王爽 汇编语言第三版 第9章 转移指令的原理
第九章 转移指令的原理


汇编代码:
assume cs:codesg
codesg segment
s:
mov ax,bx ; mov ax,bx 的机器码占两个字节
mov si, offset s
mov di, offset s0
mov ax, cs:[si]
mov cs:[di], ax
s0:
nop ; nop 机器码占一个字节
nop
mov ax, 4c00h
int 21h
codesg ends
end s

9.3 依据 位移 进行 转移的 jmp 指令

9.5 转移地址 在 寄存器 中的 jmp 指令

9.6 转移地址在内存中的 jmp 指令

检测点 9.1

分析:jmp word ptr [bx+1] 为段内转移,要CS:IP指向程序的第一条指令,应设置ds:[bx+1]的字单元(2个字节)存放数据应为0,则(ip)=ds:[bx+1]=0。简单来说就是,只要 ds:[bx+1] 起始地址的两个字节为 0 就可以了。
答案 1:db 3 dup (0)。 答案 2:dw 2 dup (0)。 答案 3:dd 0。 答案 4:dd 16 dup (0)
验证代码:
assume cs:codesg, ds:datasg
datasg segment
db 16 dup (0)
datasg ends
codesg segment
start:
mov ax, datasg
mov ds, ax
mov bx,0
jmp WORD ptr ds:[0]
mov ax,4c00h
int 21h
codesg ends
end start验证结果截图:

程序 2:

第一空参考答案:
mov [bx], bx ; 因为 bx 为 0,所以可以把 寄存器 bx 值赋值给 内存[bx]
mov [bx], word ptr 0 ; 指定 0 是一个 字类型 0000h,
mov [bx], offset start ; 取得 标号 start 相对 cs 段的偏移地址,即 0 第二空参考答案:
mov [bx+2], cs
mov [bx+2], codesg验证代码:
; jmp 段 间 转移。转移到 cs:ip 的第一条指令
; 高地址 : 转移的目的段地址
; 低地址 : 转移的目的偏移地址
assume cs:codesg, ds:datasg
datasg segment
dd 12345678H
datasg ends
codesg segment
start:
mov ax, datasg
mov ds, ax
mov bx, 0
mov [bx], WORD ptr 0
mov [bx+2], cs
jmp DWORD ptr ds:[0]
mov ax, 4c00h
int 21h
codesg ends
end start运行结果截图:






实验 8 分析一个奇怪的程序:
https://www.jianshu.com/p/7e5dfea72b65
assume cs:code
code segment
mov ax, 4C00H
int 21H
start:
mov ax, 0000H
s:
nop
nop
mov di, offset s
mov si, offset s2
mov ax, cs:[si]
mov cs:[di], ax
s0: jmp short s
s1: mov ax, 0000H
int 21H
mov ax, 0000H
s2: jmp short s1
nop
code ends
end start分析 :
程序的执行流程是这样的 :
; 从 start 标号开始
1. mov ax, 0000H
2. nop
3. nop
4. mov di, offset s
5. mov si, offset s2
6. mov ax, cs:[si]
7. mov cs:[di], ax
8. jmp short s
9. jmp short si ; 这句 jmp short s1 , 根据我们之前的分析 , 指令是用相对偏移来表示的
; 因此执行的操作并不是真的跳转到 s1 这个标号 , 而是跳转编译时确定的 该指令到 s1 标号的偏移
; 所以我们要分析接下来程序的流程的话 , 就必须先编译程序 , 然后要知道到底偏移是多少
; 然后再根据这个偏移确定程序下一步应该执行哪里的指令
; 根据下图的编译结果 , 可以发现 , jmp short s1 在编译后得到的指令是 :
; 偏移是 : EB F6
; 这个数据是使用 补码 来表示的 , 也就是说 , 是一个负数 , 然后符号位不变 , 其他位取反 , 然后加 1
; 然后 , 我们现在就知道了 , 这条指令是将 ip 的值加上 -10
; 我们再看看 ip - 10 指向的地址是哪里 ?
; 对 , 刚好就是 code segment 开始的位置
10. mov ax, 4C00H
11. int 21H
; 这样程序就实现了正常的返回反编译结果 :
注意这里使用 debug 的 u 命令进行反汇编的时候要指定代码段的偏移地址为 0
否则 debug 会自动从 start 标号的地方开始反汇编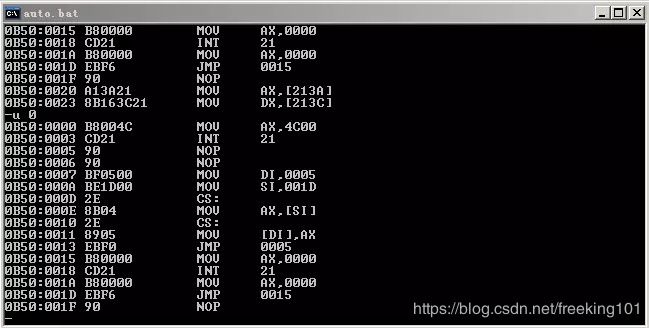
可以看到 :
jmp short s1 ; 这句汇编指令被翻译成了 : EB F6 , 其中 EB 表示的是跳转 , F6 表示偏移
F6 怎么理解呢 ?
1111 0110 (使用补码来表示)
补码转换成原码 , 符号位不变 , 其他位取反 , 然后加 1
1000 1001
1000 1010 ; 也就是 -10
也就是上面我们分析的让 (ip) = (ip) - 0x0A
然后 , 这句指令被复制到 s 标号的开头处
由于 nop 只占一个字节 , 因此两个 nop 被完全替代
然后程序执行到 s0 , 又跳转到 s 开始的地方
这个时候就要执行 : (这个时候 ip = 8)
EB F6
首先读取这条指令到指令缓存器里
接下来 , (ip) = (ip) + len(EB F6) = (ip) + 8 = 10
然后执行这条指令 , 即为 (ip) = (ip) - 10 = 0
这样 ip 就回到了 code segment 的起始处
这样继续执行
mov ax, 4C00H
int 21H
就实现了程序的正常返回
说明:这题要是把 s 当成 jmp short s1 那就错了,如果是那样的话 ,你就会想当然的跳到 s1,但其实不是的,前边复制的 是内存里的内容 ,也就是说复制的是 jmp short s1 的机器码 假如机器码是这样的: EB -10(十进制负数先理解嘛~) 也就是向上走10字节, 那么 现在复制到 s 那 也是向上走10 个字节,所以是跳转到 mov ax, 4c00h。
这道题主要理解:程序 只是 复制 内存里面的数据。
汇编语言是按行一条一条指令进行执行的,可以按高级语言进行缩进来写汇编程序 ( 例如可以按照 Pyhton 的空格缩进 ),最后再把缩进给去掉,这样可以更好的理解汇编的逻辑和层级关系。
实验 9

每一个字符占用两个字节 , 低地址为 ASCII 码 ,高地址为属性

示例代码 1:
assume cs:code,ds:data
; 显存地址 : B8000H - BFFFFH
; 显示尺寸 : 80 x 25 个字符
; 其中每一个字符占用两个字节 , 低地址为 ASCII 码 , 高地址为属性
; 也就是说 每一个字符 可以设置的属性有 256 种
; 属性 :
; 是否闪烁 背景色R 背景色G 背景色B 是否高亮 前景色R 前景色G 前景色B
; 因此一个屏幕总共有 80 x 25 = 2000 个字符 , 需要 4000 个字节来存储 (约为4K)
; 然后系统的显存总共是 32K , 也就是说可以储存 8 个页面 , 默认显示第一个页面
data segment
db 'Hello world', 33 ; 33 是感叹号的 ASCII 码
data ends
code segment
start:
mov ax, data
mov ds, ax
mov ax, 0B800H
mov es, ax ; 保存显存的段地址
mov si, 0000H ; 数据段偏移地址
mov di, 10*160+80 ; 显存偏移地址
mov cx, 000CH ; 设置循环次数 , "Hello world!" 长度为 12
print_green:
mov al, ds:[si] ; 读取数据段中的数据
mov ah, 00100000B ; 设置字体的属性 (黑底绿字)
mov es:[di], ax ; 写入显存
inc si ; 数据段偏移地址自增 1
add di, 0002H ; 显存偏移地址自增 2
loop print_green
finish:
mov ax,4c00H
int 21H
code ends
end start运行截图:

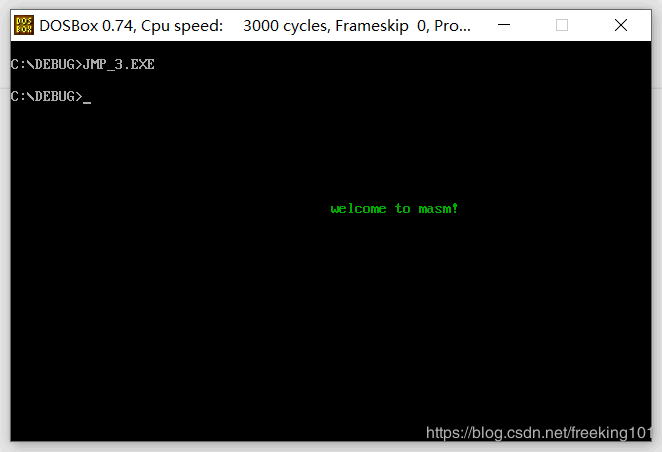
示例代码 2:
assume cs:codesg, ds:datasg
datasg segment
db 'welcome to masm!' ; 显示的字符
db 2,24h,71h ; 字符属性
datasg ends
codesg segment
start:
; 设置 ds 段
mov ax, datasg
mov ds, ax
; 设置 es 段 为 显存地址段
mov ax, 0b800h
mov es, ax
; 设置循环次数
mov cx, 16
mov si, 0 ; 字符的偏移量
mov di, 10*160+80 ; 显存的偏移量
s:
mov al, ds:[si]
mov ah, 2 ; 设置字符的属性 为 2
mov es:[di], ax ; 往显存里面写数据
inc si ; 字符向后偏移 1 位
add di, 2 ; 显存向后偏移 2 位
loop s
mov ax, 4c00h
int 21h
codesg ends
end start运行截图:
实验 9 代码 1:
http://blog.sina.com.cn/s/blog_171daf8e00102xcbv.html
assume cs:codesg
data segment
db 'welcome to masm!'
db 02H,24H,71H ;字符显示的属性值
data ends
stack segment
db 16 dup(0)
; 也可以是下面的定义法:
; dw 8 dup(0)
stack ends
codesg segment
start:
;初始化data数据段,es:di指向data
mov ax, data
mov es, ax
mov di, 0
;初始化显示缓冲区,ds:bx指向显示缓冲区。
mov ax, 0b800H
mov ds, ax
;25行取中是12、13、14行,80列取中开始是61列
;12行的偏移量是12*160=1920 (1行总共80个带属性的字符,即 160个字节)
;总偏移量为(偏移地址)1920+60=1980?
mov bx, 1980
mov si, 16 ;字符的属性在数据段中的偏移量
mov ax, stack ;建栈,并初始化栈顶,熟悉栈结构。其实这里都不用人工建栈,有系统自动的。
mov ss, ax
mov sp, 16 ;指向栈顶
mov cx, 3 ;计数器初始化为3(循环显示3次)
s:
push cx ;入栈保护 CX,在stack中
mov cx, 16 ;内循环为16次,16个字符
output: ;将字符写入显存中
mov al, es:[di]
mov [bx], al
;将字符属性写入显存中
mov ah, es:[si]
mov [bx+1], ah
inc di
add bx, 2
loop output
add bx, 128 ;每行输出的偏移量为128字节
mov di, 0
inc si
pop cx ;出栈恢复cx计数器值
loop s
mov ax,4c00H
int 21H
codesg ends
end start运行截图:

总结:
- 1. 合理利用栈结构保存寄存器变量的值。
- 2. 熟练掌握[bx+idata]这种CPU寻址的方式。
- 3. 在显存中,甚至是内存中,它们都是线性存储的,以列的形式存储的。不存在行的概念的,只不过在计算机屏幕上,还有debug中有行的概念,为了显示方便。
示例代码:
https://www.cnblogs.com/nojacky/p/9497704.html
assume cs:code
data segment
db 'welcome to masm!'
db 02h,24h,71h ; 要求的三个颜色对应的16进制代码
data ends
stack segment
db 16 dup(0)
; 也可以是下面的定义法:
; dw 8 dup(0)
stack ends
code segment
start:
; 设置data段,以及ds:bx指向data段的第一个单元,
; 即ds:[bx]的内容就是data段第一个单元的内容
mov ax,data
mov ds,ax
;设置显示缓存区段
mov ax,0b800h ;设置起始缓存
mov es,ax
;设置栈段
mov ax,stack
mov ss,ax
mov sp,10h ;指向栈顶
;初始化三个寄存器
mov bx,780h ; 行 从12-14行(注意:从第1行开始计数)
mov si,10h ; 颜色的偏移量,三次循环每次
; 增加 1h 指向下一个颜色
mov cx,3 ; 三次循环改变行
s:
mov ah, ds:[si] ;颜色事先存放在ah中
push cx
push si
mov cx, 16 ; 16次循环改变列
mov si, 64 ; 这里的si的意义是多少列,
; 为什么从64列开始呢?
; (1)字符串为32字节,16字节ASCLL码,16字节属性
; (2)每一行有160列,那么余下有 160-32=128列为空白
; 要使得字符串居中显示,那么字符串的左边和右边
; 都应该是64字节(128/2),而列数是从0开始计数,
; 所以左边的64字节为0-63,所以这里偏移量为64
mov di,0
s0:
mov al,ds:[di] ;将date段中的字符一个一个传入es中
mov es:[bx+si],al ; 低位存放字符
mov es:[bx+si+1],ah ; 高位存放颜色
add si,2 ;显示缓存区字符ASCII码偏移量为2
add di,1 ;data段字符的偏移量,每次加 1
loop s0
pop si
pop cx ;后进先出,先出栈si,再出栈cx
add si,1h ;指向下一个颜色
add bx,0a0h ;指向下一行 160=0a0h
loop s
mov ax,4c00h
int 21h
code ends
end start示例代码:
https://www.cnblogs.com/zhenzhenhuang/p/6898813.html
assume cs:code
data segment
db 'welcome to masm!'
db 2,24h,71h
data ends
stack segment
db 16 dup(0)
stack ends
code segment
start:
mov ax,stack
mov ss, ax
mov sp, 16
mov ax,data
mov ds,ax
mov cx,3
mov ax,0B800H
mov es,ax
mov si,10h
mov ax,0
s:
mov ah,ds:[si]
push cx
push si
mov cx,16
mov si,0
add si,160*10+80
mov bx,0
mov di,1
add di,160*10+80
s1:
mov al,[bx]
mov es:[bx+si],al
mov es:[bx+di],ah
inc bx
inc si
inc di
loop s1
pop si
inc si
pop cx
mov dx,es
add dx,0ah
mov es,dx
loop s
finish:
mov ax,4c00h
int 21h
code ends
end start
实验9 代码 2:
http://www.cppblog.com/Tim/archive/2012/06/04/177420.html
datasg segment
;对80*25的屏幕,每行的字节数为80*2=160.
;要求显示在屏幕中间,先计算行和列的偏移
;行偏移:(25-3)/2=11.所以显示在第11,12,13行。偏移值分别为1760,1920,2080。计算方法为 行数*160(每行的字节数) 。
;列偏移:由于要显示的字符数为16个,所以开始显示的列偏移为(80-16)/2*2=64。
dw 1760,1920,2080,64
;要显示的字符 16个
db 'welcome to masm!'
;字符属性:第11行显示绿色字,第12行显示绿底红色,第13行显示白底蓝色
;在全屏模式下能看到字符的闪烁效果
db 82h,0ach,0f9h
datasg ends
codesg segment
assume cs:codesg, ds:datasg
start:
mov ax, datasg ; 设置ds段为datasg数据段
mov ds, ax
mov ax,0b800h ; 设置es段为显存段
mov es,ax
mov cx,3 ; 设置外循环3次
mov di,0
s1: ; 外循环开始, 循环 行
mov ax, di
mov bl, 2
div bl ; 16被除数,ax 的高位是余数,低位是商。
mov si, ax
mov ah, [24+si] ;取颜色属性
mov si, ds:[6] ;列 ,对应 64
mov bp, [di] ;行 ,分别 对应 1760,1920,2080
mov dx, cx
mov bx, 0 ; 遍历每一行的字符
mov cx, 16
s2:
mov al, [bx+8] ;取字符
mov es:[bp+si], al ;写字符
mov es:[bp+si].1, ah ;设置颜色属性
inc bx
add si, 2
loop s2
mov cx,dx
add di,2
loop s1
mov ax, 4c00H
int 21H
codesg ends
end start运行结果截图:

示例代码:
https://www.lscx.org/2718.html
assume cs:codesg,ds:datasg,ss:stacksg
datasg segment
db 'welcome to masm!'
db 82h,0a4h,0f1h
datasg ends
stacksg segment
db 8 dup (0)
stacksg ends
codesg segment
start:
mov ax,datasg
mov ds,ax
mov ax,0B86Eh
mov es,ax
mov cx,3
mov si,0
s1: push cx
mov bx,0
mov bp,0
mov cx,16
s: mov al,ds:[bp]
mov es:[bx].40h,al
mov al,ds:16[si]
mov es:[bx].40h[1],al
inc bp
add bx,2
loop s
pop cx
mov ax,es
add ax,10
mov es,ax
inc si
loop s1
mov ax,4c00h
int 21h
codesg ends
end start
实验9 代码 3:
assume cs:codesg, ds:datasg, ss:stacksg
datasg segment
db "welcome to masm!"
db 2,24h,71h
datasg ends
stacksg segment
db 16 dup(0)
stacksg ends
codesg segment
start:
mov ax,datasg
mov ds,ax
mov si,10h
mov di,1824
mov ax,0b800h
mov es,ax
mov cx,3
s1:
mov bx,0
push cx
mov cx,16
s:
mov al,[bx]
mov ah,[si]
mov WORD ptr es:[di],ax
add bx,1
add di,2
loop s
inc si
add di,128
pop cx
loop s1
all:
jmp short all
mov ax,4c00h
int 21h
codesg ends
end start
实验9 代码4:
https://blog.csdn.net/Ryannn_/article/details/84190330
assume cs:code,ds:data
data segment ;在数据段定义字符串
db 'Welcome to masm!'
data ends
code segment
start:
mov ax,data
mov ds,ax
mov ax,0b800h
mov es,ax ; 使用ds和es寄存器作为段寄存器
mov si,0
mov bx,0
mov bp,07b0h ; 由计算出的字符串所在位置给bp赋值
mov cx,16 ; 16个字符数据故loop16次
s: mov al, [bx] ; 以下采用相对基址变址寻址方式
mov es:[bp+si], al ; 经计算得第1行偏移地址应为b87b0h至b87cfh
mov es:[bp+si+0a0h], al ; 第2行偏移地址应为b8850h至b886fh
mov es:[bp+si+140h], al ; 第3行偏移地址应为b88f0h至b890fh
mov al, 00000010b ; 分别给三行设置属性字节
mov es:[bp+si+1], al
mov al, 00100100b
mov es:[bp+si+0a0h+1], al
mov al, 01110001b
mov es:[bp+si+140h+1], al
inc bx
add si,2 ; 每个字符占2个字节
loop s
mov ah,4ch
int 21h
code ends
end start