Tensorflow c++ 实践及各种坑
Tensorflow c++ 实践及各种坑
在这篇文章中:
- 实现方案
- 实现步骤
- (1) 源码编译
- (2) 模型训练与输出
- (3) 模型固化
- 坑 BatchNorm bug
- (4) 模型加载及运行
- (5) 运行问题
Tensorflow当前官网仅包含python、C、Java、Go的发布包,并无C++ release包,并且tensorflow官网也注明了并不保证除python以外库的稳定性,在功能方面python也是最完善的。众所周知,python在开发效率、易用性上有着巨大的优势,但作为一个解释性语言,在性能方面还是存在比较大的缺陷,在各类AI服务化过程中,采用python作为模型快速构建工具,使用高级语言(如C++,java)作为服务化程序实现是大势所趋。本文重点介绍tensorflow C++服务化过程中实现方式及遇到的各种问题。
实现方案
对于tensorflow c++库的使用,有两种方法:
(1) 最佳方式当然是直接用C++构建graph,但是当前c++tensorflow库并不像python api那样full-featured。可参照builds a small graph in c++ here, C++ tensorflow api中还包含cpu和gpu的数字内核实现的类,可用以添加新的op。可参照https://www.tensorflow.org/extend/adding_an_op
(2) 常用的方式,c++调用python生成好的graph。本文主要介绍该方案。
实现步骤
(1) 编译tensorflow源码C++ so(2) 模型训练输出结果(3) 模型固化(4) 模型加载及运行(5) 运行问题
(1) 源码编译
环境要求: 公司tlinux2.2版本, GCC版本 >= 4.8.5安装组件: protobuf 3.3.0 bazel 0.5.0 python 2.7 java8机器要求: 4GB内存
a. 安装java8
yum install java
b. 安装protobuf 3.3.0
下载https://github.com/google/protobuf/archive/v3.3.0.zip
./configure && make && make install
c. 安装bazel
download https://github.com/bazelbuild/bazel/releases
sh bazel-0.5.0-installer-linux-x86_64.sh
d. 编译源码
最好采用最新release版本:https://github.com/tensorflow/tensorflow/releases
bazel build //tensorflow:libtensorflow_cc.so
编译过程中可能遇到的问题:问题一: fatal error: unsupported/Eigen/CXX11/Tensor: No such file or directory
安装Eigen3.3或以上版本问题二: java.io.IOException: Cannot run program "patch"
yum install patch
问题三: 内存不够

(2) 模型训练与输出
模型训练输出可参照改用例去实践https://blog.metaflow.fr/tensorflow-saving-restoring-and-mixing-multiple-models-c4c94d5d7125, google上也很多,模型训练保存好得到下面文件:

(3) 模型固化
模型固化方式有三种:
a. freeze_graph 工具
bazel build tensorflow/python/tools:freeze_graph && bazel-bin/tensorflow/python/tools/freeze_graph
--input_graph=graph.pb
--input_checkpoint=checkpoint
--output_graph=./frozen_graph.pb
--output_node_names=output/output/scores
b. 利用freeze_graph.py工具
# We save out the graph to disk, and then call the const conversion
# routine.
checkpoint_state_name = "checkpoint"
input_graph_name = "graph.pb"
output_graph_name = "frozen_graph.pb"
input_graph_path = os.path.join(FLAGS.model_dir, input_graph_name)
input_saver_def_path = ""
input_binary = False
input_checkpoint_path = os.path.join(FLAGS.checkpoint_dir, 'saved_checkpoint') + "-0"
# Note that we this normally should be only "output_node"!!!
output_node_names = "output/output/scores"
restore_op_name = "save/restore_all"
filename_tensor_name = "save/Const:0"
output_graph_path = os.path.join(FLAGS.model_dir, output_graph_name)
clear_devices = False
freeze_graph.freeze_graph(input_graph_path, input_saver_def_path,
input_binary, input_checkpoint_path,
output_node_names, restore_op_name,
filename_tensor_name, output_graph_path,
clear_devices)
c. 利用tensorflow python
import os, argparse
import tensorflow as tf
from tensorflow.python.framework import graph_util
dir = os.path.dirname(os.path.realpath(__file__))
def freeze_graph(model_folder):
# We retrieve our checkpoint fullpath
checkpoint = tf.train.get_checkpoint_state(model_folder)
input_checkpoint = checkpoint.model_checkpoint_path
# We precise the file fullname of our freezed graph
absolute_model_folder = "/".join(input_checkpoint.split('/')[:-1])
output_graph = absolute_model_folder + "/frozen_model.pb"
print output_graph
# Before exporting our graph, we need to precise what is our output node
# This is how TF decides what part of the Graph he has to keep and what part it can dump
# NOTE: this variable is plural, because you can have multiple output nodes
output_node_names = "output/output/scores"
# We clear devices to allow TensorFlow to control on which device it will load operations
clear_devices = True
# We import the meta graph and retrieve a Saver
saver = tf.train.import_meta_graph(input_checkpoint + '.meta', clear_devices=clear_devices)
# We retrieve the protobuf graph definition
graph = tf.get_default_graph()
input_graph_def = graph.as_graph_def()
# fix batch norm nodes
for node in input_graph_def.node:
if node.op == 'RefSwitch':
node.op = 'Switch'
for index in xrange(len(node.input)):
if 'moving_' in node.input[index]:
node.input[index] = node.input[index] + '/read'
elif node.op == 'AssignSub':
node.op = 'Sub'
if 'use_locking' in node.attr: del node.attr['use_locking']
# We start a session and restore the graph weights
with tf.Session() as sess:
saver.restore(sess, input_checkpoint)
# We use a built-in TF helper to export variables to constants
output_graph_def = graph_util.convert_variables_to_constants(
sess, # The session is used to retrieve the weights
input_graph_def, # The graph_def is used to retrieve the nodes
output_node_names.split(",") # The output node names are used to select the usefull nodes
)
# Finally we serialize and dump the output graph to the filesystem
with tf.gfile.GFile(output_graph, "wb") as f:
f.write(output_graph_def.SerializeToString())
print("%d ops in the final graph." % len(output_graph_def.node))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--model_folder", type=str, help="Model folder to export")
args = parser.parse_args()
freeze_graph(args.model_folder)
坑 BatchNorm bug
在具体实际项目,用方式一与方式二将生成的模型利用tensorflow c++ api加载,报以上错误,采用tensorflow python加载模型报同样错:
原因是模型中用到了BatchNorm,修复方式如上面c中给出的方案
(4) 模型加载及运行
构建输入输出
模型输入输出主要就是构造输入输出矩阵,相比python的numpy库,tensorflow提供的Tensor和Eigen::Tensor还是非常难用的,特别是动态矩阵创建,如果你的编译器支持C++14,可以用xTensor库,和numpy一样强大,并且用法机器类似。如果是C++11版本就好好看看eigen库和tensorflow::Tensor文档吧。例举集中简单的用法:
矩阵赋值:
tensorflow::Tensor four_dim_plane(DT_FLOAT, tensorflow::TensorShape({1, MODEL_X_AXIS_LEN, MODEL_Y_AXIS_LEN, fourth_dim_size}));
auto plane_tensor = four_dim_plane.tensor<float, 4>();
for (uint32_t k = 0; k < array_plane.size(); ++k)
{
for (uint32_t j = 0; j < MODEL_Y_AXIS_LEN; ++j)
{
for (uint32_t i = 0; i < MODEL_X_AXIS_LEN; ++i)
{
plane_tensor(0, i, j, k) = array_plane[k](i, j);
}
}
}
SOFTMAX:
Eigen::Tensor<float, 1> ModelApp::TensorSoftMax(const Eigen::Tensor<float, 1>& tensor)
{
Eigen::Tensor<float, 0> max = tensor.maximum();
auto e_x = (tensor - tensor.constant(max())).exp();
Eigen::Tensor<float, 0> e_x_sum = e_x.sum();
return e_x / e_x_sum();
}
模型加载及session初始化:
int32_t ModelApp::Init(const std::string& graph_file, Logger *logger)
{
auto status = NewSession(SessionOptions(), &m_session);
if (!status.ok())
{
LOG_ERR(logger, "New session failed! %s", status.ToString().c_str());
return Error::ERR_FAILED_NEW_TENSORFLOW_SESSION;
}
GraphDef graph_def;
status = ReadBinaryProto(Env::Default(), graph_file, &graph_def);
if (!status.ok())
{
LOG_ERR(logger, "Read binary proto failed! %s", status.ToString().c_str());
return Error::ERR_FAILED_READ_BINARY_PROTO;
}
status = m_session->Create(graph_def);
if (!status.ok())
{
LOG_ERR(logger, "Session create failed! %s", status.ToString().c_str());
return Error::ERR_FAILED_CREATE_TENSORFLOW_SESSION;
}
return Error::Success;
}
运行:
0.10以上的tensorflow库是线程安全的,因此可多线程调用predict
int32_t ModelApp::Predict(const Action& action, std::vector<int>* info, Logger *logger)
{
...
auto tensor_x = m_writer->Generate(action, logger);
Tensor phase_train(DT_BOOL, TensorShape());
phase_train.scalar<bool>()() = false;
std::vector<std::pair<std::string, Tensor>> inputs = {
{"input_x", tensor_x},
{"phase_train", phase_train}
};
std::vector<Tensor> result;
auto status = m_session->Run(inputs, {"output/output/scores"}, {}, &result);
if (!status.ok())
{
LOG_ERR(logger, "Session run failed! %s", status.ToString().c_str());
return Error::ERR_FAILED_TENSORFLOW_EXECUTION;
}
...
auto scores = result[0].flat<float>() ;
...
return Error::SUCCESS;
}
(5) 运行问题
问题一:运行告警
2017-08-16 14:11:14.393295: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations.
2017-08-16 14:11:14.393324: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations.
2017-08-16 14:11:14.393331: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations.
2017-08-16 14:11:14.393338: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.
是因为在编译tensorflow so库的时候没有把这些CPU加速指令编译进去,因此可以在编译的时候加入加速指令,在没有GPU条件下,加入这些库实测可以将CPU计算提高10%左右。
bazel build -c opt --copt=-mavx --copt=-mfma --copt=-mfpmath=both --copt=-msse4.2 -k //tensorflow:libtensorflow_cc.so
需要注意的是并不是所有CPU都支持这些指令,一定要实机测试,以免abort。
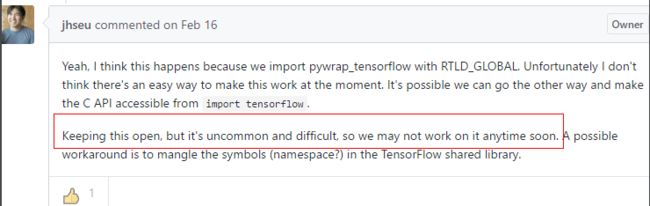
问题二: C++ libtensorflow和python tensorflow混用
为验证C++加载模型调用的准确性,利用swig将c++ api封装成了python库供python调用,在同时import tensorflow as tf和import封装好的python swig接口时,core dump
该问题tensorflow官方并不打算解决