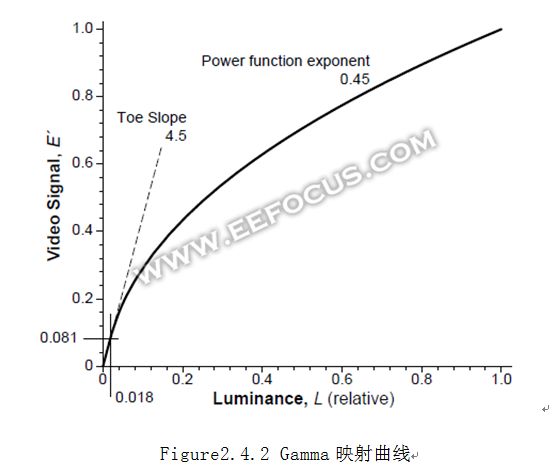

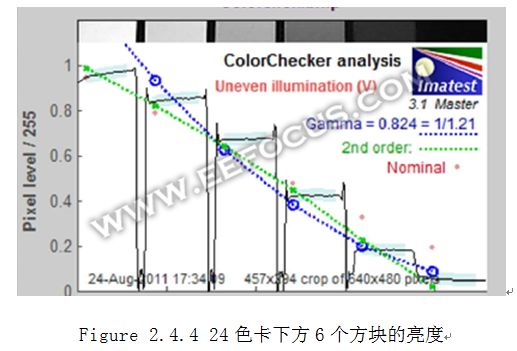
在实际的ISP设计中,不会真的去用上述的公式进行指数运算,一是计算速度不够,二是灵活度较低。一般都是用曲线映射的方式,可以用分段线性插值,也可以用SRAM逐一映射。这条曲线的形状可以任意配置,在调校图像的时候,一种方法是在灯箱拍摄24色卡,让色卡最下方的6个色块的亮度数据Y尽量呈现出线性等比例关系。这条曲线也可以随着环境变化而动态调整,特别是在低照度环境下,为了减小Noise而降低幅度。
2.5Brightness
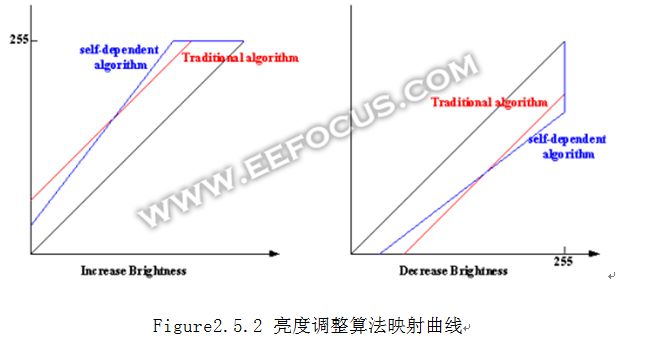
亮度调整是一般摄像头都有的基本属性。通常都是在YCbCr空间对图像每个像素的Y都加上一个ΔY,ΔY可正可负。这样在增加亮度的时候会有明显的缺陷,图像的饱和度会降低,图像变白,视觉效果变差。根据RGB和YCbCR的转换公式可以分析出相同的结论:在Y上增加ΔY,等价于在R/G/B三个分量加上相同的ΔY。 我们常说的色彩鲜艳程度,非常近似于R/G/B之间的相互比例关系。当ΔY为正时,相当于R/G/B之间比例关系趋向于1,即差异变小,所以色彩变淡。那么要保持R/G/B比例关系,对R/G/B用乘法最好了,一样可以提高亮度。不过乘法也自己的问题,一是容易让较大的数据溢出,二是对暗处的亮度提升不明显。因此最好是加法和乘法做个融合,把亮度调整挪到RGB空间做,会有不错的效果。这里给出一个计算公式,对RGB三个分量独立计算,假设用户调整亮度为ΔY,x=R或者G或者B,ΔY 和R/G/G的取值范围都在0~255之间,a为可调参数,范围在0~1,建议为1/4.
f(x, ΔY) = x + a*ΔY + x*(1-a)*ΔY /256
我这个算法命名为基于色彩分量自身的亮度调整算法,效果图如下:

减小亮度的时候,也有类似的问题,直接对Y做减法的时候,暗处的内容就会丢失比较严重,同样可以采取在RGB空间加法和乘法结合的方式,有兴趣的可以自己实验看看。这种算法的映射曲线如下:
2.6Anti-Flick
Flick是由于我们平常所用的交流电是50Hz或者60Hz(美国)的正弦波形,荧光灯辐射能量与此相关,人眼察觉不出来(神经网络刷新频率太低,还是视觉残留效应?),但是CMOS sensor可以观察到,当拍摄被荧光灯照射的场景时就会容易有flick现象。如下图。这是一种垂直方向的正弦波,而且会随着时间滚动。
要解释flick的成因,先要了解CMOS Sensor的曝光方式。Sensor 通常有全局曝光global shutter和滚动曝光rolling shutter两种。Global shutter是指整个Frame pixel在同一时间开始曝光,同一时间结束曝光,然后把数据通过接口传输出来,等数据传输完成之后,再开始下一个Frame的曝光。Rolling shutter是指Frame中各条line上的pixel 按照顺序依次开始曝光,先曝光完成的line 先传输,不必等整个frame都曝光完成。示意图如下。
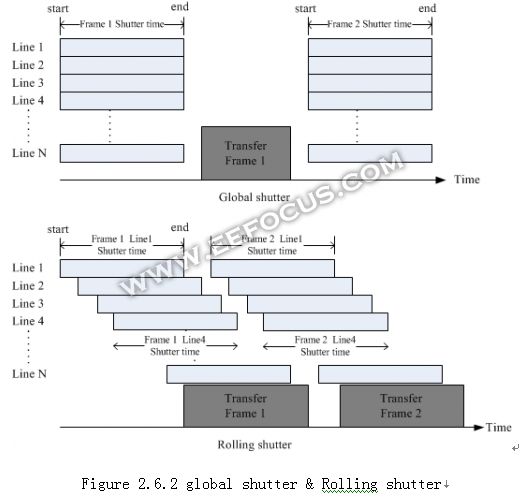
大部分sensor都支持这两种曝光模式,相比较而言,可以看到rollingshutter对时间的利用率较高,大部分时间可以被利用起来进行曝光。Rolling shutter的缺陷是当有物体高速移动的时候,拍摄到的物体会有变形,矩形变成平行四边形,这可以依照上图原理推断出来。Global shutter不会变形,主要用于拍照片,对fps没有太多要求,单张照片也不存在flick的问题。Rolling shutter用于拍视频,所以会存在flick问题。
Flick的原因在于荧光灯发出的能量在时间上是不均匀的,以我们国家50Hz为例,电压为50Hz正弦波,做平方运算转换到荧光灯的辐射能量,为100Hz的半弦波形状,如下图。假设某个frame的曝光时间为0.025s,即2.5个半弦波,由于采用rolling shutter,每条line的起始曝光时间不一致,Line A和line B可吸收的能量也不相同,Line B 要比Line A亮一些。这样在整个Frame 中就会有垂直方向的波浪纹。如果相邻Frame的间隔不是0.01s的整数倍,那么每条Line 在不同Frame接收的能量也会变化,这样看到的现象是波浪纹会随着时间在画面上滚动。
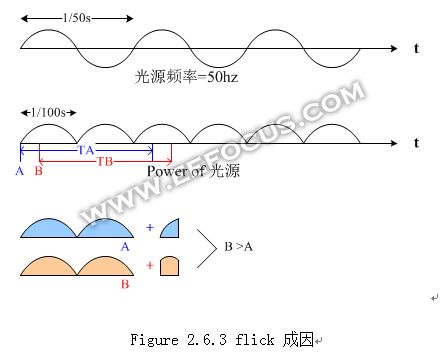
解决flick的方法很简单,只要限制曝光时间是0.01s的整数倍,那么任意像素吸收的能量都是一样的。然而在户外光照较强的时候,曝光时间为0.01s的时候就会导致过曝,户外也没有荧光灯,不需要强加这个限制,所以在ISP中需要一个检测机制,能够检测出flick的存在,当发现这种flick的时候才对曝光时间进行限制。检测flick没有统一的方法,可以自由发挥想象力,找到能准确检测flick并且不会误判的方法,正是ISP乐趣所在。
2.7HDR
HDR的本意是高动态范围图像压缩。 我们知道一般CMOS sensor拍摄到的照片动态范围较人眼小很多,所以通过不同曝光时间拍摄同一场景的多张照片,实现动态范围扩展。前文提过曝光时间和图像亮度成正比,在已知多张照片曝光时间的条件下,可以把多张照片合成一张高动态范围的图片。举例来说,原始照片中图像内容的亮度范围都是0~255,合成之后亮度范围可能变成了0~1023,这幅高动态照片确实可以呈现所有的图像细节,不过一般显示器的显示范围只有0~255,无法直接显示出来。采用等比例压缩成0~255的话,图像细节丢失比较严重,于是出现了各种压缩动态范围的算法,既能完整呈现图像,又不损失细节。借用百度的图片。

先谈一下HDR的实现方法。通常我们所说的HDR都是指照片而不是视频,也就是说拍摄好几张不同曝光的照片存在系统的DRAM中,然后由CPU来计算合成,这是由SW来实现的,通常所需时间是秒级。HDR算法种类很多,效果较好的算法也意味着较高的计算复杂度。现在视频拍摄也需要HDR,CPU就容易算不过来,我这里分析一下由数字IC设计来实现HDR的可行性。
要视频HDR,首先需要CMOS sensor支持长短曝光模式,以长/短两种曝光图像合成为例,据我所知有两种输出格式,如下图。
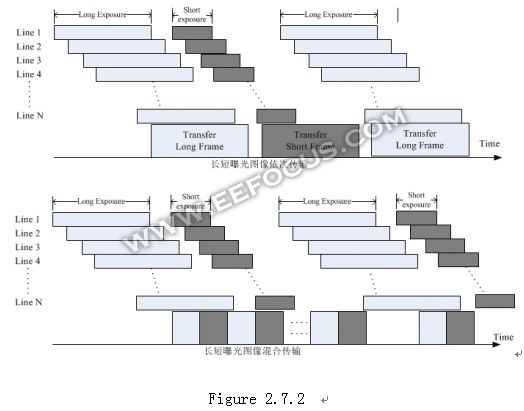
Figure 2.7.2
对于依次传输的模式,要做二合一融合,必须要把长曝光的整幅图像先存起来,用SRAM的话显然面积会非常庞大,成本太高,因此需要存到系统的DRAM中,等短曝光的图像收到的时候再从DRAM中取出来。这样会占用DRAM的1个Frame存储空间,以及1次读Frame和1次写Frame的带宽。对于混合传输模式,除了可以同样采取把长曝光数据存储到DRAM中的方法以外,也具有把数据放入SRAM的可能性,这要看混合传输时block 大小。以FHD为例,假设先传输100 line的长曝光图像数据,再传输100 line的短曝光图像数据,需要把1920*100=192K个pixel存储到SRAM中,为了减小size,通常会在Bayer pattern domain做HDR合成,以pixel为10-bit为例,Totalsize为192K*10/8=240K bytes,成本或许可以接受。
HDR算法种类较多,我这里大概介绍一下基本思想。有基于直方图统计特征,进行亮度重新映射的方法,类似于直方图均衡化。有局部处理法,结合整体图像亮度和局部区域对比度,保留细节又压缩范围。有转换到对数域(人眼对亮度的敏感度类似对数关系)进行压缩的方法。有对图像进行分层,分为基础层和细节层,保留细节层,对基础层进行范围压缩的方法。各种方法可以相互融合借鉴,对于IC设计来说,最关键的还是性价比。
2.8 亮度小结
以上介绍了和图像亮度相关的ISP function,内容并不全面,还有一些对比度增强类的算法(例如去雾)没有描述,请大家包涵。下一章介绍图像色彩。
3. 图像色彩
尽管CMOS sensor模拟了人眼的三原色(RGB)视觉感受,见figure 1.1.1,但是CMOS的工艺特性和人眼还是有很大的差异,因此需要ISP来辅助,让其色彩尽量接近人的感受。与色彩相关最重要的function是自动白平衡AWB和色彩校正矩阵Color Correction Matrix,其他有饱和度Saturation,色相Hue,另外手机中一般拍照APP有各种色彩效果也会介绍。
这里需要介绍一个图形分析工具:Imatest,这个tool可以帮助分析图像的亮度,色彩,信噪比,锐利度,畸变等很多性能。
这个工具提供了评价图像质量的客观标准,有理论有数据,非常好用。不过也不能完全迷信工具,还是要以人眼看到的情况为准,没有完美的数学模型可精确模拟人的视觉感受。有时候测出来的数据很好看,实际效果却很难看。例如,评测数据是基于整幅图像而计算出来的平均值,而人眼往往会特别关注一些个别点,只要某一点不好就会无法接受,而不管其他所有地方都不错。
3.1 自动白平衡AWB
首先介绍一下色温的概念。色温源自普朗克定义的黑体受热辐射,单位是K(kelvin),用于定义光源颜色,热黑体辐射体与光源的色彩相匹配时的开尔文温度就是光源的色温。来看一下色温的大致范围:
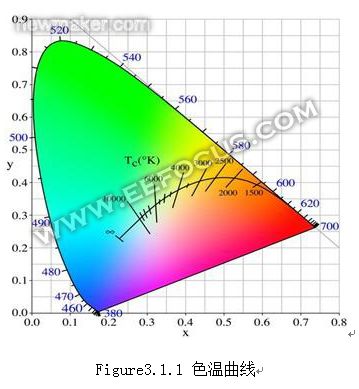
这是一份在XYZ色彩空间的光源色温曲线,可以看到色彩偏红时色温较低,色彩偏蓝则色温较高。一般烛光在1800K,阴天为5000K,晴天为6500K,蓝色天空在10000K以上。在实际场景中,光源的颜色未必刚好在这条色温曲线上,很可能有一些偏差。
AWB要做的事情,是要让白色的物体,在任何色温条件下,都显示成白色,这是sensor色彩校正的第一步。这里先要说明一下人眼就有非常快速和精准的AWB,以至于我们很少察觉到。举例来说,有一张白纸,不论在什么环境下,我们人眼都会认为是白色的,只有在光源色温大幅度且快速切换的一瞬间(例如开灯/关灯),才会感觉到白纸会变色一下,然后马上又变白了。而CMOS sensor拍摄到的图片,受色温的影响很大,而且Sensor 本身对RGB三个分量的敏感度也不一样(figure3.1.2),因此sensor输出的原始图片和人眼所见差异很大。AWB算法就是要克服sensor本身特性和人眼的不一致,以及解决色温对图像色彩的影响。Sensor输出原本色彩和经过ISP校准后的色彩对比如figure3.1.3. 这里ISP中色彩处理包括AWB和CCM.



人眼的AWB是根据周围环境和既往的经验来实现的,这里ISP算法也一样需要经验。针对任意一款sensor和lens的组合,我们都需要做一些实验,通过这些实验来获取相关的数据,作为这个组合的经验值。实验需要一个灯箱,灯箱中有不同色温的几种光源可做选择,通常有A光源,CWF,D65等色温从低到高的几种光源,灯箱背景为纯灰色(和白色等价)。用sensor 拍摄不同光源下的灯箱背景或者标准测试灰卡,抓取原始的Bayer pattern图片。
白色和灰色物体,在图像数据中体现为R,G,B三个分量相等,YCbCrdomain中Cb和Cr都为128. 我们通常在Bayer pattern domain或者RGB domain中来做AWB算法,那么就是要让白色和灰色物体的R=G=B。我们拍摄到的图片中,这三者是不相等的,我们可以统计出整幅图中平均的两个比例值G/R和G/B,很容易想到,如果对图像中所有的R分量乘以G/R,所有的B分量乘以G/B,那么图像就会变成白色或者灰色。我们可以用G/R和G/B来构建二维空间,观察不同光源条件下这两个数值的分布情况,如下图。

接下来我们需要在这个二维空间中描述一个闭合空间,这个闭合空间代表了可能是白色(灰色)物体的G/R和G/B的取值范围。在上图中,是用一个非常简单的方法,用几条直线勾勒出一个多边形作为闭合空间。这个闭合空间必须包含大部分光源的情况。也就是说,假设有个白色(灰色)物体,不论在何种常见光源下,统计出来的两个数值都会落在这个闭合空间内。这个闭合空间不能太大也不能太小,太大可能有很多其他颜色被误认为白色,太小则容易找不到白色而不稳定。那么如果确定了闭合空间的形状,在拍摄实际场景时,如果场景中有白色/灰色物体,那么就可以统计出落在闭合空间范围的像素点数,以及这个闭合空间内这些像素的平均G/R和G/B,分别记为R_gain和B_gain,对整幅图像的R分量乘以R_gain,B分量乘以B_gain,就算达到白平衡了,同时可以利用这两个Gain获得近似的色温,这里的逻辑关系并不严密,很可能有些物体并非白色而被误认为白色,所以AWB算法总是存在一定的误判概率。如果图像中没有找到落在闭合空间范围内的像素(或者太少不足以用作参考),那么通常会保持原先的R_gain和B_gain,或者采用灰度世界算法。灰度世界算法是假设Sensor 拍到的画面中所有像素的平均色彩应该是灰的,即R=G=B,于是把整幅图像的所有像素(而不仅仅是闭合空间内)都统计进去,计算出一个全局平均的R_gain和B_gain,由于拍摄内容的不确定性,这两个gain可能偏离真实情况很远(例如拍摄鲜艳的红色),因此需要做最大值和最小值限制,避免出现极端异常情况。相比于前面找白色物体的方法,灰度世界算法相对比较稳定,总是能计算出大概的gain值,缺点是很可能不正确,受大色块影响比较严重。在实际应用中,通常会结合这两种方法的优点,加上额外的限制条件,衍生出更加稳定和有效的AWB算法。
在统计上,为了避免大色块对AWB的影响,通常会对图像进行网格状分割,对每个矩形框内的数据独立统计,如果某个网格的数据偏离闭合空间很远的话,就认为是大色块而不参与AWB gain计算。
AWB的精准性是可以通过Imatest 测试的,要求在各种色温下,拍摄24色卡的最下面6个方块不能有颜色,这个通常很容易达到。

CMOS sensor拍摄的场景可能时时在变化,每次计算AWB得到的Gain会不一致,有时候甚至相差很多,如果实时调整AWB gain的话会让视频画面的色彩有跳跃感,看起来不舒服。为此,通常会做两点,一是AWB gain计算有一个稳定区间,每次计算所得AWB gain后会映射到某个色温C,假设原先的C和当前计算所得的C差异不大(小于某个阈值)的话,就不做调整,也就是说当画面色温变化不大的时候白平衡不变;二是两次色温差异超过阈值,需要调整的话,要采用渐进式慢慢的调整,例如R_gain原本为1.0,调整为2.0,那么每个Frame gain增加0.01,需要100个Frame才能调整到位,以30fps为例,就需要3.3秒时间,这样画面会渐渐的转变过去,看起来比较柔和舒适,没有闪烁的感觉。
3.2Color Correction Matrix
色彩校正矩阵CCM 通常在RGB domain 进行,并且在AWB之后。AWB把白色校正了,相应的其他色彩也跟着有明显的变化,可以说色彩基本正确了,只是饱和度有点低,色彩略有点偏差。CCM就是要保持白色(灰色)不变,把其他色彩校正到非常精准的地步。先看一下CCM计算公式。
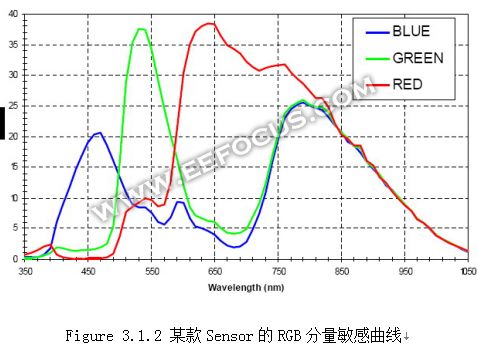
这里CCM之前的像素为[r,g,b]’,CCM之后的像素为[R,G,B]’。 CCM的实现比较简单,就是一个简单的矩阵运算,它的困难在于如何确定矩阵的系数。我们先分析一下这个矩阵中系数的物理意义。C00表示r分量对R的影响,C01和C02分别表示g和b分量对R的影响,假设CMOS的模型完全吻合人眼模型,那么显然C00=1,C01=C02=0,实际上CMOS image sensor中的滤镜不能完全过滤掉那些不希望看到的光波,如图Figure 3.1.2。CCM前后的效果比对大致如下。

在Figure3.1.2中,X轴表示光波的波长,三条不同color的曲线分别表示某CMOS sensor中三种感光单元对不同光波频率的敏感程度。 CMOS sensor感光单元所接受的光波频率普遍太宽,三种色彩出现混叠,导致图像的色彩不够鲜艳。为了消除这种混叠,CCM中的系数就具有一种普遍的规律,系数C00,C11,C22都大于1,其他的系数则都小0或者近似0。G对R的影响要大于B对R的影响,所以C01的绝对值要比C02的绝对值大。同样,C21的绝对值要比C20的绝对值大。
CCM不能改变白色。白色意味着r=g=b时,计算结果R=G=B=r=g=b,由此我们可以得出:

以上公式是CCM必须坚持的原则,这样原本9个独立的系数可以缩减为6个,我们把C00,C11和C22用其他的系数表示。根据经验我们再设定其他6个系数的取值范围,例如可以约束C01范围是[-3,0],C02范围是[-1,0]。要得出这6个系数的确切数值,过程有点复杂,首先来看Imatest对色彩的评价方法。
拍在灯箱中各种色温下的24色卡图片,从图片中取出24个色块所代表的颜色,转换到Lab色彩空间,和标准的24色卡颜色进行比较。如下图右

在Figure3.2.2右侧的图片中,小方块代表24个标准色在Lab空间的坐标,小圆点表示实测出来的24种颜色在Lab空间的坐标,二者之间的连线表示误差大小。通常认为误差越小越好,圆点往外侧偏移表示色彩太鲜艳,往内侧偏移表示色彩太淡,其他方向表示色彩偏差。
我们要找出CCM中的系数,也要建立一个和imatest类似的评价体系。先回顾一下ISP框架,在CCM之后还有Gamma,Hue和saturation会对图像色彩和亮度产生影响,而评测的图像是ISP的最终输出。所以要找出CCM系数,首先要建立一个ISP色彩和亮度模型,如下图。我们认为一般情况下用户不需要去调整亮度,对比度,饱和度以及色调等参数,这些模块的默认参数不对图像色彩和亮度产生任何影响。没有影响的模块我都改成灰色,剩下三个有颜色的模块是需要参与CCM系数寻找的。
建好了模型,还需要注意一点:由于sensor的感光动态范围和24色卡标准色有差异,并且图像平均亮度也可能有差异。我们对标准色做亮度调整(乘法)和动态范围调整(调对比度),使之尽量符合当前这张图像的平均亮度和动态范围,见figure3.2.4。换句话说,就是让标准24色下方的6个黑白色块,在变换后的亮度尽可能和当前输出的图像接近。

有了模型和目标之后,接下来就是选择一种机制来找出最优的CCM系数。这里每人都可以发挥个人想象力,尽量找出最优的结果,最“笨”但有效的方法就是遍历,在一定精度条件下遍历所有的可能性,找出误差最小的那组系数。在搜索CCM系数的时候,有不少误区,例如只看色彩误差数据ΔC,当搜索范围设置不合理,图像饱和度偏低的时候,计算出来的ΔC会很小,实际效果很难看。
在不同色温下,CCM的系数也有较大的差异,所以一般在ISP中存有多组CCM系数。在实际使用过程中,需要通过AWB计算出当前色温,然后选择合适的CCM系数,或者几组CCM系数的线性组合。在low light Noise较大的情况下,有时还会减小CCM系数绝对值以降低Noise。AWB解决了sensor 的R,G,B敏感度差异和色温的影响,CCM则是纠正R,G,B感光之间的相互干扰,使图像更接近于人眼。两者结合就算把色彩纠正完成了。
3.3Saturation
饱和度Saturation是指色彩的鲜艳程度,在YCbCr空间来看,Cb和Cr等于128时,饱和度为0,|Cr-128|和|Cr-128|越大,饱和度也越大,饱和度的计算公式非常简单。
f(x,s)=(x-128)*s + 128, x=Cb or Cr,s>=0
表达式中s表示饱和度调整幅度,s=1表示不调整,s=0表示灰度图,0

Figure3.3.1Saturation从左到右分别为s=0, 0.5, 1, 2
饱和度调整也可以通过CCM来完成,不过CCM找出的是根据人眼模型得出的标准系数,不宜随意改变。在Ycbcr空间的这种简单计算,适合于根据用户喜好而调整的情况。例如我们知道sony相机拍出的照片色彩比较鲜艳,就可以用这个方法实现。
3.4 Hue
Hue的本意是色彩的转换,在RGB空间有较明显的意义,例如当转过120度的时候红色变成绿色,绿色变成蓝色,蓝色变成红色。至于为什么要这么转,其实也没什么道理,除了特效摆酷外,hue一般不会被用到。但Hue是ISP标配,所以还是要说明一下。在Ycbcr domain,Hue意义不能直观的理解,我知道有用三角函数对Cb和Cr分量处理的方法,于是自己做实验琢磨,下面给出Hue转换的近似算法,如有雷同,纯属巧合。
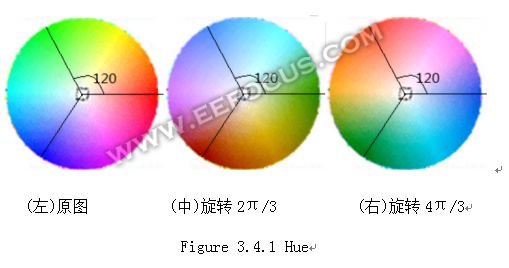
假设用户设定需要色彩旋转的角度为α,记D=Cb-128,E=Cr-128。D’和E’为转过α后的数值。
D’=D*cos(x) + E*sin(y)
E’=E*cos(y) +D*sin(x)
当α=0,x=0,y=2π;
当α=2π/3,x=3π/4,y=3π/2;
当α=4π/3,x=3π/2,y=3π/4;
当α=2π,x=2π,y=0;
这里我只实验得出了α为4个关键角度时的x和y取值,当α为其他角度时,x和y可用两点之间线性插值得到。变换过程中Y保持不变,Cb’=D’+128,Cr’=E’+128。这里的4个三角函数可以事先由软件计算好,数字IC只要实现乘加运算。从整体效果来看,色彩确实按照期望的方向在旋转,但是并不完美。
3.5各种色彩特效
接下来说说YCbCr空间对色彩的一些变化,算法比较简单。
- 灰度图:把Cb和Cr直接改为128,Y不变;
- 黑白二值图:在灰度图的基础上,对Y做二值化。一部分取值为0,另一部分取值为255,大致算法为:计算整幅图像均值和局部区域均值,得出一个相对均值,把当前像素和这个相对均值做比较,再对应到一个概率密度分布函数,把当前像素按照这个概率映射成0或者255;如下。

- 冷色调和暖色调;对所有像素的Cb和Cr加上一个固定offset。

- 各种P图软件中的色调,例如温暖,黄昏,冷清,淡雅,青春等等。大致公式如下:定义一个场景模式,即对所有像素的Cb和Cr分量设定一个目标值Cb_target和Cr_target。
Cb’=Cb_targte*α + Cb*(1-α); Cr’=Cr_targte*α + Cr*(1-α);公式中α为调整比例。各种效果如下,第一幅为原图,其他为各种色调。

3.6 色彩小结
ISP中色彩相关的function就以上几个,就算法复杂度来说,色彩在ISP中是相对较简单的,但是人眼对色彩比较敏感,因此这部分比较重要,需要理解数学计算和实际效果之间的关系,才能恰当自如的满足用户需求。下一章将介绍细节部分。
4.细节
细节部分会介绍去噪denoise,Bayer pattern 转 RGB(即interpolation),Edge enhance(即Sharp)以及边缘伪彩色false color。这部分内容是ISP中最复杂的,需要较庞大的计算量和Memory。任何一个function都可以在网上找到不少的论文,这里我只说明一些基本原理和关键因素,不讨论详细的实现算法。
4.1 去噪Denoise
首先我们把Noise 分成三类,分别是高斯白噪声,坏点,受伤点。这三类分别有不同的处理方法。
坏点Dead pixel是指有些像素不受拍摄景物影响,始终为固定的一个数值,通常为最大值或者最小值,也就是常说的亮点和黑点。检测坏点的算法比较容易,因为坏点和周围的像素差异非常大,检测出来之后,可以用附近点均值替换即可。
受伤点wound pixel是指有些点在低照度下,sensorgain很大的时候,会出现一定的偏差,能够被人眼明显察觉。这些受伤点输出的值不固定,同时也受拍摄景物影响,例如比周围正常像素的数值大一些,形成不太明显的亮点,有时候还会随着时间改变,一闪一闪的。对于受伤点,不是很容易被检测输出来,好在它一般只出现在暗光条件下,如果受伤点处在平坦区域,那么可以用最大值(最小值)替换,或者中值滤波等方法消除,如果正好处在边缘上,那么就较难辨别出来,中值滤波等处理方法会使得图像模糊。坏点和受伤点对应到课本中就是椒盐噪声。
一般我们说的噪声都是指高斯白噪声,噪声的大小和sensor的增益大小成比例关系,同时ISP中的很多运算(例如Gamma,LSC,AWB,CCM等)都会放大Noise幅度。从频域来看,噪声遍布整个频域。对于高频噪声,比较容易消除,但是高频噪声和实际景物容易混淆,消除噪声的时候也会使得图像模糊。对于低频噪声,就需要花代价来消除,在任何二维空间域的去噪算法中,都需要一个以当前像素为中心的窗口,这个窗口越大,就越能检测出低频的Noise,同时也意味着越多的Memory和计算量。从空间域来看,落在平坦区域的Noise比较容易消除,落在景物边缘的Noise则真假难辨,必须在清晰度和Noise之间做一个折中的选择。
我所知道的可用于ISP中去除Noise的方法大概有以下一些分类(没有广泛研究过,肯定有疏漏,请包涵)。
1.首先是空间域和时间域的划分。图像是二维的,空间域是指仅对一幅图像中的二维数据处理,一般照片的去噪都是在二维空间域。时间域是指多帧图像之间的去噪,在视频中,前后Frame有着较大的相关性,对于静态场景来说就更加明显。空间域去噪算法需要考虑的是Noise和图像清晰度之间的权衡,而时间域去噪算法需要考虑的是Noise和移动物体的拖尾残影现象的权衡。
2.其次是基于位置和基于数值的划分。要消除Noise,一般人第一个想到的方法就是低通滤波器,以当前像素为中心,选择一个一定范围的中心对称的低通滤波器,到中心距离越近,对应位置像素的weighting越高,越远则越小,这就是基于位置的方法。另外一种是基于数值的方法,先同样选择以当前像素为中心的一个范围,把这个范围内的像素按照数值大小来排成一个序列,然后再做处理,处理的方法可以是直接选择某些点(例如最大值/最小值替换,中值滤波),也可以对这个序列再做低通滤波计算。鼎鼎有名的双边滤波就是结合了位置和数值两种思想合二为一的算法,不过其公式计算太过复杂,不适合数字电路设计实现,但是其思想是完全可以借用的。
3.各种变换域的处理方法。例如傅立叶变换,离散余弦变换,最有名的就是小波变换。这些域变换的基本原理都差不多,基于人眼对高频分量较不敏感的特性,对转换域中的部分数据进行归0或者缩小,以达到消除Noise(或者图像压缩)的目的。小波变换效果较好,不过由于计算量很大,在ISP中实现有很大的难度。
在实际应用中,变换域的方法太过复杂,不适合实时视频处理,所以常用的还是上面两大类方法。一般来说Noise的幅度总是有限度的,和实际景物边缘的变化程度有较大差距,所以通常会在平坦区域尽可能的多消除noise, 而在物体边缘则尽量保护景物细节,少做denoise处理,根据景物内容动态调整去噪算法是必须的。在另一方面,Noise的幅度大小和sensor的增益相关,当环境变换导致AE gain变化的时候,Noise的幅度变化非常大,有些sensor在低光照条件下会有64倍的AE gain,Noise满屏跳跃,几乎掩盖实际景物。有时候常会说“评价ISP好坏,就是看暗光情况下的Noise大小”,不同的Noise 幅度意味着不同的ISP算法(或者算法中的参数),所以还需要SW根据实际情况来动态调整去噪算法。因此,在真实的ISP电路设计中,去噪算法的多样性和可调整性是非常必要的。
除了去噪算法以外,抑制Noise根源也是去噪的一个重要手段。Noise本身无处不在,问题根源在于Noise被不断放大,也就是各种增益Gain(或者说乘法)把Noise放大了许多倍。为了达到一定的亮度,Sensor的AE gain通常没有办法改变,能改变的只有ISP自身。常用的抑制Noise手段包括:
- 降低Lens shading correction曲线的幅度,让周边稍微暗一些,减少周边Noise。
- 降低Gamma curve在暗处的斜率,减少暗处Noise。
- 降低CCM系数绝对值,减少彩色噪声。
- 降低edge enhance幅度,减少景物边缘Noise。
去噪方法可以说是ISP中牵涉最广,实现难度最大的一个功能,它渗透进AE,LSC,Gamma,AWB,interpolation,edge enhance等多个function,是一个系统工程。
4.2Interpolation
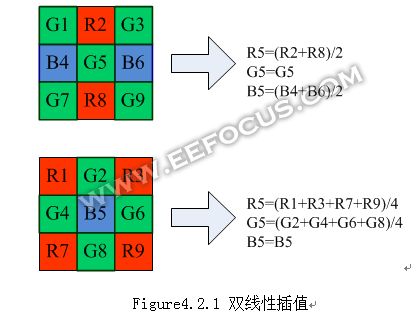
这里说的interpolation是指把Bayer patterndata 转化为RGB data的过程,每个像素都要有完整的[RG B]三个分量。先看一下最简单的双线性插值算法。
这是最简单原始的方法,确实可以得到一幅RGB图像,不过存在一些问题,例如拉链现象,有些模糊,分辨率不高,边缘有些彩色(false color)等。评价插值算法的好坏,通常用ISO12233测试纸,如下图。

观察细节算法的好坏,必须把图像放大到像素级别,直接研究数值大小,下面以拉链现象为例。拉链现象出现在水平或者垂直的边缘上,是由于G分量计算不当所致。以一条水平边为例,如下图,用双线性插值的话,在水平边缘上就会出现[90,82.5, 90, 82.5…]这样的循环重复规律。

从图像效果来看就是类似拉链状.
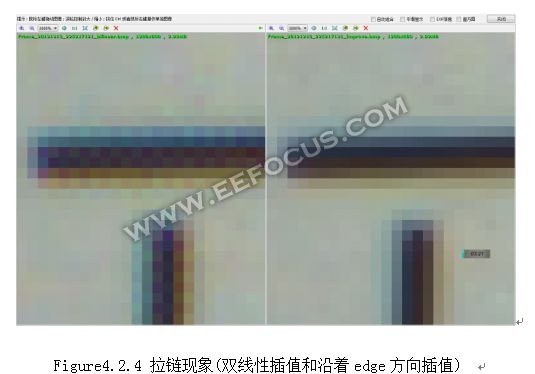
要解决拉链现象,保持边缘的光滑,很直观的想法就是对G分量采取沿着边缘方向去插值,在上图中,就让G5 =(G4 + G6)/2。这样就意味着要做边缘方向性的判断,如果是垂直边,那么就会是G=(G2+G8)/2,还有各种其他方向,则可以对周边四个G分量采用不同的加权平均算法得到中心点G分量数值。边缘方向判断是interpolation算法中最重要的一个环节,是各家ISP算法的核心之一,有兴趣的同学可以查看这个方面的论文。评价图像分辨率(清晰度)的一个指标,是看ISO12233中对细密纹理的识别程度。一个好的算法可以判断出只有一个像素宽度的细条纹。

在Bayer pattern中,一半像素是G,R和B都只占1/4,R和B信息缺失比较严重。在双线性插值算法中,R分量的计算只和周围的R相关,如果用G分量的信息去修正缺失的R分量,那么清晰度会有不小的提升。以水平方向的边缘为例:
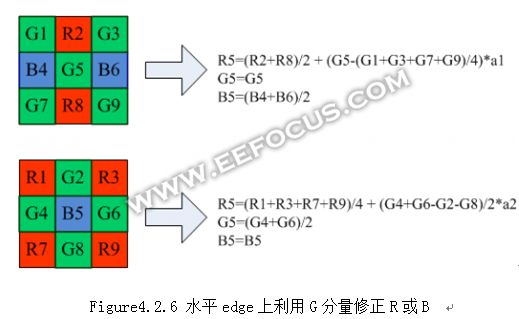
上图中a1和a2是修正系数,范围在0~1之间。这种常用的计算方法不仅提高了清晰度,也可以缓解false color现象。不过从另一方面来看,这种修正会增加Noise幅度,原本R分量自身有一定的Noise分布概率,现在叠加了G分量的Noise,那么最大Noise幅度会提高。因此系数a1和a2需要根据场景,Noise幅度等因素权衡选择。
整体来说,Interpolation算法大致过程就是先边缘方向检测,然后沿着方向去做插值,兼顾Noise和清晰度的平衡,顺便还可以做一些false color的处理。
4.3Edge enhance
边缘增强Edge enhance和一般所说的sharp是一个近似的概念。我这样区分二者:sharp是对图像所有内容增加锐利度,包括Noise也会被放大;而edge enhance是要让真正的edge变得锐利,Noise则尽量不被放大显现出来。从算法上来说Sharp很好实现,任何课本中都会提到sharp算子,而edge enhance则要有效区分出edge和Noise,并且判断edge方向来做增强,增强的方法也很有难度,既要达到一定的锐利度MTF,又要解决边缘粗糙roughness,overshot和undershot等问题。
边缘增强一般在YCbCr空间进行,并且只对Y分量处理,Cb和Cr保持不变,其原理如下:
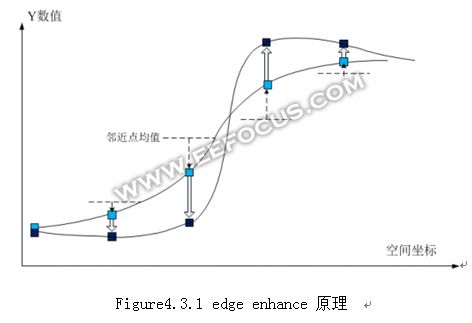
Figure4.3.1 edgeenhance 原理
浅蓝色为原值,深蓝色为enhance之后的数值。从波形上看,edgeenhance就是要让线条的斜率更陡一些,甚至允许出现小幅度的过冲。从数值上来看,就是让数据朝着远离邻近点均值的方向走,而且和邻近点均值的差越大,走过的距离也越大,把当前像素值和邻近点均值的差记为d;另外,edge enhance的幅度还和整个edge的变化范围有关,可以认为上图中最大值和最小值的差,记为g;最后是用户设定的锐利度s,这三者可以得出像素的edge enhance函数H(x)。
H(x)= x + f(d, g, s)
f(d, g, s)是一个和d,g,s三者都正相关的函数,但并非线性关系。这里没有统一的数学模型可以给出答案,只有仔细研究规律,多做实验,可以说的是想要得到较好的视觉效果,这个模型非常复杂,参数众多。通过不断的对参数调试练习,慢慢建立起数学计算模型和实际图像效果之间的映射关系,才能较好的平衡锐利度MTF和roughness,overshort,undershort等因素。
为了避免把Noise enhance出来,edge enhance在实现中还需要判断当前像素处于光滑区域还是物体边缘。当处于光滑区域的时候,则不要做edge enhance运算,或者做的幅度很小;只有在较明显的边缘上才做处理,这样避免不了边缘上的noise的影响,所以在锐利度s设定较大的时候,可以发现边缘上会有Noise闪动跳跃的情况。为了缓解这种Noise的跳跃,通常会对f(d, g, s)做最大值和最小值限制保护,并且沿着edge 方向做低通滤波来缓解Noise。

整个Edge enhance的大致流程为先判断平坦区域还是边缘,对平坦区域可以不做或者少做edgeenhance(甚至做smooth处理),对边缘要判断幅度大小,边缘方向,选则相对应的高通滤波器处理,最后对enhance的幅度做一定程度的保护处理。
4.4False color
False color一般出现在物体边缘上,特别是白纸黑字。如下,白纸上的黑色线条,一侧偏黄,一侧偏蓝。

False color的原因有两个,一是bayer pattern中R和B信息丢失比较严重,插值出来的R和B分量带有误差;二是镜头对不同波长的光的折射率不一样。前者比较容易理解,后者则可以通过观察发现规律。对ISO12233测试纸拍摄图片,我分别截取四周的局部图片,放大比较来看。

False color的原因有两个,一是bayer pattern中R和B信息丢失比较严重,插值出来的R和B分量带有误差;二是镜头对不同波长的光的折射率不一样。前者比较容易理解,后者则可以通过观察发现规律。对ISO12233测试纸拍摄图片,我分别截取四周的局部图片,放大比较来看。



左下角

从上图中可以发现,黑色方块靠近图像中心的边缘有点橙色,背离中心的边缘呈现蓝色。以左上角的黑色方块为例,三种颜色分量的数值曲线有位移,如果其位移的规律按照figure4.3.3的形状,那么刚好可以解释边缘偏色的情况。
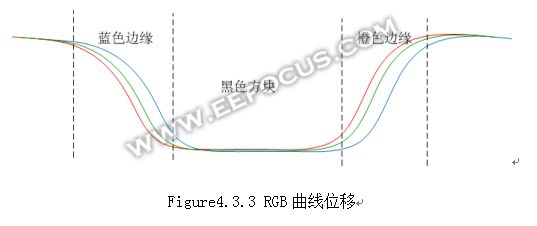
如果可以纠正这种位移,那么false color就可以明显消除。从原理上分析,解决方法比较简单,只要把B分量向着中心位置收缩,收缩的距离和像素到镜头中心的距离有关,这可以通过数学建模得到(例如抛物线)。同样R分量则要向外扩张,扩张的方式也一样用数学建模得到。实现起来则有不小难度,毕竟像素是按照矩阵方式排列的,而收缩或者扩张是360度的,需要复杂的三角函数和数据流控制机制。
对位移较小的false color处理起来相对容易,毕竟我们已知其规律,并且有周边像素作为参考。对于较大范围的false color(上图中位移较大的情况)则难有很好的解决方法,因为在当前像素的一个小范围内都是异常的色彩,无法分辨到底是true or false。
4.5小结
细节相关的function都比较复杂,较难像色彩和亮度那样直观的理解。我自己感觉细节设计其实就是数学和信号处理,需要细致的思考和探究,种种现象都可以从数学上找到对应的关系。另外像自动对焦Auto focus和缩放Zoom也和细节设计相关,前者需要边缘检测,后者需要多采样滤波。
转载于http://www.eefocus.com/component/m/375610/r0#comment-171860
如有侵权,请通知,立即删除。